
Kiedy mówimy o przetwarzaniu bezserwerowym, wielu zakłada, że w tym modelu nie ma serwera, który ułatwiałby wykonywanie kodu i inne zadania programistyczne. To zwykłe nieporozumienie.
Tak więc, po tym pogromcy mitów, możesz zastanawiać się, jaka jest logika nazwy „bezserwerowy”.
Pozwól, że dam ci wskazówkę: zamiast „brak serwera” oznacza to, JAK serwery są zarządzane i wdrażane, co pociąga za sobą „bezserwerowy”.
Brzmi myląco?
Cóż, dowiemy się wszystkiego o serverless i innych terminach z nim związanych, aby rozwiać Twoje wątpliwości. Po pierwsze, serverless staje się sławny w tej chwili. W rzeczywistości rynek bezserwerowy prawdopodobnie osiągnie 7,7 mld USD do 2021 r z 1,9 mld USD w 2016 r.
Porozmawiajmy więc o bezserwerowym i spróbujmy dowiedzieć się, dlaczego jest tak popularny.
Spis treści:
Co to jest przetwarzanie bezserwerowe?
Przetwarzanie bezserwerowe lub bezserwerowe to oparty na chmurze model wykonania, w którym dostawcy usług w chmurze dostarczają zasoby maszynowe na żądanie i zarządzają serwerami samodzielnie zamiast klientów lub programistów. Jest to sposób, który łączy usługi, strategie i praktyki, aby pomóc programistom w tworzeniu aplikacji w chmurze, pozwalając im skupić się na kodzie, a nie na zarządzaniu serwerem.
Od alokacji zasobów, planowania pojemności, zarządzania, konfiguracji i skalowania po poprawki, aktualizacje, planowanie i konserwację, dostawca usług w chmurze (taki jak AWS lub Google Cloud Platform) bierze na siebie całą odpowiedzialność za zarządzanie typowymi zadaniami związanymi z infrastrukturą. W rezultacie programiści mogą skoncentrować swój wysiłek i czas na logice biznesowej swoich procesów i aplikacji.
Ta bezserwerowa architektura obliczeniowa nigdy nie przechowuje zasobów obliczeniowych w pamięci ulotnej; zamiast tego obliczenia odbywają się w krótkich częściach. Załóżmy, że nie używasz aplikacji, żadne zasoby nie zostaną do niej przydzielone. Dlatego płacisz za zasoby, które faktycznie zużywasz w aplikacjach.
Głównym celem stworzenia modelu serverless jest uproszczenie procesu wdrażania kodu do produkcji. Często działa również z tradycyjnymi stylami, takimi jak mikrousługi. Po wdrożeniu rozwiązania bezserwerowego aplikacje, na których działa, zaczynają szybko reagować na żądania i automatycznie skalować się w górę lub w dół zgodnie z wymaganiami.
Przetwarzanie bezserwerowe wykorzystuje model sterowany zdarzeniami do określania wymagań dotyczących skalowania. W związku z tym programiści nie muszą już przewidywać użycia aplikacji, aby zdecydować, ile serwerów lub przepustowości potrzebują. Możesz zażądać większej liczby serwerów i przepustowości w zależności od rosnących potrzeb bez wcześniejszej rezerwacji lub zmniejszyć skalę w dowolnym momencie bez kłopotów.
Jak ewoluował bezserwerowy?
Tradycyjny system miał wyzwania związane ze skalowalnością i elastycznością w procesie tworzenia i wdrażania aplikacji. Ponieważ zapotrzebowanie na aplikacje wysokiej jakości rosło wraz z krótkim czasem wprowadzania na rynek, pojawiła się potrzeba lepszego systemu, który może oferować większą skalowalność i elastyczność. Doprowadziło to do ewolucji przetwarzania w chmurze i modeli bezserwerowych.
Model bezserwerowy ewoluował na różnych etapach, od monolitu przez mikroserwisy do architektury bezserwerowej lub funkcji jako usługi (FaaS).
