Wraz z dynamicznym wzrostem ilości danych generowanych przez przedsiębiorstwa, tradycyjne metody zarządzania hurtowniami danych stają się coraz bardziej skomplikowane i kosztowne. W odpowiedzi na te wyzwania, pojawiła się koncepcja Data Vault – innowacyjne podejście, które oferuje elastyczne, skalowalne i ekonomiczne rozwiązania w zakresie gromadzenia i analizowania ogromnych zbiorów informacji.
W niniejszym artykule przyjrzymy się bliżej, dlaczego Data Vault jest uważany za przyszłość hurtowni danych i dlaczego coraz więcej organizacji decyduje się na wdrożenie tego modelu. Zaprezentujemy także przydatne zasoby edukacyjne, które umożliwią Czytelnikowi dogłębne zrozumienie tej tematyki.
Czym jest Data Vault?
Data Vault to technika modelowania hurtowni danych, która wyjątkowo dobrze sprawdza się w przypadku systemów wymagających dużej elastyczności. Charakteryzuje się łatwością rozbudowy, kompleksową historią danych w ujęciu czasowym oraz możliwością równoległego przetwarzania danych podczas ładowania. Autorem koncepcji Data Vault, rozwijanej od lat 90., jest Dan Linstedt.
Po opublikowaniu pierwszych materiałów na ten temat w roku 2000, w 2002 roku zyskała ona szersze uznanie dzięki serii artykułów. W 2007 roku model ten uzyskał poparcie Billa Inmona, który określił go mianem „optymalnego wyboru” dla swojej architektury Data Vault 2.0.
Każdy, kto interesuje się tematyką elastycznych hurtowni danych, prędzej czy później natrafi na Data Vault. Istotną cechą tego podejścia jest jego silne ukierunkowanie na potrzeby biznesowe, umożliwiające adaptację hurtowni danych w sposób elastyczny i bez nadmiernego nakładu pracy.
Data Vault 2.0 obejmuje cały proces projektowania i implementacji architektury, składając się z metody komponentów, samej architektury oraz modelu. Korzyścią tego podejścia jest holistyczne uwzględnienie wszystkich aspektów analizy biznesowej, wraz z bazową strukturą hurtowni danych.
Model Data Vault stanowi nowoczesne rozwiązanie, pozwalające przezwyciężyć ograniczenia tradycyjnych metod modelowania danych. Dzięki swojej skalowalności, elastyczności i zwinności, oferuje solidne fundamenty dla budowy platformy danych, która potrafi sprostać złożoności i różnorodności współczesnych środowisk danych.
Architektura Data Vault oparta na topologii „hub-and-spoke” oraz separacja jednostek od atrybutów umożliwiają integrację i harmonizację danych pochodzących z różnych systemów i domen, ułatwiając tym samym stopniowy i zwinny rozwój.
Kluczową rolą Data Vault w tworzeniu platformy danych jest ustanowienie jednego, wiarygodnego źródła prawdy o danych. Ujednolicony widok danych oraz możliwość śledzenia zmian historycznych za pomocą tabel satelitarnych zapewniają zgodność z wymogami regulacyjnymi, ułatwiają audyty oraz umożliwiają kompleksową analizę i raportowanie.
Możliwości integracji danych w czasie zbliżonym do rzeczywistego, dzięki mechanizmowi ładowania delta, pozwalają na efektywną obsługę dużych wolumenów danych w dynamicznych środowiskach, takich jak Big Data i aplikacje IoT.
Data Vault a tradycyjne modele hurtowni danych
Trzecia Postać Normalna (3NF) jest jednym z najbardziej rozpoznawalnych tradycyjnych modeli hurtowni danych, często preferowanym w wielu dużych wdrożeniach. Jest ona zgodna z koncepcjami Billa Inmona, jednego z pionierów idei hurtowni danych.
