Wzmacnianie szybkości działania aplikacji często opiera się na mechanizmach buforowania. W poszukiwaniu optymalnych rozwiązań, Redis i Memcached jawią się jako jedne z najczęściej wybieranych opcji.
Jednak jak dokonać wyboru pomiędzy tymi dwoma potęgami? Ten poradnik ma za zadanie przybliżyć Ci możliwości każdego z nich, abyś mógł podjąć świadomą decyzję.
Niezależnie od tego, czy Twoim celem jest przyspieszenie aplikacji, zredukowanie obciążenia serwerów bazodanowych, czy też bezproblemowe skalowanie systemu, dogłębne zrozumienie mechanizmów buforowania jest kluczowe.
Zarówno Redis, jak i Memcached mogą być wykorzystywane jako rozwiązania buforujące, jednak różnią się swoimi charakterystykami. Obie zapewniają ultra-niskie opóźnienia (poniżej milisekundy) i wysoką przepustowość, lecz różnią się w kwestiach takich jak obsługa struktur danych i sposoby przechowywania informacji.
Zanim jednak szczegółowo przeanalizujemy Redis i Memcached, spójrzmy na samo buforowanie.
Na czym polega buforowanie i dlaczego jest tak istotne?
Każda operacja wykonywana przez aplikację zużywa zasoby systemowe. Może to być obciążenie procesora przy wykonywaniu zadań wymagających dużej mocy obliczeniowej, lub obciążenie sieci przy odczycie plików lub danych z bazy danych.
Powtarzanie tych samych zadań, obciążających procesor lub sieć, ma negatywny wpływ na wydajność. Wyobraź sobie, że wyszukujesz skomplikowane dane w bazie danych. Samo pobranie danych, jak i przygotowanie zapytania angażuje zasoby bazy danych, a czas wykonania operacji nie jest natychmiastowy.
Załóżmy, że wyniki zapytania nie zmieniają się między żądaniami. Mimo to za każdym razem wykonujesz to samo obciążające zapytanie. Czy istnieje alternatywa? Właśnie tu pojawia się buforowanie.
Buforowanie to w istocie przechowywanie często używanych danych w pamięci o szybkim dostępie, co umożliwia ich błyskawiczne odzyskanie. Dzięki temu nie trzeba powtarzać operacji pochłaniających dużo zasobów, takich jak zapytania do bazy danych czy skomplikowane obliczenia. W rezultacie zyskujemy poprawę wydajności, efektywności i responsywności systemu.
Oto najważniejsze korzyści płynące z buforowania:
- Redukcja opóźnień.
- Szybsze ładowanie i responsywność stron i aplikacji.
- Ograniczenie niepotrzebnego zużycia zasobów.
- Odciążenie serwerów.
- Ochrona bazy danych przed zbyt częstymi zapytaniami.
Redis: prezentacja

Redis to otwarty system przechowywania danych w pamięci, który bazuje na strukturze klucz-wartość. Może on służyć nie tylko jako pamięć podręczna, ale także jako baza danych, broker wiadomości, czy kolejka komunikatów.
Ponieważ Redis działa w pamięci RAM, czas dostępu do danych wynosi poniżej milisekundy. Pobieranie informacji z pamięci jest znacznie szybsze niż z dysku, co przekłada się na bardzo wysoką przepustowość i możliwość wykonywania wielu operacji odczytu i zapisu na sekundę.
W porównaniu do Memcached, Redis oferuje szeroki zakres struktur danych. Możesz przechowywać dane tekstowe lub binarne o wielkości do 512 MB w formie ciągów znaków. Obiekty możesz przechowywać jako pary pole-wartość, czyli Hasze, a kolekcje ciągów znaków jako listy, zbiory lub zbiory posortowane.
Redis wspiera biblioteki klienckie dla większości popularnych języków programowania takich jak Java, Python, Go, Node.js, C# i .Net. Dodatkowo instalując Redis, otrzymujesz narzędzie wiersza poleceń o nazwie redis-cli, które umożliwia weryfikację działania serwera oraz wysyłanie komend do odczytu, zapisu i modyfikacji danych.
Zalety Redisa
- Redis jest oprogramowaniem open source i dostępnym bezpłatnie.