- Architektura monolityczna to tradycyjne, ujednolicone podejście do tworzenia oprogramowania. Jest to ściśle powiązany model, w którym każdy komponent i jego podkomponenty kompilują lub wykonują kod. Jeśli usługa jest wadliwa, cały serwer aplikacji i uruchomione na nim usługi mogą przestać działać.
- Architektura mikrousług to zbiór mniejszych usług w dużej, pojedynczej aplikacji wdrażanej niezależnie w celu wykonywania określonej funkcji. Umożliwia szybkie dostarczanie aplikacji na dużą skalę, zapewniając programistom elastyczność przy użyciu infrastruktury jako usługi (IaaS) i platformy jako usługi (PaaS). Jednak w tym modelu wybór między PaaS a IaaS jest trudny.
- Architektura bezserwerowa ewoluowała wraz z przetwarzaniem w chmurze i oferuje większą skalowalność i elastyczność biznesową. Zamiast IaaS i PaaS wykorzystuje FaaS i Backend-as-a-Service (BaaS). Tutaj aplikacje są wdrażane w razie potrzeby wraz z zasobami. Nie musisz zarządzać serwerem i możesz przestać płacić, jeśli zakończy się wykonywanie kodu.
Atrybuty przetwarzania bezserwerowego
Oto niektóre atrybuty przetwarzania bezserwerowego:
- Większość aplikacji wykorzystujących serverless składa się z pojedynczych funkcji i małych jednostek kodu.
- Uruchamia kod tylko na żądanie, zazwyczaj w bezstanowym kontenerze oprogramowania, i płynnie skaluje się w zależności od zapotrzebowania.
- Klienci nie muszą zarządzać serwerem.
- Funkcje wykonywania opartego na zdarzeniach, w którym środowisko komputerowe jest tworzone po uruchomieniu funkcji lub odebraniu zdarzenia w celu wykonania żądania.
- Elastyczna skalowalność, dzięki czemu można łatwo skalować w górę lub w dół. Po wykonaniu kodu infrastruktura przestaje działać, a koszty są oszczędzane. Podobnie, gdy funkcja kontynuuje wykonywanie, możesz skalować w nieskończoność w razie potrzeby.
- Zarządzanych usług w chmurze można używać do obsługi złożonych zadań, takich jak przechowywanie plików, kolejkowanie, bazy danych i nie tylko.
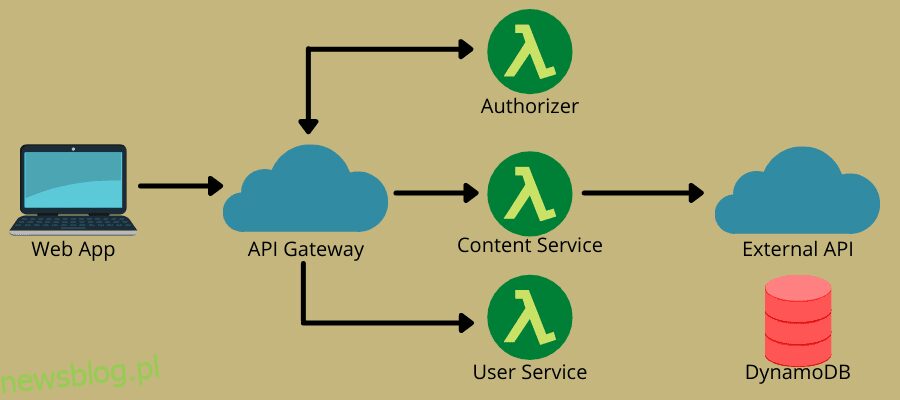
Jak działa bezserwerowy?
Architektura serverless łączy w sobie dwie główne idee – Function-as-a-Service (FaaS) i Backend-as-a-Service (BaaS). Opiera się bardziej na FaaS, który umożliwia usługom w chmurze wykonywanie kodu bez potrzeby posiadania całkowicie aprowizowanych instancji. FaaS składa się z bezstanowych, sterowanych zdarzeniami, skalowalnych funkcji po stronie serwera, którymi w pełni zarządzają usługi w chmurze.
