

Oprogramowanie do monitorowania infrastruktury IT zapewnia firmom scentralizowaną platformę do monitorowania całej infrastruktury IT, co jest jedną z jego najbardziej niesamowitych zalet.
Oprócz przyspieszenia procedury monitorowania zapewnia cenne informacje na temat wydajności systemu, pomagając firmom w podejmowaniu decyzji i zapobieganiu potencjalnym problemom.
Spis treści:
Przegląd oprogramowania monitorującego
Oprogramowanie do monitorowania infrastruktury IT staje się coraz bardziej niezbędne w dzisiejszym świecie napędzanym technologią, w którym wydajność i niezawodność systemu mają kluczowe znaczenie dla wszystkich typów firm, niezależnie od ich wielkości.
Ręczne śledzenie sieci komputerowych SMB i dużych sieci komputerowych przy jednoczesnym zapewnieniu płynnego i bezpiecznego działania jest wyzwaniem, dlatego oprogramowanie do monitorowania infrastruktury IT pojawia się, aby sprostać temu wyzwaniu.
Narzędzia te są dobrze wyposażone i niedrogie w monitorowaniu kondycji, wydajności i dostępności infrastruktury IT w czasie rzeczywistym. Administratorzy mogą łatwo śledzić problemy, zanim staną się one problemami, monitorując, analizując i ostrzegając elementy sieci i systemu za pomocą takich narzędzi.
Dynamiczne środowisko IT wymaga odpowiedniego monitorowania, dostępności i bezpieczeństwa, aby zapewnić bezproblemowe działanie. Takie narzędzia zwiększają nawet możliwości zespołów DevOps, zapewniając im większą elastyczność i skalowalność w monitorowaniu kondycji całego stosu technologii.
Ponieważ potrzeby IT i infrastruktura różnią się w zależności od firmy, a dostępne są różne płatne i otwarte narzędzia, trudno byłoby wybrać odpowiednie dla swojej infrastruktury.
W poniższej sekcji omówiliśmy najlepsze narzędzia do monitorowania typu open source wraz z ich funkcjami. Pomoże Ci zrozumieć, jak działają te narzędzia i które będą pasować do Twojej infrastruktury.
Nagios
Nagios monitoruje całą Twoją infrastrukturę IT, szybko sortuje dane dziennika lub analizuje przepustowość. Dzięki niezawodnym rozwiązaniom do gromadzenia danych, analizy NetFlow i monitorowania infrastruktury IT, Nagios pomaga firmom na całym świecie w podejmowaniu mądrzejszych decyzji biznesowych.
Nagios zaufało ponad 9000 najlepszych klientów, takich jak Airbnb, Cisco i Paypal.

Nagios, renomowane rozwiązanie do monitorowania infrastruktury IT, oferuje różne produkty i usługi do pobrania dla małych i średnich przedsiębiorstw oraz dla dużych przedsiębiorstw.
Platforma służy jako wszechstronne źródło zaspokajające szeroki zakres wymagań, od monitorowania serwerów i aplikacji po zapewnianie wglądu w sieć i praktycznych informacji. Jego wykonalność zapewnia bezproblemową integrację z istniejącymi systemami.
Cechy
- Dostępnych jest ponad pięć tysięcy różnych dodatków do monitorowania serwerów.
- Sprawdza sieć pod kątem problemów spowodowanych przeciążonymi połączeniami sieciowymi lub liniami danych.
- Monitoruje aplikacje Windows, Linux, UNIX i Web.
- Skonfiguruj alerty, aby powiadamiać Cię o pojawieniu się potencjalnych zagrożeń.
Firmy każdej wielkości mogą uzyskać dostęp do różnych pakietów oprogramowania Nagios, takich jak Nagios Core, Nagios XI, Nagios Fusion i Nagios Log Server. Podstawowy silnik Nagios XI służy do szybkiego monitorowania infrastruktury IT. Jego serwer logów służy do szybkiego przeglądania, analizowania i archiwizowania logów z dowolnego źródła w jednej centralnej lokalizacji.
Przepustowość sieci jest śledzona za pomocą analizatora sieci. Nagios Fusion zapewnia scentralizowany widok statusu operacyjnego i umożliwia szybsze rozwiązywanie problemów w całej sieci.
Możesz wypróbować dowolne z naszych rozwiązań za darmo przez 30 dni bez żadnych ograniczeń. Nagios ma zarówno wersje płatne, jak i open-source, i można je pobrać w zależności od potrzeb organizacyjnych.
