
Google JAX lub Just After Execution to framework opracowany przez Google w celu przyspieszenia zadań uczenia maszynowego.
Możesz uznać to za bibliotekę dla Pythona, która pomaga w szybszym wykonywaniu zadań, obliczeniach naukowych, transformacjach funkcji, uczeniu głębokim, sieciach neuronowych i wielu innych.
Spis treści:
O Google JAX
Najbardziej podstawowym pakietem obliczeniowym w Pythonie jest pakiet NumPy, który zawiera wszystkie funkcje, takie jak agregacje, operacje wektorowe, algebra liniowa, manipulacje tablicami n-wymiarowymi i macierzami oraz wiele innych zaawansowanych funkcji.
Co by było, gdybyśmy mogli jeszcze bardziej przyspieszyć obliczenia wykonywane za pomocą NumPy – szczególnie w przypadku ogromnych zbiorów danych?
Czy mamy coś, co mogłoby działać równie dobrze na różnych typach procesorów, takich jak GPU lub TPU, bez żadnych zmian w kodzie?
A gdyby tak system mógł wykonywać transformacje funkcji komponowalnych automatycznie i wydajniej?
Google JAX to biblioteka (lub framework, jak mówi Wikipedia), która robi właśnie to, a może nawet dużo więcej. Został stworzony, aby zoptymalizować wydajność i wydajnie wykonywać zadania uczenia maszynowego (ML) i uczenia głębokiego. Google JAX zapewnia następujące funkcje transformacji, które wyróżniają go spośród innych bibliotek ML i pomagają w zaawansowanych obliczeniach naukowych dla głębokiego uczenia i sieci neuronowych:
- Automatyczne różnicowanie
- Automatyczna wektoryzacja
- Automatyczna równoległość
- Kompilacja just-in-time (JIT)
Unikalne funkcje Google JAX
Wszystkie transformacje wykorzystują XLA (Accelerated Linear Algebra) w celu uzyskania wyższej wydajności i optymalizacji pamięci. XLA to specyficzny dla domeny, optymalizujący silnik kompilatora, który wykonuje algebrę liniową i przyspiesza modele TensorFlow. Używanie XLA w kodzie Pythona nie wymaga żadnych znaczących zmian w kodzie!
Przyjrzyjmy się szczegółowo każdej z tych funkcji.
Funkcje Google JAX
Google JAX jest wyposażony w ważne funkcje transformacji, które można komponować, aby poprawić wydajność i wydajniej wykonywać zadania uczenia głębokiego. Na przykład autoróżnicowanie, aby uzyskać gradient funkcji i znaleźć pochodne dowolnego rzędu. Podobnie automatyczna równoległość i JIT do równoległego wykonywania wielu zadań. Te transformacje mają kluczowe znaczenie dla zastosowań takich jak robotyka, gry, a nawet badania.
Komponowalna funkcja transformacji to czysta funkcja, która przekształca zbiór danych w inną postać. Nazywa się je komponowalnymi, ponieważ są samowystarczalne (tzn. te funkcje nie są zależne od reszty programu) i są bezstanowe (tzn. te same dane wejściowe zawsze dadzą te same dane wyjściowe).
Y(x) = T: (f(x))
W powyższym równaniu f(x) jest pierwotną funkcją, do której stosuje się transformację. Y(x) jest funkcją wynikową po zastosowaniu transformacji.
Na przykład, jeśli masz funkcję o nazwie „total_bill_amt” i chcesz, aby wynik był transformacją funkcji, możesz po prostu użyć transformacji, którą chcesz, powiedzmy gradient (grad):
grad_total_bill = grad(total_bill_amt)
Przekształcając funkcje numeryczne za pomocą funkcji takich jak grad(), możemy łatwo uzyskać ich pochodne wyższego rzędu, które możemy szeroko wykorzystać w algorytmach optymalizacji uczenia głębokiego, takich jak zejść gradientu, dzięki czemu algorytmy są szybsze i bardziej wydajne. Podobnie, używając jit(), możemy kompilować programy Pythona just-in-time (leniwie).
#1. Automatyczne różnicowanie
Python używa funkcji autograd do automatycznego rozróżniania NumPy i natywnego kodu Pythona. JAX używa zmodyfikowanej wersji autogradu (tj. grad) i łączy XLA (Accelerated Linear Algebra) do automatycznego różnicowania i znajdowania pochodnych dowolnego zamówienia dla GPU (jednostek przetwarzania grafiki) i TPU (jednostek przetwarzania tensorów).]