Model umożliwia zespołom DevOps pisanie kodu skupiającego się na ich logice biznesowej. Następnie definiują zdarzenie, które może wyzwolić funkcję, na przykład żądania HTTP, do wykonania. W związku z tym dostawca chmury wykonuje tę funkcję i wysyła wyniki do aplikacji, które użytkownicy mogą przeglądać.
W ten sposób model bezserwerowy zapewnia oszczędność kosztów i wygodę dzięki funkcji automatycznego skalowania, na żądanie i płatności zgodnie z rzeczywistym użyciem. Dlatego wiele firm i zespołów DevOps przechodzi obecnie na serwery.
Kto korzysta z Serverless i dlaczego?
Serverless to jedna z najbardziej rozwijających się technologii w tworzeniu oprogramowania. Może to wyeliminować potrzeby zarządzania infrastrukturą i udostępniania w przyszłości.
Jest to przydatne dla:
- Organizacje pragnące większej skalowalności i elastyczności przy lepszej testowalności aplikacji mogą przejść na rozwiązania bezserwerowe.
- Deweloperzy, którzy chcą skrócić czas wprowadzenia produktu na rynek, tworząc zwinne i wydajne aplikacje
- Firmy, które nie potrzebują, aby ich serwery działały przez cały czas. W razie potrzeby mogą wywoływać funkcje oparte na modułach za pomocą aplikacji, aby obniżyć koszty.
- Organizacje, które chcą tworzyć wydajne aplikacje w chmurze i upraszczać migrację do chmury
- Programiści poszukujący sposobów na zmniejszenie opóźnień mogą oferować użytkownikom dostęp do niektórych funkcji lub aplikacji.
- Firma, która nie ma wystarczających zasobów, aby poradzić sobie z konserwacją i złożonością infrastruktury IT, może przejść na przetwarzanie bezserwerowe, aby automatycznie rozwiązywać problemy i nie wymagać konserwacji od końca.
Niektórzy znani użytkownicy modelu bezserwerowego to Slack, Coca-Cola, NetFlix itp.
Ze względu na swoje unikalne atrybuty model serverless nadaje się do wielu zastosowań, takich jak:
- Aplikacje internetowe: przy użyciu tego modelu można tworzyć szybkie i skalowalne aplikacje internetowe, które szybko reagują na wymagania użytkowników. Jest idealny do tworzenia bezstanowych aplikacji, które można uruchomić natychmiast, oraz aplikacji, które mogą zaspokoić nieprzewidywalne, rzadkie skoki wymagań użytkowników.
- Zaplecze API: na platformach bezserwerowych każdą funkcję można łatwo przekształcić w punkty końcowe HTTP gotowe do użycia przez klientów. Te funkcje lub działania są znane jako działania internetowe, gdy są włączone w Internecie. Po ich włączeniu składanie funkcji w pełnoprawny interfejs API staje się łatwe. Możesz także użyć przyzwoitej bramy API, aby zapewnić większe bezpieczeństwo, obsługę domen, ograniczanie szybkości i obsługę OAuth.
- Mikroserwisy: Serverless jest szeroko stosowany w modelu mikrousług, który koncentruje się na budowaniu małych usług zdolnych do wykonywania jednej funkcji i komunikowania się ze sobą za pomocą interfejsów API.
Chociaż możliwe jest tworzenie mikroserwisów przy użyciu kontenerów oprogramowania i PaaS, bezserwerowe rozwiązanie jest bardziej wydajne. Ułatwia tworzenie mniejszych wierszy kodu, które wykonują jedną czynność i oferuje szybkie udostępnianie, automatyczne skalowanie i elastyczne ceny, które nie obciążają klientów, gdy zasoby nie są używane. - Przetwarzanie danych: bezserwerowe doskonale nadaje się do pracy z danymi zawierającymi filmy, dźwięk, obrazy i tekst strukturalny. Jest również korzystny dla różnych zadań, takich jak sprawdzanie poprawności danych, transformacja, wzbogacanie, oczyszczanie, normalizacja dźwięku i przetwarzanie plików PDF. Możesz go wykorzystać do przetwarzania obrazu, które obejmuje wyostrzanie, obracanie, generowanie miniatur, redukcję szumów. Inne zastosowania bezserwerowego przetwarzania danych to transkodowanie wideo i optyczne rozpoznawanie znaków (OCR).