Architektura Inmona opiera się na relacyjnym modelu bazy danych i dąży do eliminacji redundancji danych poprzez dzielenie źródeł danych na mniejsze tabele, które są następnie przechowywane w hurtowni danych i powiązane za pomocą kluczy podstawowych i obcych. Zapewnia to spójność i dokładność danych poprzez egzekwowanie zasad integralności referencyjnej.
Celem normalizacji było stworzenie kompleksowego, obejmującego całą organizację modelu danych dla podstawowej hurtowni danych. Niemniej jednak, model ten napotyka na trudności w zakresie skalowalności i elastyczności z powodu silnego powiązania tabel, problemów z ładowaniem danych w czasie zbliżonym do rzeczywistego, pracochłonnych zapytań oraz odgórnego podejścia do projektowania i implementacji.
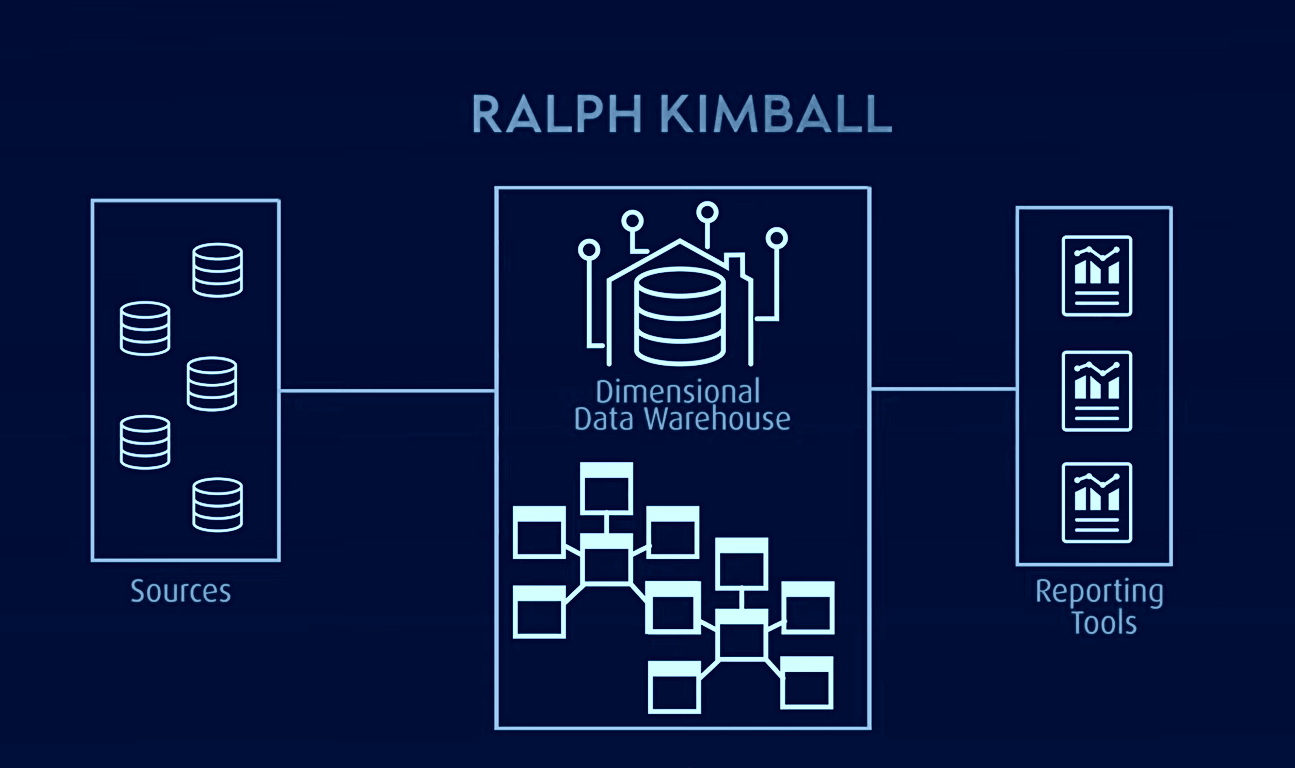
Model Kimballa, szeroko stosowany w systemach OLAP (przetwarzanie analityczne online) i hurtowniach danych, stanowi kolejny popularny model, w którym tabele faktów zawierają zagregowane dane, a tabele wymiarów opisują te dane w schemacie gwiazdy lub płatka śniegu. W tej architekturze dane są zorganizowane w tabele faktów i wymiarów, które są zdenormalizowane w celu uproszczenia procesów zapytań i analiz.
