W dzisiejszym świecie dane stały się kluczowym elementem w procesie tworzenia modeli uczenia maszynowego, testowania oprogramowania oraz w analizie biznesowej. Ich rosnąca wartość sprawia, że dostęp do nich jest coraz bardziej pożądany.
Z uwagi na liczne przepisy dotyczące ochrony danych, ich przechowywanie i dostęp do nich są często ściśle kontrolowane. Zanim firma otrzyma potrzebne zgody na wykorzystanie konkretnych danych, może upłynąć wiele miesięcy. W takich sytuacjach, dane syntetyczne stanowią atrakcyjną alternatywę.
Czym są dane syntetyczne?
Źródło zdjęcia: Twinify
Dane syntetyczne to zbiory danych, które są tworzone sztucznie, ale ich właściwości statystyczne przypominają te z istniejących zbiorów. Mogą być wykorzystywane jako wsparcie lub uzupełnienie dla realnych danych, przyczyniając się do usprawnienia modeli sztucznej inteligencji. Czasami mogą nawet całkowicie zastąpić dane rzeczywiste.
Ponieważ nie są one powiązane z konkretnymi osobami i nie zawierają informacji identyfikujących ani danych wrażliwych, takich jak numery PESEL, stanowią bezpieczną alternatywę dla prawdziwych danych produkcyjnych, chroniąc prywatność użytkowników.
Główne różnice między danymi rzeczywistymi a syntetycznymi
- Podstawowa różnica leży w sposobie ich generowania. Dane rzeczywiste pochodzą od osób, które wyraziły zgodę na ich zbieranie podczas badań ankietowych lub korzystania z aplikacji. Natomiast dane syntetyczne są generowane sztucznie, choć ich struktura odzwierciedla cechy oryginalnych danych.
- Kolejna różnica dotyczy przepisów o ochronie danych. W przypadku danych realnych, osoby, których dane dotyczą, muszą być świadome, jakie informacje są gromadzone i dlaczego, oraz istnieją ograniczenia co do ich wykorzystania. Przepisy te nie mają zastosowania do danych syntetycznych, ponieważ nie można ich przypisać do konkretnych osób ani powiązać z danymi osobowymi.
- Trzecia różnica wiąże się z ilością dostępnych danych. Z prawdziwych danych możemy pozyskać tylko tyle, ile udostępnią nam użytkownicy. W przypadku danych syntetycznych ilość wygenerowanych informacji jest praktycznie nieograniczona.
Dlaczego warto rozważyć wykorzystanie danych syntetycznych?
- Generowanie danych syntetycznych jest stosunkowo tanie, ponieważ można tworzyć obszerne zbiory danych przypominające mniejszy, istniejący zbiór. Pozwala to na lepsze trenowanie modeli uczenia maszynowego.
- Dane syntetyczne są automatycznie oznaczane i czyszczone, co eliminuje czasochłonne przygotowywanie danych pod kątem uczenia maszynowego lub analiz.
- Wykorzystanie danych syntetycznych nie budzi obaw dotyczących prywatności, ponieważ nie umożliwiają one identyfikacji osób i nie są z nimi powiązane. Oznacza to swobodę w ich wykorzystywaniu i udostępnianiu.
- Dzięki danym syntetycznym można zminimalizować ryzyko występowania stronniczości w sztucznej inteligencji poprzez zadbanie o odpowiednią reprezentację grup mniejszościowych, co przyczynia się do budowy uczciwej i odpowiedzialnej AI.
Jak generować dane syntetyczne?
Proces generowania danych syntetycznych różni się w zależności od używanego narzędzia, ale zazwyczaj zaczyna się od podłączenia generatora do istniejącego zestawu danych. Następnie identyfikuje się i oznacza pola, które mogą identyfikować osoby, aby je wykluczyć lub zaszyfrować.
Kolejnym krokiem jest analiza przez generator typów danych w pozostałych kolumnach i wzorców statystycznych. Na tej podstawie można generować żądaną ilość danych syntetycznych.
Zazwyczaj istnieje możliwość porównania wygenerowanych danych z danymi oryginalnymi, aby ocenić ich podobieństwo.
Teraz przyjrzymy się narzędziom, które ułatwiają generowanie danych syntetycznych na potrzeby trenowania modeli uczenia maszynowego.
Mostly AI

Mostly AI oferuje generator danych syntetycznych oparty na sztucznej inteligencji, która analizuje wzorce statystyczne oryginalnego zestawu danych. Na tej podstawie AI tworzy fikcyjne dane, zachowując wyuczone wzorce.