Zabbix
Zabbix to wielokrotnie nagradzane, profesjonalnie opracowane oprogramowanie typu open source bez ograniczeń i ukrytych kosztów. Jest to kompleksowe i szeroko stosowane rozwiązanie do monitorowania, umożliwiające firmom i organizacjom śledzenie ich sieci, sprzętu i infrastruktury.
Wszechstronność platformy obejmuje monitorowanie sieci, serwerów, chmur, aplikacji, usług, a nawet całych centrów danych.

Zaufały mu czołowe światowe organizacje, takie jak Dell, ICANN, T-systems itp. Łatwa integracja z różnymi systemami i rozszerzalna architektura sprawiają, że jest to popularny wybór wśród specjalistów IT na całym świecie.
Dzięki szerokiej gamie funkcji i możliwości, Zabbix oferuje naprawdę solidne doświadczenie w zakresie monitorowania, które zaspokaja różne potrzeby użytkowników.
Zabbix pozwala administratorom identyfikować i rozwiązywać krytyczne problemy oraz upraszcza zadanie utrzymania wydajności w różnych systemach dzięki analizie danych w czasie rzeczywistym, łatwym w użyciu pulpitom nawigacyjnym i dostosowywanym alertom.
Cechy
- Gotowe do użycia szablony do integracji instalacji Zabbix z systemami alertów, zgłoszeń, IoT i ITSM.
- Zdefiniuj progi, aby natychmiast wykrywać problemy.
- Uzyskaj dodatkowe informacje i rozszerz możliwości obserwacji dzięki zaawansowanej wizualizacji danych.
- Śledź kluczowe wskaźniki wydajności dzięki monitorowaniu usług biznesowych.
- Bezpieczeństwo klasy korporacyjnej.
Alexei Vladishev stworzył platformę w 2001 roku, aby zapewnić firmom i profesjonalistom IT wszechstronne i przyjazne dla użytkownika rozwiązanie do ich potrzeb w zakresie monitorowania. Podstawowym celem platformy jest zapewnienie niezawodnego i wydajnego systemu monitorowania, zapewniającego stabilność i bezpieczeństwo infrastruktury biznesowej.
Zaznacz
Checkmk jest przeznaczony do monitorowania całej hybrydowej infrastruktury IT obejmującej serwery, sieci i aplikacje. Bazy danych, chmury, kontenery, pamięć masowa, IoT itp. Zgodnie z witryną zaufały jej Adobe, Fitbit, NHL, Labcorp, Groupon itp.

Jego najnowsza wersja 2.1 zawiera ulepszony monitoring Kubernetes, więcej integracji z otwartym ekosystemem obserwowalności, lepszą wydajność i wiele więcej.
Ma dwie edycje – Raw, która jest open source, a druga to Enterprise, która jest premium z większą liczbą funkcji, ale jest płatna.
Obsługuje również automatyczne wykrywanie sieci i prowadzi inwentaryzację sprzętu i oprogramowania. Jeśli chodzi o monitorowanie, edycja Raw obsługuje monitorowanie stanu serwerów, sieci i aplikacji.
Aby rozszerzyć skalowalność i funkcjonalność, obsługuje ponad 2000 wtyczek. Oprócz tego zapewnia również interfejs API do pisania własnych wtyczek.
Oprogramowanie Checkmk jest w stanie monitorować i zarządzać złożonymi i hybrydowymi środowiskami IT oraz jest łatwe do wdrożenia i użytkowania.
Najlepsze funkcje
- Automatycznie wykrywa problemy i wysyła alert.
- Integracja ze Slackiem, PagerDuty, SIGNL4 i VictorOps.
- Wykresy szeregów czasowych i integracja Grafany.
- Scentralizowane zarządzanie alertami dla środowisk rozproszonych.
Jeśli szukasz jednego scentralizowanego pulpitu nawigacyjnego do monitorowania, zarządzania i administrowania kompleksową hybrydową infrastrukturą IT, Checkmk zapewni rozwiązania. Wersja Raw jest bezpłatna, a jeśli potrzebujesz dodatkowych funkcji, możesz przełączyć się na wersję Enterprise.
Prometeusz i Grafana
Prometheus i Grafana to szeroko stosowane narzędzia typu open source do monitorowania infrastruktury IT. Prometheus jest w 100% narzędziem typu open source, a jego rozwój jest wspierany przez Grafana w zakresie ulepszania funkcji, aby pomóc zarówno klientom Grafana, jak i Prometheus.

Prometheus to zestaw narzędzi do monitorowania i ostrzegania, a Grafana to oparty na chmurze system, który pomaga wizualizować metryki Prometheusa na wykresach i pulpitach nawigacyjnych. Tak więc oba narzędzia pozwalają użytkownikom przechowywać duże ilości metryk, które mogą łatwo podzielić i rozbić, aby zrozumieć, jak działa ich infrastruktura.