- Przetwarzanie strumieniowe/wsadowe: Możesz tworzyć wydajne aplikacje do przesyłania strumieniowego i potoki danych przy użyciu FaaS i bazy danych z Apache Kafka. Model bezserwerowy pasuje do różnych procesów pozyskiwania strumieni, w tym danych do dzienników aplikacji, czujników IoT, logiki biznesowej i rynku finansowego.
- Obliczenia równoległe: Serverless doskonale nadaje się do zadań związanych z obliczeniami równoległymi, w których każde zadanie jest wykonywane równolegle w celu wykonania określonego zadania. Może obejmować wyszukiwanie danych, przetwarzanie, operacje na mapach, skrobanie sieci, przetwarzanie genomu, dostrajanie hiperparametrów itp.
- Inne zastosowania: Serverless jest również używany w różnych aplikacjach, takich jak zarządzanie relacjami z klientami (CRM), finanse, chatboty oraz Business Intelligence i analityka, by wymienić tylko kilka.
Uwaga: tryb bezserwerowy może nie być idealny w niektórych przypadkach. Na przykład duże aplikacje z przewidywalnymi i prawie stałymi obciążeniami mogą bardziej skorzystać na tradycyjnej architekturze systemu. Mogą zdecydować się na serwery dedykowane, zarządzane lub samodzielnie zarządzane. Ponadto, jeśli Twoja organizacja ma kompletne tradycyjne konfiguracje ze starszymi systemami i aplikacjami, przejście na zupełnie nową i inną architekturę może być kosztowne i trudne.
Zalety i wady przetwarzania bezserwerowego
Każda moneta ma dwie strony, podobnie jak architektura bezserwerowa. Ma również pewne zalety i wady oparte na różnych parametrach. Tak więc, zanim przejdziesz dalej, ważne jest, aby poznać obie strony, aby zdecydować, czy byłoby to lepsze dla Twojej organizacji, czy nie.
Zalety 👍
Oto niektóre zalety architektury bezserwerowej:
Opłacalny
Serverless może oferować większą efektywność kosztową niż kupowanie lub wynajmowanie serwerów, w których płacisz za zasoby, nawet jeśli ich nie używasz.
Serverless wykorzystuje model pay-as-you-go, w którym płacisz tylko za zużyte zasoby. Dostawca bezserwerowy obciąży Cię tylko za przydzieloną pamięć i czas na uruchomienie kodu bez ponoszenia kosztów za czas bezczynności.
W rezultacie zaoszczędzisz na kosztach operacyjnych związanych z zadaniami takimi jak instalacja, licencje, konserwacja, patchowanie, wsparcie itp. Bez sprzętu serwerowego oszczędzasz na kosztach pracy.
Skalowalność
Systemy bezserwerowe oferują wysoki poziom skalowalności, ponieważ możesz skalować w górę lub w dół, kiedy tylko chcesz, w zależności od wymagań. Z tego powodu nazywane są również „elastycznymi”.
W tym przypadku programiści nie potrzebują poświęcanego czasu na ustawianie systemów lub zasad automatycznego skalowania ani ich dostrajanie. Wybrany dostawca usług w chmurze jest odpowiedzialny za zarządzanie tym wszystkim. Ponadto programiści z małych zespołów mogą również samodzielnie uruchamiać swój kod bez konieczności korzystania z inżynierów pomocy technicznej lub infrastruktury.
Zmniejszone opóźnienie
Ponieważ aplikacje nie są hostowane na jednym serwerze źródłowym, możesz uruchomić kod z dowolnego miejsca. Jeśli wybrany przez Ciebie dostawca chmury to obsługuje, możesz uruchamiać funkcje aplikacji na serwerze blisko użytkowników końcowych. W związku z tym powoduje mniejsze opóźnienia ze względu na zmniejszoną odległość między żądaniami użytkownika a serwerem.