Platforma umożliwia generowanie całych baz danych z integralnością referencyjną i oferuje możliwość syntezy różnorodnych typów danych, co wspiera budowę efektywniejszych modeli AI.
Synthesized.io

Synthesized.io jest wybierany przez wiele wiodących firm dla projektów związanych ze sztuczną inteligencją. Aby korzystać z platformy, należy zdefiniować wymagania dotyczące danych w pliku konfiguracyjnym YAML.
Następnie tworzy się zadanie i uruchamia je w ramach potoku danych. Synthesized.io oferuje hojny bezpłatny plan, który pozwala na testowanie i sprawdzenie, czy platforma spełnia potrzeby w zakresie danych.
YData

YData umożliwia generowanie danych tabelarycznych, szeregów czasowych, transakcyjnych, wielotabelarycznych i relacyjnych. Pozwala to na rozwiązanie problemów związanych z pozyskiwaniem, udostępnianiem i jakością danych.
Platforma oferuje wsparcie sztucznej inteligencji oraz SDK ułatwiające interakcję. Dostępny jest również bezpłatny plan, który pozwala na wypróbowanie produktu.
Gretel AI

Gretel AI dostarcza API do generowania nieograniczonej ilości danych syntetycznych. Oferuje również generator danych typu open-source, który można zainstalować i używać we własnym środowisku.
Alternatywnie, można korzystać z ich REST API lub CLI, co wiąże się z pewnymi kosztami. Jednak ceny są rozsądne i dopasowane do wielkości firmy.
Kopuły
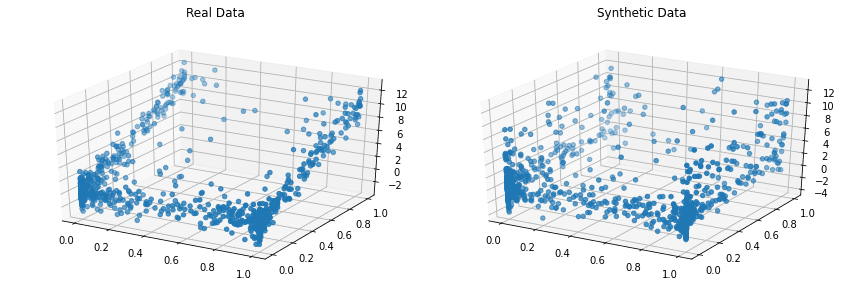
Copulas to otwarta biblioteka języka Python, która pozwala na modelowanie rozkładów wielowymiarowych za pomocą funkcji kopuły oraz generowanie danych syntetycznych o identycznych właściwościach statystycznych.
Projekt rozpoczęto w 2018 roku na MIT jako część projektu Synthetic Data Vault.
CTGAN
CTGAN wykorzystuje generatory, które uczą się na podstawie danych realnych pochodzących z pojedynczej tabeli, a następnie na podstawie wyuczonych wzorców generują dane syntetyczne.
Biblioteka jest dostępna w języku Python jako open source. CTGAN, wraz z Copulas, jest częścią projektu Synthetic Data Vault Project.
DoppelGANger
DoppelGANger to implementacja Generative Adversarial Networks typu open source, dedykowana do generowania danych syntetycznych.
Szczególnie przydatny jest do tworzenia danych szeregów czasowych i jest używany przez firmy, takie jak Gretel AI. Biblioteka w języku Python jest dostępna bezpłatnie jako open source.
Syntezator

Synth to generator danych open source, który umożliwia tworzenie realistycznych danych zgodnie ze specyfikacją, ochronę danych osobowych oraz generowanie danych testowych dla aplikacji.
Można go wykorzystywać do generowania szeregów w czasie rzeczywistym i danych relacyjnych na potrzeby uczenia maszynowego. Synth działa niezależnie od bazy danych, dzięki czemu można go używać zarówno z bazami SQL, jak i NoSQL.
Odch. SDV
SDV, czyli Synthetic Data Vault, to projekt oprogramowania, który rozpoczął się w MIT w 2016 roku. W ramach projektu powstały różne narzędzia do generowania danych syntetycznych.
Do tych narzędzi należą Copulas, CTGAN, DeepEcho i RDT. Są one dostępne jako otwarte biblioteki w języku Python, łatwe do wdrożenia i wykorzystania.
tofu
Tofu to biblioteka open source w Pythonie, która służy do generowania danych syntetycznych na podstawie danych z brytyjskich biobanków. W przeciwieństwie do innych narzędzi, które generują dane na podstawie dowolnych zbiorów, Tofu tworzy dane podobne tylko do danych z biobanków.