Krótka uwaga na temat TPU, GPU i CPU: CPU lub jednostka centralna zarządza wszystkimi operacjami na komputerze. GPU to dodatkowy procesor, który zwiększa moc obliczeniową i umożliwia wykonywanie zaawansowanych operacji. TPU to potężna jednostka opracowana specjalnie do złożonych i ciężkich obciążeń, takich jak sztuczna inteligencja i algorytmy głębokiego uczenia.
Podobnie jak funkcja autograd, która może rozróżniać pętle, rekursje, rozgałęzienia itd., JAX używa funkcji grad() dla gradientów w trybie odwrotnym (propagacji wstecznej). Ponadto możemy zróżnicować funkcję do dowolnej kolejności za pomocą gradacji:
grad(grad(grad(sin θ))) (1,0)
Automatyczne różnicowanie wyższego rzędu
Jak wspomnieliśmy wcześniej, grad jest bardzo przydatny w znajdowaniu pochodnych cząstkowych funkcji. Możemy użyć pochodnej cząstkowej do obliczenia gradientu spadku funkcji kosztu względem parametrów sieci neuronowej w głębokim uczeniu, aby zminimalizować straty.
Obliczanie pochodnej cząstkowej
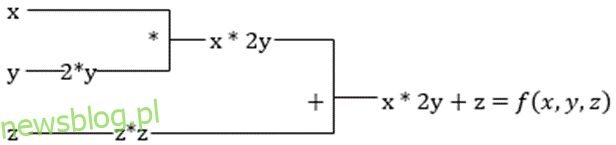
Załóżmy, że funkcja ma wiele zmiennych, x, y i z. Znalezienie pochodnej jednej zmiennej przez utrzymywanie innych zmiennych na stałym poziomie nazywa się pochodną cząstkową. Załóżmy, że mamy funkcję,
f(x,y,z) = x + 2y + z2
Przykład pokazujący pochodną cząstkową
Pochodna cząstkowa x będzie wynosić ∂f/∂x, co mówi nam, jak funkcja zmienia się dla zmiennej, gdy inne są stałe. Jeśli wykonamy to ręcznie, musimy napisać program do różnicowania, zastosować go dla każdej zmiennej, a następnie obliczyć spadek gradientu. Stałoby się to złożoną i czasochłonną sprawą dla wielu zmiennych.
Automatyczne różnicowanie rozbija funkcję na zestaw podstawowych operacji, takich jak +, -, *, / lub sin, cos, tan, exp itp., a następnie stosuje regułę łańcucha do obliczenia pochodnej. Możemy to zrobić zarówno w trybie do przodu, jak i do tyłu.
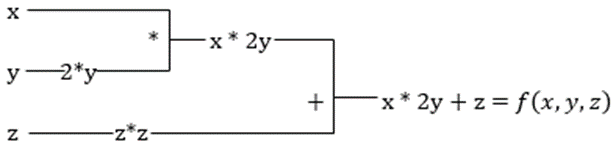
To nie to! Wszystkie te obliczenia odbywają się tak szybko (no cóż, pomyśl o milionie obliczeń podobnych do powyższego i czasie, który może zająć!). XLA dba o szybkość i wydajność.
#2. Przyspieszona algebra liniowa
Weźmy poprzednie równanie. Bez XLA obliczenia będą wymagały trzech (lub więcej) jąder, przy czym każde jądro wykona mniejsze zadanie. Na przykład,
Jądro k1 –> x * 2y (mnożenie)
k2 –> x * 2y + z (dodawanie)
k3 -> Redukcja
Jeśli to samo zadanie jest wykonywane przez XLA, pojedyncze jądro zajmuje się wszystkimi pośrednimi operacjami, łącząc je. Pośrednie wyniki operacji elementarnych są przesyłane strumieniowo zamiast przechowywania ich w pamięci, co oszczędza pamięć i zwiększa szybkość.
#3. Kompilacja just-in-time
JAX wewnętrznie wykorzystuje kompilator XLA, aby zwiększyć szybkość wykonywania. XLA może zwiększyć szybkość CPU, GPU i TPU. Wszystko to jest możliwe dzięki wykonaniu kodu JIT. Aby tego użyć, możemy użyć jit poprzez import:
from jax import jit def my_function(x): …………some lines of code my_function_jit = jit(my_function)
Innym sposobem jest dekorowanie jit nad definicją funkcji:
@jit def my_function(x): …………some lines of code
Ten kod jest znacznie szybszy, ponieważ transformacja zwróci skompilowaną wersję kodu do wywołującego, zamiast używać interpretera Pythona. Jest to szczególnie przydatne w przypadku danych wejściowych wektorowych, takich jak tablice i macierze.