Model Kimballa opiera się na strukturze wymiarowej, zoptymalizowanej pod kątem zapytań i raportowania, co czyni go idealnym dla zastosowań Business Intelligence. Jednakże, model ten zmaga się z problemami izolacji informacji zorientowanych tematycznie, redundancją danych, niekompatybilnymi strukturami zapytań, trudnościami ze skalowalnością, niespójną szczegółowością tabel faktów, problemami z synchronizacją oraz potrzebą odgórnego projektowania połączonego z implementacją oddolną.
W odróżnieniu od tych podejść, architektura Data Vault stanowi hybrydę, która łączy elementy 3NF i modelu Kimballa. Jest to model oparty na zasadach relacyjnych, normalizacji danych i matematyce redundancji, który inaczej przedstawia relacje między jednostkami, a także inaczej konstruuje pola tabeli i znaczniki czasu.
W tej architekturze, wszystkie dane są przechowywane w surowym magazynie danych lub jeziorze danych, podczas gdy dane często używane są przechowywane w znormalizowanej postaci w magazynie biznesowym, który zawiera historyczne i kontekstowe informacje, przydatne w raportowaniu.
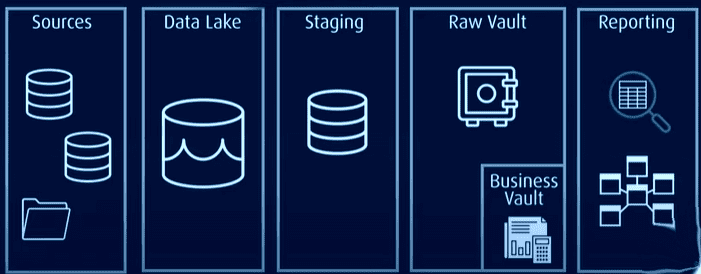
Data Vault rozwiązuje problemy występujące w tradycyjnych modelach, zapewniając większą wydajność, skalowalność i elastyczność. Umożliwia ładowanie danych w czasie zbliżonym do rzeczywistego, zwiększa integralność danych i pozwala na łatwą rozbudowę bez wpływu na istniejące struktury. Model można również rozbudowywać bez konieczności migracji istniejących tabel.
Podejście do modelowania | Struktura danych | Podejście projektowe
Modelowanie 3NF | Tabele w 3NF | Oddolne
Modelowanie Kimball | Schemat gwiazdy lub płatka śniegu | Odgórne
Data Vault | Hub-and-Spoke | Oddolne
Architektura Data Vault
Data Vault charakteryzuje się architekturą typu „hub-and-spoke” i składa się z trzech podstawowych warstw:
Warstwa pozyskiwania: odpowiedzialna za pobieranie surowych danych z systemów źródłowych, takich jak CRM czy ERP.
Warstwa hurtowni danych: W przypadku modelowania przy użyciu Data Vault, ta warstwa obejmuje:
- Surowy Data Vault: przechowuje surowe, nieprzetworzone dane.
- Biznesowy Data Vault: przechowuje zharmonizowane i przetworzone dane, oparte na regułach biznesowych (opcjonalnie).
- Metryczny Data Vault: przechowuje informacje o czasie przetwarzania (opcjonalnie).
- Magazyn operacyjny: przechowuje dane, które przepływają bezpośrednio z systemów operacyjnych do hurtowni danych (opcjonalnie).
Warstwa hurtowni danych tematycznych: ta warstwa modeluje dane w oparciu o schemat gwiazdy i/lub inne techniki modelowania, dostarczając informacji do analizy i raportowania.