UK Biobank to badanie, które analizuje cechy fenotypowe i genotypowe 500 000 dorosłych osób w średnim wieku w Wielkiej Brytanii.
Twinify
Twinify to pakiet oprogramowania, który można używać jako bibliotekę lub narzędzie wiersza poleceń do anonimizacji poufnych danych poprzez generowanie danych syntetycznych z identycznymi rozkładami statystycznymi.

Aby użyć Twinify, wystarczy dostarczyć dane w formacie CSV, a platforma nauczy się na ich podstawie tworzyć model, który generuje dane syntetyczne. Jest on dostępny całkowicie za darmo.
Datanamic
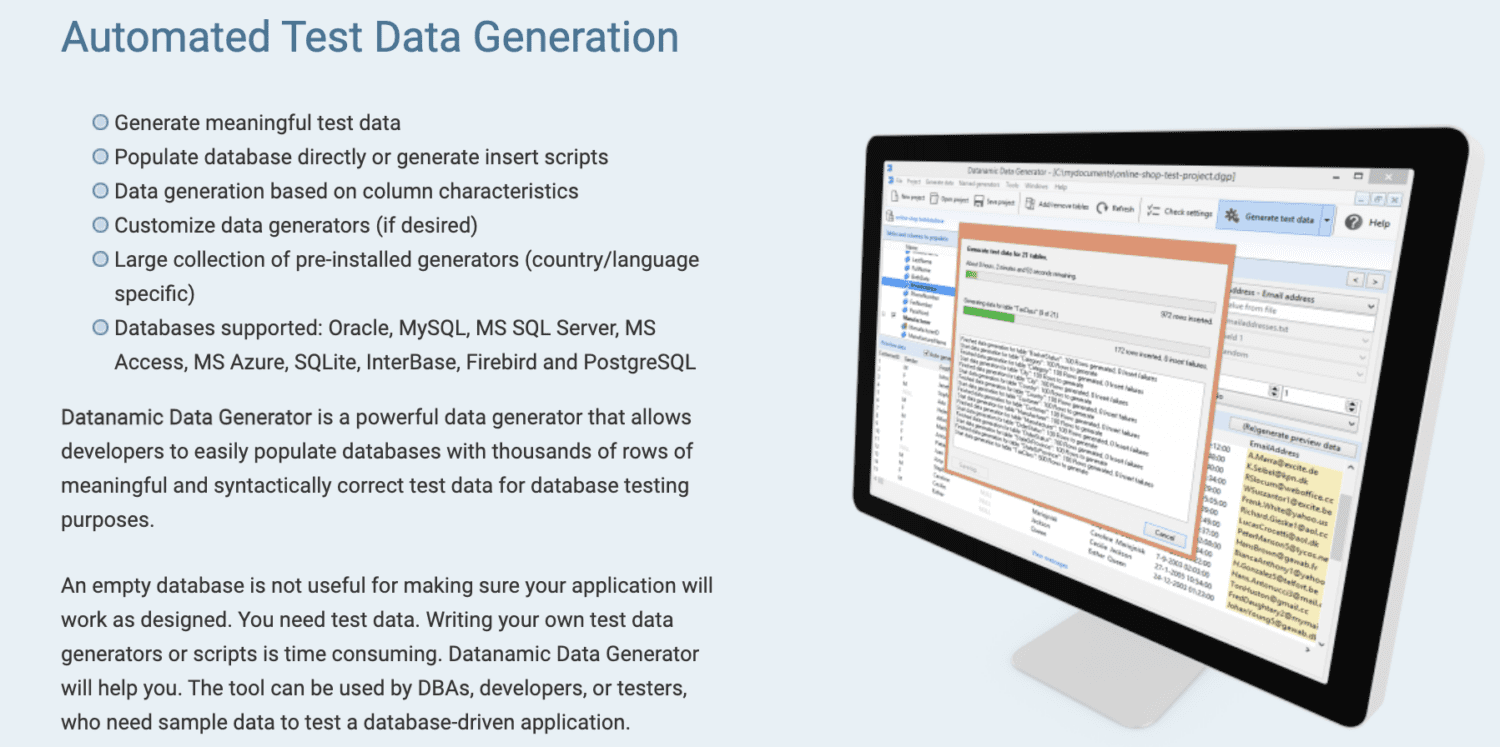
Datanamic wspiera tworzenie danych testowych dla aplikacji opartych na danych i uczeniu maszynowym. Generuje dane na podstawie cech kolumn, takich jak adres e-mail, imię i nazwisko czy numer telefonu.