To samo dotyczy wszystkich istniejących funkcji Pythona. Na przykład funkcje z pakietu NumPy. W takim przypadku powinniśmy zaimportować jax.numpy jako jnp zamiast NumPy:
import jax import jax.numpy as jnp x = jnp.array([[1,2,3,4], [5,6,7,8]])
Gdy to zrobisz, podstawowy obiekt tablicy JAX o nazwie DeviceArray zastępuje standardową tablicę NumPy. DeviceArray jest leniwy – wartości są przechowywane w akceleratorze do czasu, aż będą potrzebne. Oznacza to również, że program JAX nie czeka, aż wyniki powrócą do programu wywołującego (Python), a zatem następuje asynchroniczna wysyłka.
#4. Automatyczna wektoryzacja (vmap)
W typowym świecie uczenia maszynowego mamy zestawy danych zawierające milion lub więcej punktów danych. Najprawdopodobniej wykonalibyśmy pewne obliczenia lub manipulacje na każdym lub większości z tych punktów danych – co jest bardzo czasochłonnym i pochłaniającym pamięć zadaniem! Na przykład, jeśli chcesz znaleźć kwadrat każdego z punktów danych w zestawie danych, pierwszą rzeczą, o której myślisz, jest utworzenie pętli i wzięcie kwadratu jeden po drugim – argh!
Jeśli utworzymy te punkty jako wektory, możemy wykonać wszystkie kwadraty za jednym razem, wykonując manipulacje wektorami lub macierzami na punktach danych za pomocą naszego ulubionego NumPy. A jeśli Twój program mógłby to zrobić automatycznie – czy możesz prosić o coś więcej? To jest dokładnie to, co robi JAX! Może automatycznie wektoryzować wszystkie punkty danych, dzięki czemu możesz łatwo wykonywać na nich dowolne operacje – dzięki czemu algorytmy są znacznie szybsze i wydajniejsze.
JAX używa funkcji vmap do automatycznej wektoryzacji. Rozważ następującą tablicę:
x = jnp.array([1,2,3,4,5,6,7,8,9,10]) y = jnp.square(x)
Wykonując tylko powyższe, metoda kwadratowa zostanie wykonana dla każdego punktu w tablicy. Ale jeśli wykonasz następujące czynności:
vmap(jnp.square(x))
Metoda square zostanie wykonana tylko raz, ponieważ punkty danych są teraz wektoryzowane automatycznie przy użyciu metody vmap przed wykonaniem funkcji, a pętla jest spychana w dół do podstawowego poziomu operacji – co skutkuje mnożeniem macierzy zamiast mnożenia przez skalar, co zapewnia lepszą wydajność .
#5. Programowanie SPMD (pmap)
SPMD — lub programowanie wielu danych w jednym programie — jest niezbędne w kontekście uczenia głębokiego — często stosuje się te same funkcje do różnych zestawów danych znajdujących się na wielu procesorach GPU lub TPU. JAX posiada funkcję o nazwie pump, która pozwala na równoległe programowanie na wielu GPU lub dowolnym akceleratorze. Podobnie jak JIT, programy używające pmap będą kompilowane przez XLA i wykonywane jednocześnie w systemach. Ta automatyczna równoległość działa zarówno w przypadku obliczeń do przodu, jak i do tyłu.