System monitorowania Prometheus zawiera wielowymiarowy model danych i potężny język zapytań o nazwie PromQL, który zbiera i przechowuje swoje metryki jako dane szeregów czasowych. Grafana to stos IoT do monitorowania i wizualizacji wszystkich metryk danych w jednym panelu operacyjnego pulpitu nawigacyjnego.
Grafana jest używana przez ponad 10 milionów użytkowników na całym świecie, w szczególności przez duże korporacje.
Najważniejsze cechy Grafany
- Centralizacja analizy, wizualizacji i alertów dotyczących metryk Prometheus za pomocą pulpitów nawigacyjnych Grafana.
- Eksploruj, wizualizuj, wysyłaj zapytania i ostrzegaj o swoich metrykach Datadog w Grafana Cloud.
- Scentralizowana, skalowalna poziomo, zreplikowana architektura pomaga w utrzymaniu Prometheusa.
- Najlepsza w swojej klasie wydajność zapytań do tworzenia pulpitów nawigacyjnych w czasie rzeczywistym do udostępniania w całej organizacji.
- Solidne zasady dostępu do danych w celu zabezpieczenia danych i zarządzania nimi.
Najważniejsze cechy Prometeusza
- Alerty są oparte na Prometheus PromQL, a menedżer alertów obsługuje powiadomienia.
- Przechowuje szeregi czasowe w pamięci i na dysku lokalnym w wydajnym formacie
- Różne integracje do łączenia danych stron trzecich
- Biblioteki niestandardowe są łatwe do wdrożenia i obsługiwanych jest ponad dziesięć języków.
Prometheus i Grafana to standardy monitorowania usług i aplikacji. Metryki Prometheus są gromadzone i wczytywane do Grafana Cloud. Prometheus to narzędzie typu open source, podczas gdy Grafana jest bezpłatna na zawsze dla trzech użytkowników z ograniczonymi wskaźnikami.
Jeśli chcesz korzystać z funkcji premium i nieograniczonych wskaźników, możesz zarejestrować się w Grafana Pro, która ma 14-dniowy okres próbny.
kaktusy
Cacti to solidne narzędzie do monitorowania i zarządzania błędami typu open source, zaprojektowane w celu zapewnienia kompleksowych rozwiązań monitorowania od sieci LAN po złożone systemy sieciowe.
Może skalować się od kilku do tysięcy hostów w celu gromadzenia, analizowania i wizualizacji wydajności urządzeń i aplikacji sieciowych.
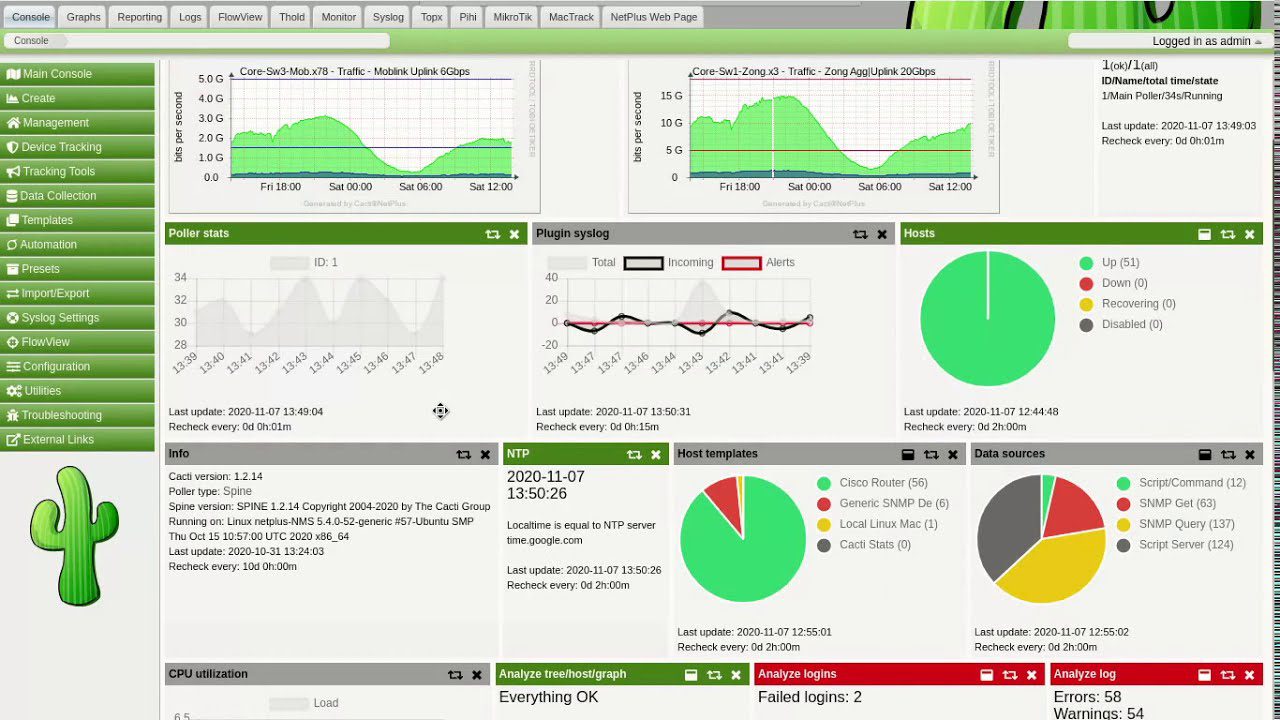
Jej podstawowe usługi mogą być wdrażane za systemami równoważenia obciążenia, przy czym zarządzanie sesjami pochodzi z bazy danych, a strukturalna baza danych jest wdrażana w sposób w pełni odporny na awarie.
