Zmiana paradygmatu w sztucznej inteligencji i uczeniu maszynowym
Uczenie federacyjne to rewolucyjne podejście do pozyskiwania danych i szkolenia modeli w uczeniu maszynowym, odchodzące od tradycyjnych metod.
Dzięki zastosowaniu uczenia stowarzyszonego, proces rozwoju uczenia maszynowego staje się bardziej ekonomiczny, a jednocześnie respektuje prywatność danych użytkowników. W niniejszym artykule przyjrzymy się bliżej temu, czym jest uczenie federacyjne, jak przebiega, jakie ma zastosowania oraz jakie są jego struktury.
Czym jest uczenie stowarzyszone?
 Źródło: Wikipedia
Źródło: Wikipedia
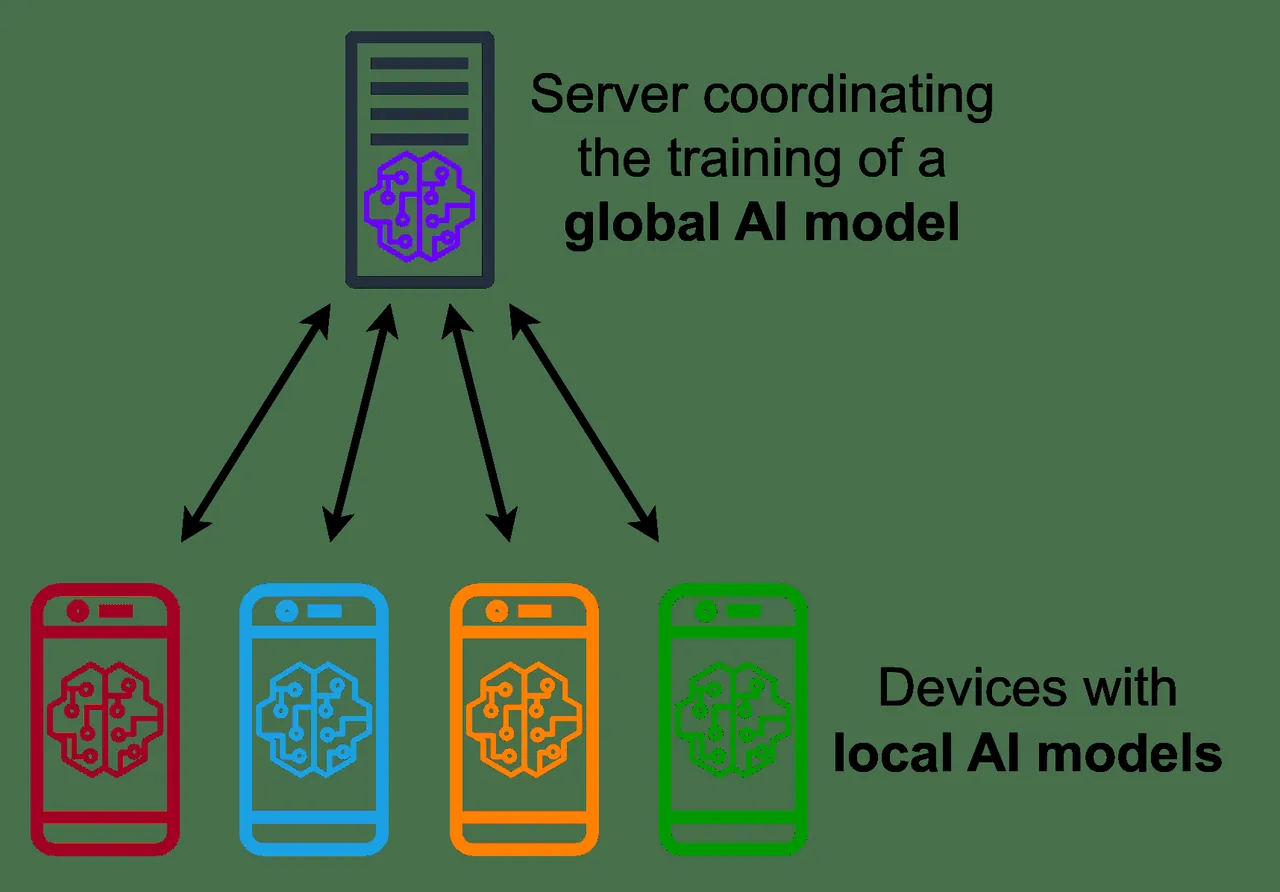
Uczenie federacyjne stanowi przełom w dziedzinie szkolenia modeli uczenia maszynowego. W większości tradycyjnych modeli, dane od różnych klientów są gromadzone w centralnym miejscu. Następnie, na podstawie tego zbioru, trenuje się modele, które służą do dokonywania prognoz. Uczenie federacyjne działa na zasadzie odwrotnej. Zamiast przesyłać dane do centralnego repozytorium, klienci trenują modele bezpośrednio na swoich własnych danych. Takie podejście pomaga im chronić poufność ich prywatnych informacji.
Warto przeczytać: Analiza najlepszych modeli uczenia maszynowego
Jak działa uczenie stowarzyszone?