Wydajność
Model bezserwerowy pomaga zwiększyć produktywność programistów, ponieważ nie muszą oni zajmować się zarządzaniem serwerem. Ponadto nie muszą myśleć o zarządzaniu żądaniami HTTP lub wielowątkowością bezpośrednio w swoim kodzie.
W rezultacie upraszcza tworzenie backendu, a wszystko to dzięki FaaS, gdzie odsłonięty kod to funkcje sterowane zdarzeniami. Wszystko to oszczędza czas, który można poświęcić na ulepszanie kodu i aplikacji.
Szybsze wdrażanie aplikacji
W przypadku rozwiązania bezserwerowego programiści nie wykonują konfiguracji zaplecza ani nie przesyłają kodu na serwer w celu wdrożenia wersji aplikacji. Mogą również szybko przesłać kod w bitach, aby wypuścić nowe produkty.
Mają także elastyczność wdrażania kodu od razu lub działania jeden po drugim, ponieważ nie jest to architektura monolityczna. Ponadto możesz szybko łatać, aktualizować, dodawać funkcje lub naprawiać błędy z poziomu aplikacji.
Inne korzyści obejmują ekologiczne przetwarzanie dzięki zmniejszonemu zużyciu energii dzięki serwerom na żądanie, łatwiejsze tworzenie aplikacji dzięki wbudowanym integracjom, krótszy czas wprowadzania na rynek i nie tylko.
Wady 👎
Przyjrzyjmy się teraz wadom przetwarzania bezserwerowego:
Wydajność
Czasami rzadziej używany kod bezserwerowy może wykazywać większe opóźnienia odpowiedzi niż kod działający nieprzerwanie na serwerach dedykowanych, kontenerach oprogramowania lub maszynach wirtualnych (VM). To dlatego, że może potrzebować więcej czasu, aby zacząć od nowa i stworzyć dodatkowe opóźnienie.
Trudne do debugowania i testowania
Musisz wiedzieć, jak działa Twój kod po jego wdrożeniu. W tym celu musisz go przetestować, co jest trudne w środowisku bezserwerowym. Ponadto, ponieważ programiści nie mają wglądu w każdy proces zaplecza, a aplikacje są podzielone na mniejsze funkcje, debugowanie staje się skomplikowane.
Problemy z bezpieczeństwem
Rośnie liczba nowych i zaawansowanych problemów związanych z cyberbezpieczeństwem. Nie jest jednak możliwe pełne poznanie ani zmierzenie bezpieczeństwa dostawcy usług w chmurze. Tak więc, gdy zajmują się całym zapleczem z poufnymi danymi przechowywanymi w aplikacjach, jest to ryzykowne.
Nie nadaje się do długotrwałych procesów aplikacji
Serverless jest opłacalny, ale nie dla wszystkich typów aplikacji. Jeśli masz aplikację z długotrwałymi procesami, koszt jej uruchomienia w oparciu o czas i przydzielone zasoby może być bardzo wysoki. W tej chwili możesz chcieć skorzystać z hostingu serwera dedykowanego.
Inne wady rozwiązania bezserwerowego to trudności w przechodzeniu od jednego dostawcy do drugiego oraz problemy z prywatnością.
Terminologie ważne w architekturze bezserwerowej
Serverless nigdy nie jest kompletny bez omówienia niektórych kluczowych terminologii z nim związanych. FaaS i BaaS to dwie najbardziej znane idee, które doprowadziły do ewolucji technologii serverless, jaką znamy dzisiaj. Aby zbudować system bezserwerowy, potrzebujesz bazy danych, systemu pamięci masowej, stosu technologii, struktury i tak dalej. Porozmawiajmy więc trochę o nich.
Funkcja jako usługa (FaaS)
FaaS jest główną ideą w bezserwerowym i działa jak jego podzbiór. Ten sterowany zdarzeniami model wykonywania kodu (aplikacje uruchamiane w odpowiedzi na żądanie) umożliwia pisanie logiki wdrożonej w kontenerach oprogramowania, wykonywanej na żądanie i zarządzanej przez platformę chmurową.