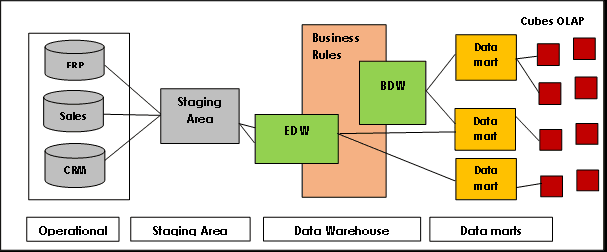 Źródło obrazu: Lamia Yessad
Źródło obrazu: Lamia Yessad
Data Vault nie wymaga zmian w architekturze. Nowe funkcjonalności mogą być budowane równolegle, bezpośrednio z wykorzystaniem koncepcji i metod Data Vault, bez ryzyka utraty istniejących komponentów. Frameworki mogą znacznie ułatwić proces implementacji, tworząc warstwę pomiędzy hurtownią danych a programistą, redukując tym samym złożoność wdrożenia.
Elementy składowe Data Vault
Podczas modelowania Data Vault, wszystkie informacje przypisane do danego obiektu są dzielone na trzy kategorie, odmiennie niż w klasycznym modelowaniu w trzeciej postaci normalnej. Informacje te są następnie przechowywane oddzielnie od siebie. Obszary funkcjonalne w Data Vault mapowane są na tzw. huby, linki i satelity:
#1. Huby
Huby stanowią serce koncepcji biznesowej, reprezentując kluczowe encje, takie jak klient, dostawca, sprzedaż lub produkt. Tabela centralna jest tworzona wokół klucza biznesowego (nazwa magazynu lub lokalizacja), gdy nowe wystąpienie tego klucza biznesowego po raz pierwszy trafia do hurtowni danych.
Hub nie zawiera informacji opisowych ani kluczy obcych. Składa się wyłącznie z klucza biznesowego wraz z wygenerowaną przez hurtownię sekwencją identyfikatorów, znacznikiem daty/czasu ładowania oraz źródłem rekordu.
#2. Linki
Linki definiują relacje między kluczami biznesowymi. Każdy wpis w linku modeluje relacje N:M pomiędzy dowolną liczbą hubów. Pozwala to hurtowni danych elastycznie reagować na zmiany w logice biznesowej systemów źródłowych, takie jak modyfikacje w kardynalności relacji. Podobnie jak hub, link nie zawiera żadnych informacji opisowych. Składa się z identyfikatorów sekwencji hubów, do których się odwołuje, identyfikatora sekwencji wygenerowanego przez magazyn, znacznika daty/godziny ładowania oraz źródła rekordu.
#3. Satelity
Satelity przechowują informacje opisowe (kontekst) dla klucza biznesowego przechowywanego w hubie lub relacji przechowywanej w linku. Satelity działają w trybie „tylko do wstawiania”, co oznacza, że cała historia danych jest przechowywana w satelicie. Wiele satelitów może opisywać pojedynczy klucz biznesowy (lub relację). Niemniej jednak, satelita może opisywać tylko jeden klucz (hub lub link).
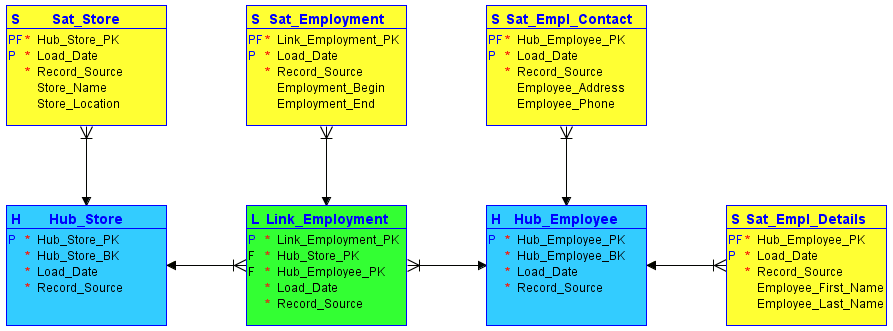 Źródło obrazu: Carbidfischer
Źródło obrazu: Carbidfischer
Jak zbudować model Data Vault?