Proces uczenia w ramach uczenia federacyjnego składa się z serii kroków, które prowadzą do utworzenia finalnego modelu. Te kroki są powtarzane w ramach tzw. rund uczenia, gdzie każda runda przyczynia się do udoskonalenia modelu. Typowa runda uczenia obejmuje następujące etapy:
Typowa runda nauki
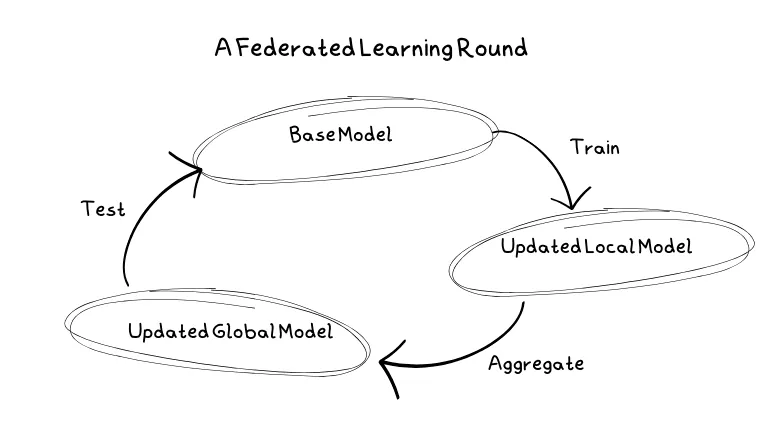
Na początku serwer wybiera model, który ma być trenowany, oraz parametry takie jak liczba rund, wykorzystywane węzły klienckie i ich udział w procesie. W tym momencie model jest inicjowany przy użyciu parametrów startowych, tworząc bazowy model.
Następnie klienci otrzymują kopie bazowego modelu, które trenują na własnych, lokalnych danych. W ten sposób unika się przekazywania wrażliwych danych na serwery. Klientami mogą być urządzenia mobilne, komputery osobiste lub serwery.
Po przeszkoleniu modelu na danych lokalnych, klienci przesyłają go z powrotem na serwer w formie aktualizacji. Serwer odbiera te aktualizacje i uśrednia je wraz z aktualizacjami od innych klientów, tworząc nowy bazowy model. W sytuacjach, gdy klienci są zawodni, niektórzy z nich mogą nie przesłać swoich aktualizacji. Wtedy serwer musi poradzić sobie z takimi sytuacjami.
Zanim nowy model zostanie ponownie wdrożony, konieczne jest jego przetestowanie. Ponieważ serwer nie przechowuje danych, model jest odsyłany do klientów, gdzie jest testowany na ich lokalnych danych. Jeśli nowy model okaże się lepszy od poprzedniego, zostaje przyjęty i zaczyna być stosowany.
Szczegółowy opis działania uczenia federacyjnego przedstawia przewodnik od zespołu ds. uczenia stowarzyszonego w Google AI.
Scentralizowane, sfederowane i heterogeniczne podejścia
W opisanym procesie kluczową rolę odgrywa centralny serwer, który kontroluje cały proces uczenia. Takie rozwiązanie nosi nazwę scentralizowanego uczenia federacyjnego.
Alternatywą dla scentralizowanego uczenia jest zdecentralizowane uczenie federacyjne, gdzie klienci koordynują się nawzajem.
Kolejną konfiguracją jest uczenie heterogeniczne, gdzie klienci mogą pracować na modelach o różnych architekturach.
Zalety uczenia stowarzyszonego
- Podstawową korzyścią z uczenia federacyjnego jest ochrona prywatności danych. Klienci udostępniają wyniki trenowania, a nie same dane wykorzystywane w tym procesie. Dodatkowo, można wdrożyć protokoły agregacji wyników, uniemożliwiające przypisanie wyników konkretnym klientom.
- Zmniejsza się również obciążenie sieci, ponieważ dane nie są przesyłane między klientami a serwerem. Wymieniane są jedynie modele.
- Obniżają się koszty szkolenia modeli, ponieważ nie ma konieczności inwestowania w kosztowny sprzęt. Modele są trenowane na sprzęcie klienta, co dzięki niewielkiej ilości danych, nie obciąża go nadmiernie.
Wady uczenia stowarzyszonego
- Model jest zależny od udziału wielu różnych węzłów, z których część nie jest kontrolowana przez dewelopera. Dostępność tych węzłów nie jest gwarantowana, co czyni proces szkolenia zawodnym.
- Klienci szkolący modele zazwyczaj nie dysponują wydajnymi procesorami graficznymi, a są to standardowe urządzenia jak smartfony. Urządzenia te, nawet po zsumowaniu, mogą mieć niewystarczającą moc obliczeniową w porównaniu z klastrami GPU.
- Uczenie federacyjne zakłada, że wszystkie węzły klienckie są godne zaufania i działają dla wspólnego dobra. Niektórzy klienci mogą nie stosować się do tej zasady i wprowadzać błędne aktualizacje, co prowadzi do odchyleń modelu.
Zastosowania uczenia stowarzyszonego
Uczenie federacyjne umożliwia naukę przy zachowaniu prywatności. Znajduje zastosowanie w wielu dziedzinach, m.in.:
- Podpowiadanie słów na klawiaturach smartfonów.
- Urządzenia IoT, które mogą lokalnie szkolić modele w celu dostosowania ich do konkretnych wymagań.
- Branża farmaceutyczna i opieka zdrowotna.
- Przemysł obronny, gdzie modele można trenować bez udostępniania poufnych informacji.
Frameworki dla uczenia stowarzyszonego
Istnieje wiele frameworków ułatwiających wdrażanie uczenia stowarzyszonego. Do najpopularniejszych należą NVFlare, FATE, Flower i PySft. Szczegółowe porównanie tych frameworków można znaleźć w tym przewodniku.
Podsumowanie
Artykuł ten stanowił wprowadzenie do koncepcji uczenia federacyjnego, wyjaśniając jego działanie, zalety i wady. Przedstawiono również popularne aplikacje oraz frameworki wykorzystywane do wdrożeń w środowisku produkcyjnym.
Zachęcamy również do zapoznania się z artykułem na temat najlepszych platform MLOps do szkolenia modeli uczenia maszynowego.