Jeśli porównasz to do BaaS, FaaS oferuje programistom większą kontrolę nad tworzeniem niestandardowych aplikacji, zamiast polegać na bibliotekach zawierających gotowy kod.
Kontenery oprogramowania, w których wdrażany jest kod, są bezstanowe, aby uprościć integrację danych, a kod działa krócej. Ponadto programiści mogą wywoływać aplikacje bezserwerowe za pośrednictwem interfejsów API przy użyciu FaaS, którymi dostawcy chmury zarządzają za pośrednictwem interfejsu API Gateway.
Backend jako usługa (BaaS)
BaaS jest podobny do FaaS, ponieważ oba wymagają usługodawcy zewnętrznego. W tym modelu dostawca chmury zapewnia usługi zaplecza, takie jak przechowywanie danych, aby pomóc programistom skupić się na pisaniu kodu frontendu. Jednak aplikacje BaaS mogą nie być sterowane zdarzeniami ani działać na brzegu, jak w przypadku aplikacji bezserwerowych.
Dobrym przykładem BaaS jest AWS Lambda. Deweloperzy używają kodu bezserwerowego w kontenerach z Lambdą, która zapewnia wytyczne, których należy przestrzegać podczas przesyłania kodu. Automatyzuje również procesy wprowadzania kodu do kontenerów oprogramowania i oferuje usługę zarządzaną.
Stos bezserwerowy
Podobnie jak w przypadku innych technologii oprogramowania, architektura bezserwerowa jest również wyposażona w stos technologiczny. Łączy w sobie różne komponenty niezbędne do stworzenia bezserwerowego systemu lub aplikacji.
Stos bezserwerowy obejmuje:
- Język programowania: język programowania, w którym programiści napiszą kod. W zależności od dostawcy możesz wybierać spośród Java, JavaScript, Python, C#, Go, Node.js, F# itp.
- Framework bezserwerowy: Framework zapewnia szkielet lub strukturę kodu. Istnieje wiele frameworków bezserwerowych, dzięki którym możesz zacząć. Umożliwia budowanie, pakowanie i kompilowanie kodu, a wreszcie wdrożenie w chmurze. Struktury bezserwerowe przyspieszają proces kodowania i upraszczają skalowanie dzięki skróceniu czasu konfiguracji. Przykładami frameworków serwerowych są Apex, AWS Serverless Application Model itp.
- Bezserwerowe bazy danych: służą do przechowywania danych, do których dostęp wymaga kod. Są one również potrzebne do interakcji z funkcjami dla wyzwalaczy. Te bazy danych zachowują się jak funkcje bezserwerowe, ale przechowują dane w nieskończoność. Przykładami bezserwerowych baz danych są DynamoDB, Azure Cosmos DB, Aurora Serverless i Cloud Firestore.
- Zestaw wyzwalaczy: pomagają rozpocząć wykonywanie kodu, podobnie jak żądania HTTP
- Kontenery oprogramowania: wzmacniają model bezserwerowy i oferują kontenerowe mikrousługi bez złożoności. Działają również jako repozytorium Twojego kodu i ułatwiają programistom pisanie kodu dla wielu platform, takich jak komputer stacjonarny lub iOS.
- Bramy API: Działają jako proxy dla akcji internetowych. Oferują routing HTTP, limity szybkości, przeglądanie dzienników użycia i odpowiedzi API, identyfikator klienta itp.
Jak wdrożyć model Serverless i zoptymalizować go?
Przejście na tryb bezserwerowy pociągnie za sobą znaczące zmiany w aplikacjach, technologii, kosztach, bezpieczeństwie i korzyściach.
Załóżmy, że jesteś start-upem lub małą firmą. W takim przypadku przyspieszy to czas wprowadzenia produktu na rynek i pomoże w szybkim wprowadzaniu aktualizacji dzięki uproszczonemu testowaniu, debugowaniu, zbieraniu opinii, pracy nad problemami i nie tylko w celu zaoferowania użytkownikom dopracowanej aplikacji.