Jest szeroko stosowany wśród administratorów sieci i inżynierów, którzy chcą uprościć swoje codzienne czynności związane z monitorowaniem i zapewnić wydajne działanie sieci.
Skuteczna wizualizacja danych za pomocą intuicyjnych wykresów pomaga specjalistom IT uchwycić ogólną wydajność sieci za pośrednictwem różnych urządzeń sieciowych.
Pomaga nie tylko monitorować urządzenia sieciowe i aplikacje, ale także pomaga wykrywać i rozwiązywać problemy z wydajnością, aby zapobiegać problemom w przyszłości.
Cechy
- Wykorzystuje dowolną metodologię gromadzenia danych do automatycznego tworzenia wykresów wydajności.
- Obsługuje pliki RRD (Round-Robin Database) z więcej niż jednym źródłem danych, a także może używać pliku RRD przechowywanego w dowolnym miejscu w lokalnym systemie plików.
- Szablony i pakiety do obsługi dużej liczby źródeł danych i wykresów.
- Integracja z połączeniami danych MySQL/MariaDB w celu obsługi offline bazy danych Cacti
- Automatyczne wykrywanie urządzeń sieciowych.
Jego elastyczny interfejs i możliwości pozwalają małym i średnim firmom oraz dużym korporacjom wspierać szybkie wykrywanie problemów z wydajnością i podejmować przemyślane decyzje w kontekście dzisiejszej, coraz bardziej złożonej infrastruktury IT.
Ta bezpłatna platforma obsługuje również wtyczki i dodatki, które umożliwiają administratorom zwiększenie możliwości narzędzia.
OpenNMS
OpenNMS Meridian to działająca w chmurze, wysoce skalowalna platforma zarządzania siecią typu open source dla sieci lokalnych i zdalnych.
Jest to kompletne rozwiązanie do monitorowania wydajności i zarządzania siecią biznesową w zakresie monitorowania sieci, analizy ruchu sieciowego, wykrywania sieci i ostrzegania, kompleksowego zarządzania awariami, generowania alarmów itp.
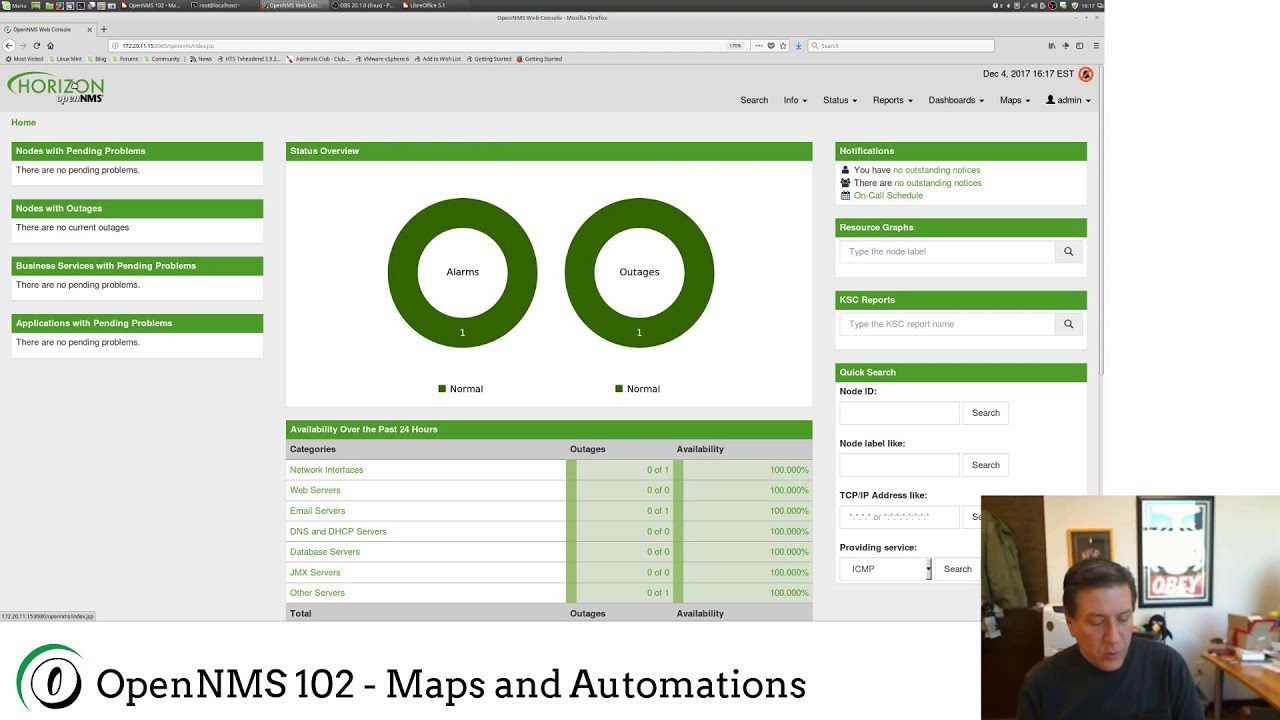
Jest stosowany w prawie każdym sektorze, w tym w służbie zdrowia, technologii, energetyce, finansach, administracji, edukacji, handlu detalicznym itp., do monitorowania i zarządzania tysiącami urządzeń sieciowych.
Nadaje się do obsługi małych i średnich przedsiębiorstw do dużych przedsiębiorstw, może obsłużyć do 300 000 punktów danych na sekundę z przepływami i jest skalowalny, aby obsłużyć więcej.