Generatory danych Datanamic są konfigurowalne i kompatybilne z większością baz danych, takich jak Oracle, MySQL, MySQL Server, MS Access i Postgres. Zapewniają integralność referencyjną generowanych danych.
Benerator
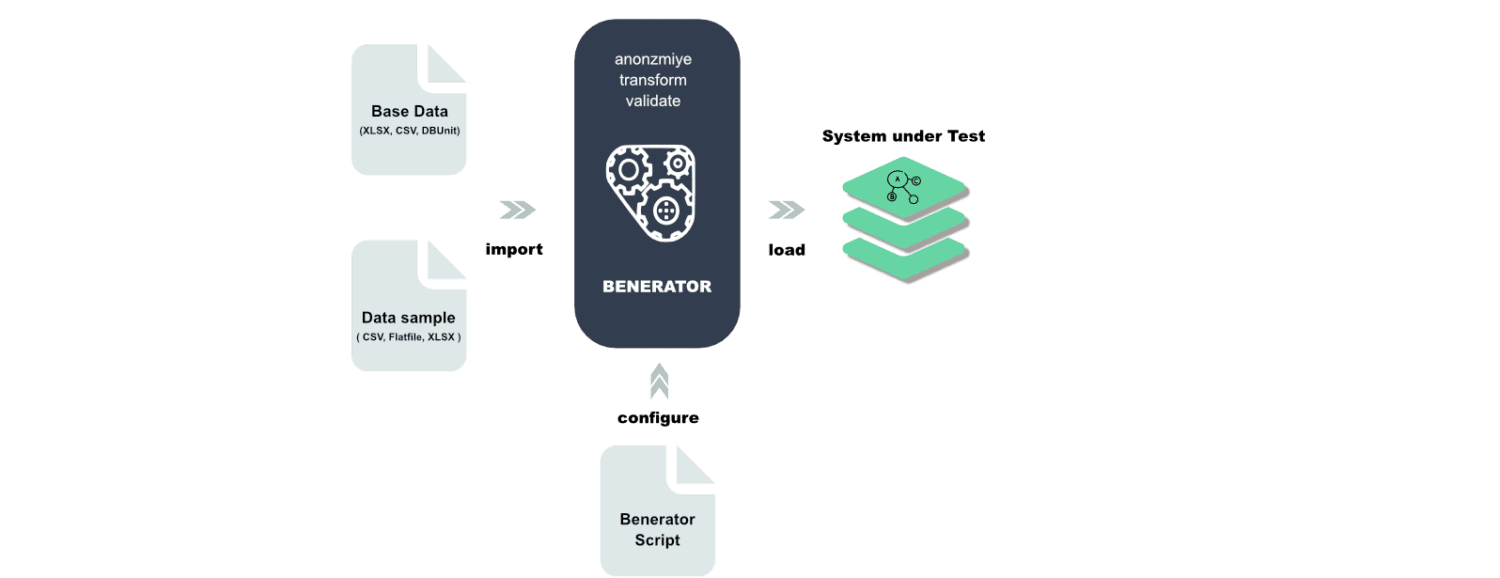
Benerator to oprogramowanie służące do anonimizacji, generowania i migracji danych na potrzeby testów i szkoleń. W Beneratorze opisuje się dane za pomocą XML (Extensible Markup Language), a następnie generuje się je przy użyciu narzędzia wiersza poleceń.
Jest przeznaczony dla osób, które nie są programistami, i umożliwia generowanie nawet miliardów wierszy danych. Benerator jest darmowy i dostępny na zasadach open source.
Podsumowanie
Eksperci z Gartnera prognozują, że do 2030 roku w procesach uczenia maszynowego będzie wykorzystywanych więcej danych syntetycznych niż danych rzeczywistych.
Biorąc pod uwagę koszty i obawy o prywatność związane z użyciem prawdziwych danych, nietrudno zrozumieć ten trend. Dlatego ważne jest, aby firmy zaznajomiły się z danymi syntetycznymi i narzędziami ułatwiającymi ich generowanie.
W kolejnym kroku warto zapoznać się z syntetycznymi narzędziami monitorującymi, przydatnymi dla firm działających online.
newsblog.pl
Maciej – redaktor, pasjonat technologii i samozwańczy pogromca błędów w systemie Windows. Zna Linuxa lepiej niż własną lodówkę, a kawa to jego główne źródło zasilania. Pisze, testuje, naprawia – i czasem nawet wyłącza i włącza ponownie. W wolnych chwilach udaje, że odpoczywa, ale i tak kończy z laptopem na kolanach.