Jeśli reprezentujesz większą organizację, odczujesz korzyści, takie jak większa skalowalność, aby spełnić wymagania użytkowników, ale będzie to wymagało znacznych inwestycji kosztowych.
Dlatego najlepiej jest ocenić zalety i wady rozwiązania bezserwerowego specjalnie dla rodzaju Twojej firmy i wymagań, a następnie kontynuować. A jeśli myślisz o tym poważnie, zacznij od:
- Zrozumienie Twoich potrzeb i określenie odpowiedniego stosu technologii bezserwerowych
- Wybierz dostawcę bezserwerowego, takiego jak Google Cloud Functions, Azure Functions, AWS Lambda itp.
- Wzmocnij swój zespół dzięki potężnym narzędziom do monitorowania wydajności i funkcji systemu. Uważaj na całkowitą liczbę żądań, ograniczenia, liczbę błędów, wskaźniki sukcesu, czas trwania żądania i opóźnienie.
Dostawcy bezserwerowi

Na rynku jest wielu dostawców usług bezserwerowych lub dostawców usług w chmurze, spośród których możesz wybierać. Niektóre z najlepszych to:
- AWS Lambda: jest idealny dla organizacji, które już korzystają z usług AWS. Integruje się z szeroką gamą usług do przechowywania, przesyłania strumieniowego i baz danych.
- Microsoft Azure Functions: jeśli używasz Visual Studio Code, śmiało. Działa płynnie z DevOps i Azure Pipelines dla CI/CD. Obsługuje również Durable Functions dla funkcji stanowych i oferuje zintegrowane monitorowanie.
- Funkcje Google Cloud: jeśli korzystasz z usług Google, to dobrze. Obsługuje aplikacje JS, Go i Python, umożliwia uruchamianie funkcji z asystenta Google lub GCP i oferuje wbudowane skalowanie.
- IBM Cloud Functions: jeśli chcesz przejść na model bezserwerowy oparty na Apache OpenWhisk, IBM Cloud Functions jest dla Ciebie. Obejmuje doskonałe monitorowanie wydajności, wyzwalanie zdarzeń z interfejsu API REST lub usług chmurowych IBM oraz integruje się z bramą IBM API Gateway w celu zarządzania punktami końcowymi.
- Knative: Jeśli korzystasz z usług na Kubernetes, śmiało. Jest wspierany przez Google, Red Hat, IBM itp.
- Cloudflare Workers: Jest dobry dla aplikacji wymagających wysokiej responsywności, zwłaszcza aplikacji JavaScript. Obsługuje Workers KV do przechowywania danych i WebAssembly, aby pomóc w kompilacji i dostarczaniu wielu języków. Ponadto jego rozbudowana sieć dystrybucyjna ze 193 centrami danych poprawia opóźnienia i szybkość reakcji.
Wniosek: przyszłość technologii bezserwerowych
Przetwarzanie bezserwerowe ewoluuje wraz z rosnącym zapotrzebowaniem na wysoce skalowalne aplikacje. Zapewnia również wiele korzyści, które oferuje przetwarzanie w chmurze, takie jak większa wygoda, efektywność kosztowa, wyższa produktywność i nie tylko.
według an Ankieta O’Reilly’ego40% respondentów pracuje w firmach, które przyjęły architekturę bezserwerową.
Chociaż rozwiązania serverless nadal budzą pewne obawy, takie jak opóźnienia spowodowane zimnym startem, testowaniem, debugowaniem itp., dostawcy usług w chmurze pracują nad nimi. Wkrótce może pojawić się bardziej wyrafinowana forma bezserwerowa z większą liczbą korzyści i rozwiązanymi problemami. W związku z tym oczekuje się, że popularność i wykorzystanie modelu bezserwerowego wzrośnie w przyszłości.
Może Cię również zainteresować: Siedem sposobów, w jakie przetwarzanie bezserwerowe jest technologią wschodzącą