OpenNMS jest dostępny w dwóch dystrybucjach typu open source: Horizon i Meridian. Horizon to wydanie społecznościowe, a Meridian to wydanie korporacyjne. Oprócz tych dwóch, OpenNMS zapewnia tworzenie niestandardowych wykresów za pomocą Helm i ramy, która wykorzystuje sztuczną inteligencję (AI) do grupowania powiązanych alarmów sieciowych w celu lepszego rozwiązywania problemów.
Jest wystarczająco wszechstronny, aby obsługiwać czternaście protokołów gromadzenia danych, więc nie ma potrzeby stosowania narzędzi innych firm. Wszystkie te protokoły pomagają w niestandardowym ustalaniu wartości progowych w czasie rzeczywistym, analizie trendów, prognozowaniu, analizie danych dotyczących wydajności szeregów czasowych, kreśleniu wizualnym i prognozowaniu operacyjnym w czasie rzeczywistym.
OpenNMS uzyskuje bardziej szczegółowe dane o Twojej sieci, które pomagają przewidywać potencjalne problemy poprzez śledzenie zmian w urządzeniach sieciowych i konfiguracjach. Jest znacznie łatwiejszy w utrzymaniu i użytkowaniu bez irytujących szybkich aktualizacji i wydań.
Cechy
- Zarządzanie zapasami i usterkami.
- Zarządzanie ruchem sieciowym.
- Monitorowanie perspektywy aplikacji.
- Obsługa monitorowania protokołu Border Gateway do zaawansowanego monitorowania i zarządzania urządzeniami trasującymi.
- Zarządzanie alarmami i zdarzeniami.
- Powiadomienia w czasie rzeczywistym dla odpowiedzi o wysokim priorytecie.
- Konfigurowalne dashboardy Grafana.
- Przedsiębiorcza wizualizacja sieci w postaci wykresów zasobów, raportów baz danych, wykresów itp.
Jeśli chcesz skupić się na swoich podstawowych działaniach, a nie na czasochłonnym monitorowaniu i konserwacji, OpenNMS pomoże Ci we wszystkim, od zbierania danych, przez ocenę, po praktyczne spostrzeżenia i wizualizacje.
Jest to kompletne rozwiązanie do monitorowania wydajności sieci biznesowej oraz zapewniania wydajności i dostępności ważnych usług sieciowych.
Icinga
Icinga może monitorować rozległe, złożone ekosystemy w wielu lokalizacjach, ponieważ jest skalowalna i elastyczna. Icinga to system monitorowania dostępności zasobów sieciowych, który również ostrzega użytkowników o zakłóceniach i gromadzi statystyki wydajności do celów raportowania.