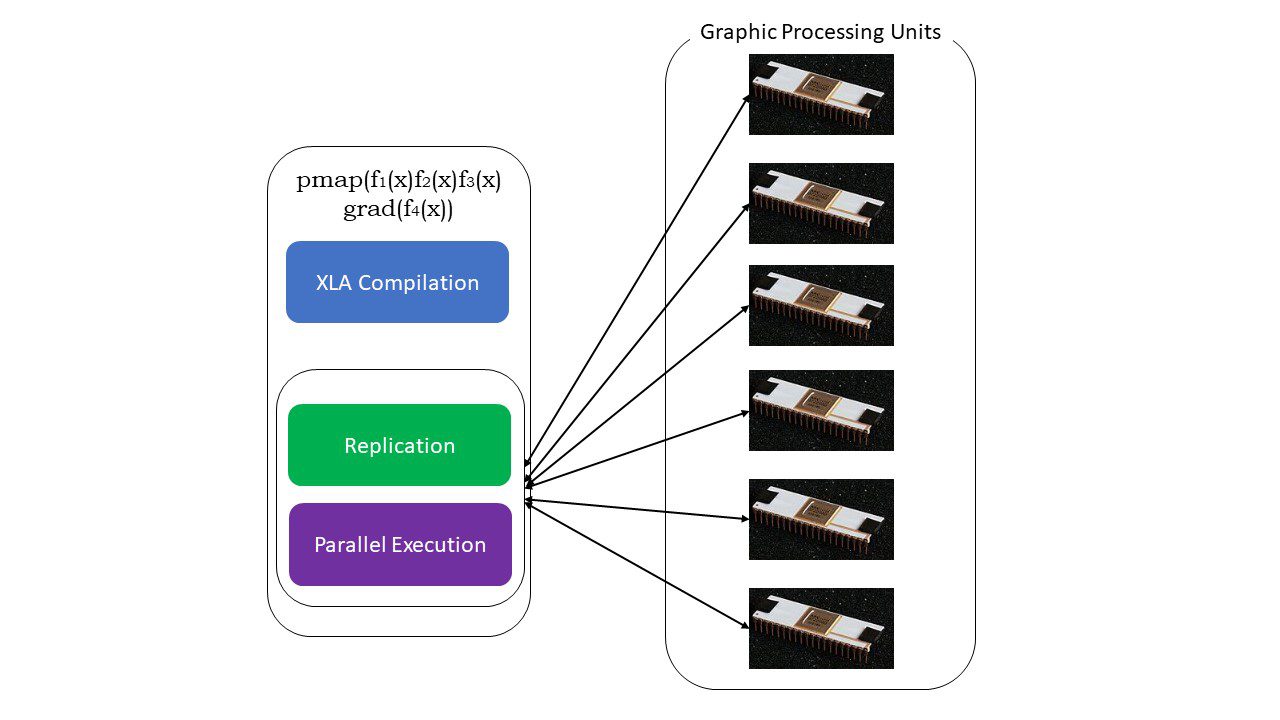 Jak działa pmap
Jak działa pmap
Możemy również zastosować wiele przekształceń za jednym razem w dowolnej kolejności w dowolnej funkcji, jako:
pmap(vmap(jit(grad (f(x)))))
Wiele kompozycji komponowanych
Ograniczenia Google JAX
Programiści Google JAX dobrze pomyśleli o przyspieszeniu algorytmów głębokiego uczenia, wprowadzając wszystkie te niesamowite transformacje. Funkcje i pakiety obliczeń naukowych są na wzór NumPy, więc nie musisz się martwić o krzywą uczenia się. Jednak JAX ma następujące ograniczenia:
- Google JAX wciąż znajduje się na wczesnym etapie rozwoju i chociaż jego głównym celem jest optymalizacja wydajności, nie zapewnia on większych korzyści dla obliczeń CPU. Wydaje się, że NumPy działa lepiej, a używanie JAX może tylko zwiększyć obciążenie.
- JAX jest wciąż w fazie badań lub na wczesnym etapie i potrzebuje dokładniejszego dopracowania, aby osiągnąć standardy infrastruktury takich frameworków, jak TensorFlow, które są bardziej ugruntowane i mają więcej predefiniowanych modeli, projektów open source i materiałów edukacyjnych.
- Jak na razie JAX nie obsługuje systemu operacyjnego Windows – do jego działania potrzebna jest maszyna wirtualna.
- JAX działa tylko na czystych funkcjach – takich, które nie mają żadnych skutków ubocznych. W przypadku funkcji z efektami ubocznymi JAX może nie być dobrym rozwiązaniem.
Jak zainstalować JAX w swoim środowisku Python?
Jeśli masz konfigurację Pythona w swoim systemie i chcesz uruchomić JAX na komputerze lokalnym (CPU), użyj następujących poleceń:
pip install --upgrade pip pip install --upgrade "jax[cpu]"
Jeśli chcesz uruchomić Google JAX na GPU lub TPU, postępuj zgodnie z instrukcjami podanymi na GitHub JAX strona. Aby skonfigurować Pythona, odwiedź Oficjalne pliki do pobrania Pythona strona.
Wniosek
Google JAX doskonale nadaje się do pisania wydajnych algorytmów uczenia głębokiego, robotyki i badań. Pomimo ograniczeń jest szeroko stosowany z innymi frameworkami, takimi jak Haiku, Flax i wiele innych. Będziesz mógł docenić to, co robi JAX podczas uruchamiania programów i zobaczyć różnice czasowe w wykonywaniu kodu zi bez JAX. Możesz zacząć od przeczytania oficjalna dokumentacja Google JAXktóry jest dość obszerny.