Budowa modelu Data Vault obejmuje kilka kroków, z których każdy ma kluczowe znaczenie dla zapewnienia skalowalności, elastyczności i zgodności z potrzebami biznesowymi:
#1. Identyfikacja encji i atrybutów
Na początku należy zidentyfikować encje biznesowe oraz odpowiadające im atrybuty. Wymaga to ścisłej współpracy z interesariuszami biznesowymi w celu zrozumienia ich potrzeb i danych, które muszą być gromadzone. Po zidentyfikowaniu tych encji i atrybutów, należy je podzielić na huby, linki i satelity.
#2. Definicja relacji encji i tworzenie linków
Po zidentyfikowaniu encji i atrybutów, definiowane są relacje między encjami i tworzone są linki, które odzwierciedlają te relacje. Każdemu linkowi przypisywany jest klucz biznesowy, który identyfikuje relację pomiędzy encjami. Następnie dodawane są satelity w celu przechwycenia atrybutów i relacji encji.
#3. Ustalenie reguł i standardów
Po utworzeniu linków należy ustalić zbiór reguł i standardów modelowania Data Vault, aby zapewnić elastyczność modelu i jego zdolność do adaptacji w czasie. Reguły i standardy powinny być regularnie przeglądane i aktualizowane, aby były aktualne i zgodne z potrzebami biznesowymi.
#4. Wypełnienie modelu danymi
Po utworzeniu modelu należy go wypełnić danymi za pomocą metody ładowania przyrostowego. Polega to na ładowaniu danych do hubów, linków i satelitów przy użyciu obciążeń delta. Ładowanie różnicowe zapewnia, że ładowane są tylko zmiany w danych, co redukuje czas i zasoby potrzebne do integracji danych.
#5. Testowanie i weryfikacja modelu
Na koniec, model powinien zostać przetestowany i zweryfikowany, aby upewnić się, że spełnia wymagania biznesowe oraz jest wystarczająco skalowalny i elastyczny, aby sprostać przyszłym zmianom. Regularna konserwacja i aktualizacje powinny być przeprowadzane, aby upewnić się, że model pozostaje zgodny z potrzebami biznesowymi i nadal zapewnia ujednolicony widok danych.
Zasoby edukacyjne dotyczące Data Vault
Opanowanie koncepcji Data Vault może dostarczyć cennych umiejętności i wiedzy, która jest bardzo poszukiwana we współczesnych branżach opartych na danych. Poniżej znajduje się lista zasobów, w tym kursów i książek, które mogą pomóc w poznaniu zawiłości Data Vault:
#1. Modelowanie hurtowni danych z użyciem Data Vault 2.0

Ten kurs na platformie Udemy stanowi kompleksowe wprowadzenie do modelowania Data Vault 2.0, zwinnego zarządzania projektami oraz integracji Big Data. Kurs obejmuje podstawy Data Vault 2.0, włączając w to jego architekturę i warstwy, skarbce biznesowe i informacyjne oraz zaawansowane techniki modelowania.
Uczy on, jak zaprojektować model Data Vault od podstaw, konwertować tradycyjne modele, takie jak 3NF i modele wymiarowe, do Data Vault, oraz jak zrozumieć zasady modelowania wymiarowego w Data Vault. Kurs wymaga podstawowej wiedzy o bazach danych i języku SQL.
Z wysoką oceną 4,4 na 5 i ponad 1700 recenzjami, ten bestsellerowy kurs jest odpowiedni dla każdego, kto pragnie zbudować solidne podstawy w zakresie Data Vault 2.0 i integracji Big Data.