Największe firmy na świecie, takie jak Adobe, Audi, Vodafone, puppet i inne, ufają Icinga.

Element monitorujący stosu Icinga jest tylko jeden. Inne zalety rozwiązania to terminowe powiadomienia, wnikliwe wizualizacje i analizy, automatyzacja zadań oraz łatwa integracja z innymi systemami.
Skalowalny system monitorowania monitoruje wszystkie odmiany infrastruktury chmurowej. Dzięki powiązaniu z istniejącymi narzędziami, takimi jak Graphite, Ansible, InfluxDB, Grafana, AWS, Jira, Azure, ServiceNow i wieloma innymi, możesz projektować rozwiązania monitorujące dostosowane do konkretnych wymagań.
Platforma może łatwo rozrosnąć się z małej infrastruktury do dużych sieci wielodostępnych.
Cechy
- Scentralizowana konsola do monitorowania infrastruktury.
- Zarządzanie dostępem oparte na rolach, połączenia szyfrowane SSL i klastry o wysokiej dostępności zapewniające nieprzerwaną dostępność.
- Automatyzacja powtarzających się zadań.
- Kompleksowe raporty oparte na metrykach, logach, wzorcach i powiadomieniach opartych na progach.
Icinga to rozwiązanie gotowe do zastosowania w przedsiębiorstwie, które pozwala monitorować różnorodne spektrum tablic, w tym urządzenia, bazy danych, aplikacje, usługi w chmurze, strony internetowe i sieci.
Dane sieciowe
Netdata to najbardziej zaawansowane oprogramowanie typu open source do monitorowania, śledzenia i rozwiązywania problemów z infrastrukturą lokalną i chmurową. Zapewnia metryki w czasie rzeczywistym, wnikliwe wykresy i
inteligentne alarmy, aby szybko identyfikować problemy i podejmować proaktywne kroki, zanim dojdzie do poważnej awarii.

Wszystkie fizyczne i wirtualne serwery, kontenery, infrastruktura chmurowa i wszelkie inne komponenty infrastruktury są przez nią monitorowane. Zbierając i analizując metryki i dzienniki, administratorzy mogą szybko rozwiązywać problemy.
Dzięki przyjaznemu dla użytkownika i prostemu interfejsowi administratorzy i programiści mogą z łatwością uzyskać kluczowy wgląd w działanie swojej infrastruktury, wizualizować złożone dane i wykrywać problemy, zanim wymkną się spod kontroli.
Oferuje szeroki zakres funkcji niezależnie od typu infrastruktury do monitorowania każdego fizycznego i wirtualnego serwera, kontenera i urządzenia IoT. Jego architektura jest oparta na ML, co pomaga szybko wykryć nieprawidłowości i wywołać alert.
Cechy
- Nieskończona skalowalność, od serwerów fizycznych po wdrożenia w chmurze obejmujące szereg usług i urządzeń.
- Setki interaktywnych wykresów aktualizowanych w czasie rzeczywistym co sekundę.
- Rozproszona architektura z ochroną prywatności od samego początku.
- Zerowa konfiguracja monitorowania Kubernetes.
- Wykrywanie anomalii, alerty i korelacje metryki wspomagane przez uczenie maszynowe.
Oprogramowanie open source, Netdata, jest jednym z najczęściej nagradzanych projektów w krajobrazie CNCF. Jest dość elastyczny w integracji różnych popularnych narzędzi, takich jak Prometheus i Grafana, Graphite, OpenTSDB, InfluxDB, a nawet rozwiązań komercyjnych innych firm.
M/Monit
Nowoczesne, małe i skalowalne M/Monit to oprogramowanie stworzone specjalnie do zarządzania i śledzenia systemów Unix. To bezpłatne oprogramowanie o otwartym kodzie źródłowym wykonuje automatyczną konserwację, naprawy i znaczące działania przyczynowe w wyniku błędu, oprócz zarządzania i kontrolowania systemów Unix.
Każdy, kto chce mieć pełną kontrolę nad swoimi systemami Unix, powinien używać tego narzędzia.

Narzędzia dostarczają pełnych informacji o zużyciu zasobów i stanie systemu, a także zapewniają automatyczne alerty w przypadku pojawienia się problemów i podejmują działania naprawcze w razie potrzeby. Za pomocą tego narzędzia administratorzy mogą łatwo i szybko monitorować usługi i urządzenia w całej infrastrukturze.
Cechy
- Możliwość korzystania z komputerów stacjonarnych, tabletów i telefonów w celu uzyskania dostępu do interfejsu.
- Wykresy w czasie rzeczywistym i prognozy trendów.
- Zapewniona jest obsługa gniazd domen TCP, UDP i Unix.
- Mechanizm alertów oparty na regułach.
- Wbudowana obsługa baz danych dla SQLite, MySQL i PostgreSQL.
Jego popularność przypisuje się efektywnej architekturze i funkcjom specyficznym dla zdarzeń, w tym restartowaniu serwerów, debugowaniu i wysyłaniu wiadomości e-mail. Aby tworzyć wykresy informacyjne, automatycznie zbiera kluczowe dane od hosta.
W zależności od wymagań firmy narzędzie to można również modyfikować, aby spełniało określone wymagania dotyczące monitorowania.
LibreNMS
LibreNMS to godna zaufania platforma typu open source do ścisłego monitorowania wydajności i kondycji sieci. Dzięki licznym funkcjom i obsłudze SNMP, Syslog i innych protokołów monitoruje i kontroluje różne urządzenia, usługi, platformy i systemy operacyjne.

Platforma obsługuje systemy takie jak Cisco, Juniper, Linux, Windows i inne. Ze względu na wysoce skalowalną architekturę można go łatwo dostosować do specyficznych wymagań w zakresie monitorowania różnych organizacji różnej wielkości.
Cechy
- Konfigurowalne alerty i powiadomienia można dostosować do konkretnych potrzeb organizacji.
- Gromadzenie danych przy użyciu wielu protokołów (STP, OSPF, BGP itp.).
- Kolekcja tablic VLAN, ARP i FDB.
- Integracja kopii zapasowej urządzenia (utleniona, RANCID).
- Ankietowanie rozproszone.
Narzędzie może wystarczyć do monitorowania sieci i zapewnia wgląd w ruch sieciowy, stan urządzeń i wykorzystanie przepustowości. LibreNMS pomaga w utrzymaniu płynnego działania sieci we wszystkich organizacjach każdej wielkości.
Grafit
Odpowiednim rozwiązaniem do monitorowania infrastruktury dla sieci lokalnych i infrastruktury Cloud dla SMB i dużych korporacji jest Graphite. Służy do monitorowania wydajności stron internetowych, aplikacji, usług komercyjnych i serwerów sieciowych.
Oprogramowanie jest dostosowane do zmieniających się dzisiejszych zestawów danych, ponieważ ułatwia zapisywanie, pobieranie, wymianę i wizualizację danych szeregów czasowych.
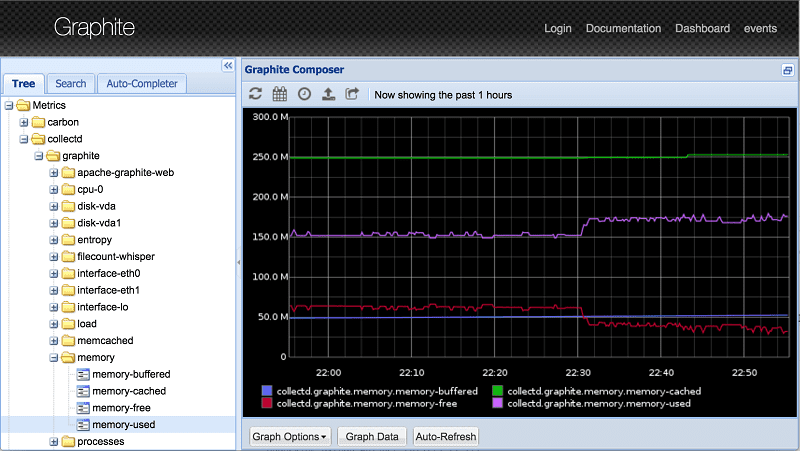
Jego głównym zastosowaniem jest zarządzanie numerycznymi punktami danych szeregów czasowych lub szeregiem wskaźników wydajności, takich jak procesor, metryki we/wy, macierze RAID, dyski SSD itp., z dziesiątek tysięcy serwerów i przedstawiane na wykresach.
Architektura Graphite zapisuje dane numeryczne szeregów czasowych w swojej specjalistycznej bazie danych i służy do ich wizualizacji w postaci wykresów i wykresów w czasie rzeczywistym za pośrednictwem interfejsów internetowych.
Chris Davis stworzył go w Orbitz na początku 2006 roku i ostatecznie zyskał popularność. Graphite jest dystrybuowany na licencji open-source Apache 2.0.
Najlepsi gracze w branży, tacy jak Booking.com, Github, Salesforce, Etsy, Reddit itp., wykorzystują narzędzia do monitorowania Graphite, aby mieć oko na swoją produkcję, handel elektroniczny, usługi itp.