#2. Wyjaśnienie modelowania Data Vault za pomocą przypadków użycia

Ten kurs na Udemy ma na celu pomoc w budowie modelu Data Vault na podstawie praktycznego przykładu biznesowego. Służy on jako przewodnik dla początkujących w modelowaniu hurtowni danych, omawiając kluczowe pojęcia, takie jak odpowiednie scenariusze wykorzystania modeli Data Vault, ograniczenia tradycyjnego modelowania OLAP oraz systematyczne podejście do konstruowania modelu Data Vault. Kurs jest dostępny dla osób posiadających minimalną wiedzę o bazach danych.
#3. Data Vault Guru: pragmatyczny przewodnik
„Data Vault Guru” autorstwa Patricka Kuby to wszechstronny przewodnik po metodologii Data Vault, oferujący unikalną możliwość modelowania hurtowni danych przedsiębiorstwa z wykorzystaniem zasad automatyzacji podobnych do tych, które są stosowane w dostarczaniu oprogramowania.
Książka zawiera przegląd nowoczesnej architektury, a następnie oferuje szczegółowy przewodnik, jak dostarczyć elastyczny model danych, który dostosowuje się do zmian w przedsiębiorstwie i jego potrzebach. Ponadto, książka rozszerza metodologię Data Vault, zapewniając automatyczną korektę osi czasu, ścieżki audytu, kontrolę metadanych i integrację ze zwinnymi narzędziami do dostarczania.
#4. Budowanie skalowalnej hurtowni danych z Data Vault 2.0
Ta książka zawiera wyczerpujący przewodnik po tworzeniu skalowalnej hurtowni danych od początku do końca z wykorzystaniem metodologii Data Vault 2.0.
Książka omawia wszystkie istotne aspekty budowy skalowalnej hurtowni danych, włączając w to technikę modelowania Data Vault, która ma zapobiegać typowym awariom hurtowni danych. Książka zawiera liczne przykłady, które ułatwiają Czytelnikowi jasne zrozumienie omawianych koncepcji. Dzięki praktycznym spostrzeżeniom i przykładom z życia wziętym, książka ta jest niezbędnym źródłem informacji dla każdego, kto interesuje się tematyką hurtowni danych.
#5. Słoń w lodówce: przewodnik po krokach prowadzących do sukcesu Data Vault
„Słoń w lodówce” autorstwa Johna Gilesa to praktyczny przewodnik, którego celem jest pomoc czytelnikom w osiągnięciu sukcesu w Data Vault, rozpoczynając od potrzeb biznesowych i na nich kończąc. Książka skupia się na znaczeniu ontologii przedsiębiorstwa i modelowania koncepcji biznesowych, a także przedstawia wskazówki krok po kroku, jak zastosować te koncepcje w celu stworzenia solidnego modelu danych.
Dzięki praktycznym poradom i przykładom wzorców, autor oferuje jasne i nieskomplikowane wyjaśnienie skomplikowanych tematów, co sprawia, że książka jest doskonałym przewodnikiem dla osób, które dopiero rozpoczynają swoją przygodę z Data Vault.
Podsumowanie
Data Vault reprezentuje przyszłość hurtowni danych, oferując firmom znaczące korzyści w zakresie elastyczności, skalowalności i wydajności. Jest szczególnie odpowiedni dla firm, które potrzebują szybko ładować duże ilości danych, a także dla tych, które dążą do zwinnego rozwoju swoich aplikacji Business Intelligence.
Ponadto, firmy z istniejącą strukturą danych w silosach mogą czerpać znaczące korzyści z wdrożenia nadrzędnej hurtowni danych przy użyciu Data Vault.
Możesz być również zainteresowany zgłębieniem tematu pochodzenia danych.
newsblog.pl
Maciej – redaktor, pasjonat technologii i samozwańczy pogromca błędów w systemie Windows. Zna Linuxa lepiej niż własną lodówkę, a kawa to jego główne źródło zasilania. Pisze, testuje, naprawia – i czasem nawet wyłącza i włącza ponownie. W wolnych chwilach udaje, że odpoczywa, ale i tak kończy z laptopem na kolanach.