Możliwe jest również połączenie platformy z innymi narzędziami innych firm, takimi jak Nagios, serwer Windows, logstash itp.
Obserwacja
Observium to solidne oprogramowanie do monitorowania i zarządzania siecią, które zapewnia niezrównaną widoczność infrastruktury Twojej firmy.
Dla firm różnej wielkości poszukujących niezawodnego, przyjaznego dla użytkownika rozwiązania do monitorowania, Observium jest doskonałą opcją ze względu na szeroką gamę obsługiwanych urządzeń i pełny zestaw możliwości.
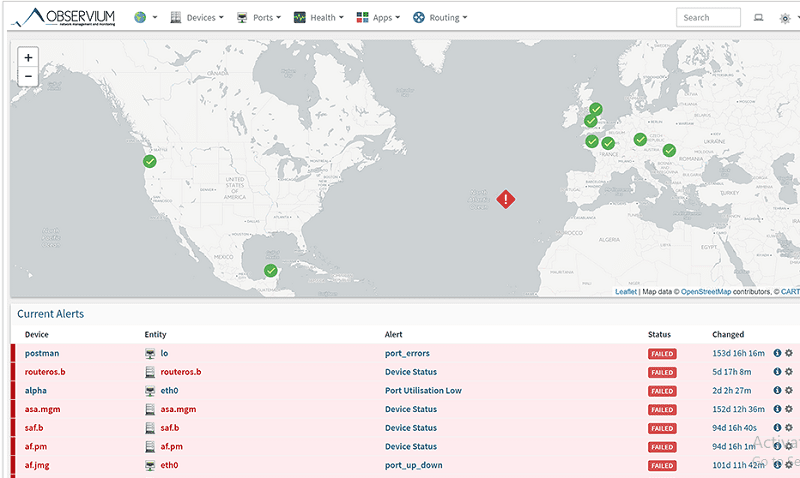
Rządy, duże korporacje, firmy telekomunikacyjne, dostawcy usług internetowych i małe i średnie przedsiębiorstwa dołączyły do bazy użytkowników Observium. Znani klienci to Twitch, eBay, PayPal, Aramco, Squarespace, The Scottish Government, Yahoo Inc., Spotify i inni.
Technologia Observium upraszcza zarządzanie siecią, zbiera wskaźniki wydajności i generuje ostrzeżenia w przypadku wykrycia problemów. Automatycznie wykrywa urządzenia i usługi sieciowe oraz wykonuje dziesiątki tysięcy instalacji w celu monitorowania milionów urządzeń.
Możesz konfigurować progi i stany awarii dla różnych rodzajów jednostek za pomocą systemu ostrzegania o progach.
Cechy
- Zapewnia proaktywne informacje, aby poradzić sobie z potencjalnymi problemami, zanim spowodują one awarie lub przestoje.
- Pomaga w planowaniu odzyskiwania po awarii.
- Śledzenie i rozliczanie wykorzystania przepustowości przez konsumentów jest prostsze dzięki rozliczaniu ruchu.
- Obsługiwane są aplikacje innych firm, w tym Apache, BIND, DRBD, Memcached, MySQL, NFS i inne.
Dzięki przyjaznemu dla użytkownika interfejsowi sieciowemu Observium platforma może być łatwo kontrolowana zarówno przez osoby techniczne, jak i nietechniczne, aby zrozumieć kondycję i stan sieci.
Jest kompatybilny z szeroką gamą sprzętu, oprogramowania i systemów operacyjnych, w tym Cisco, Windows, Linux, HP, Juniper, Dell, FreeBSD, Brocade, Netscaler, NetApp i wieloma innymi.
Wersje Enterprise, Professional i Community to trzy oferowane edycje programu. Wersja społecznościowa jest bezpłatna.
Ostatnie słowa
Śledzenie, monitorowanie i zarządzanie infrastrukturą z odrobiną automatyzacji stało się koniecznością dzisiejszej światowej technologii. Oprogramowanie monitorujące typu open source jest bezpłatne; niektóre programy mają nawet zaawansowane funkcje w swoich wersjach premium.
Większość omówionego powyżej oprogramowania jest wszechstronna i obsługuje zarówno małe, jak i duże organizacje. Zasugerowanie konkretnego oprogramowania dla wszystkich jest trudne, ponieważ każda organizacja ma różne zainteresowania.
Dlatego zaleca się wypróbowanie tego oprogramowania monitorującego i, w oparciu o swoją przydatność, możesz sfinalizować najlepsze oprogramowanie dla swojej infrastruktury.
Może zainteresuje Cię również nasze wprowadzenie do Prometheusa i Grafany.