- Dostępne są oficjalne biblioteki dla popularnych języków programowania.
- Może być używany jako rozwiązanie buforujące, broker wiadomości, baza danych lub kolejka.
- Charakteryzuje się bardzo wysoką wydajnością z opóźnieniami poniżej milisekundy.
- Oferuje wiele wbudowanych struktur danych, takich jak ciągi znaków, listy, zbiory i zbiory posortowane.
- Architektura replikacji typu master-slave zapewnia wysoką dostępność i skalowalność.
Teraz przyjrzyjmy się bliżej Memcached.
Memcached: prezentacja
Memcached to darmowy, otwarty system buforowania obiektów w pamięci, który cechuje się bardzo wysoką wydajnością. Oferuje on pamięć typu klucz-wartość dla małych porcji danych. Zanim jednak porównamy Redis i Memcached, zobaczmy dokładnie, czym jest Memcached.
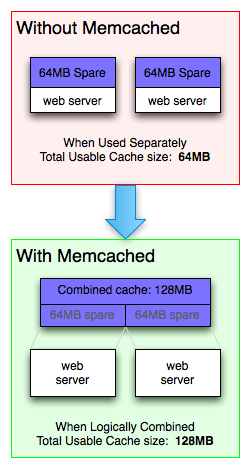
Pamięć w systemie komputerowym nie jest jednolita. Memcached pozwala na wykorzystanie dostępnej pamięci z różnych części systemu. Dzięki temu można pobierać pamięć tam, gdzie jest jej nadmiar i wykorzystywać tam, gdzie jest potrzebna.
Memcached jest prostym magazynem klucz-wartość, który nie analizuje struktury przechowywanych danych. Przechowuje on surowe, wstępnie serializowane dane wraz z kluczem, czasem wygaśnięcia i opcjonalnymi flagami. Nie zapewnia też obsługi wbudowanych struktur danych.
W przeciwieństwie do Redis, serwery Memcached nie komunikują się ze sobą. Nie oferuje on synchronizacji, replikacji ani emisji danych. Upraszcza to zarządzanie pamięcią podręczną, a klient może bezpośrednio usuwać lub nadpisywać dane na serwerze, który jest ich właścicielem.
Dzięki swojej prostocie Memcached zapewnia bardzo wysoką wydajność. Na wydajnym komputerze z szybką siecią, Memcached może bez problemu obsłużyć ponad 200 000 zapytań na sekundę.
Zalety Memcached
- Dzięki wykorzystaniu pamięci RAM, odczyt danych jest znacznie szybszy niż z tradycyjnego dysku.
- Dostępne są interfejsy API dla najpopularniejszych języków programowania.
- Memcached minimalizuje konieczność wielokrotnego wyszukiwania tych samych danych.
- Można buforować wyniki zapytań do bazy danych, odpowiedzi API, a nawet wyrenderowane strony internetowe.
- Pomaga w odzyskiwaniu fragmentarycznej pamięci.
- Wykorzystuje mechanizm buforowania LRU (Least Recently Used), a dane wygasają po określonym czasie.
- Umożliwia tworzenie własnych abstrakcji.
Teraz przeanalizujemy różnice pomiędzy Redis i Memcached.
Redis kontra Memcached: Tabela porównawcza
Funkcje | Redis | Memcached
—|—|—
Struktury danych | Obsługuje wbudowane struktury, takie jak ciągi, listy, zbiory, zbiory posortowane | Brak obsługi struktur danych. Przechowuje surowe, serializowane dane.
Rozmiar danych | Przechowywanie wartości do 512 MB | Przechowywanie wartości do 1 MB
Obsługa dysku | Natywna obsługa zapisywania na dysk przy użyciu RDB lub AOF | Brak natywnego zapisu na dysk. Narzędzia jak libmemcached-tools są opcjonalne
Wątki | Jednowątkowy | Wielowątkowy
Replikacja | Architektura master-slave umożliwia replikację | Brak wsparcia replikacji
Ewakuacja z pamięci podręcznej | LRU, możliwość konfiguracji | LRU
Języki programowania | Obsługa głównych języków | Obsługa głównych języków
Przejdźmy teraz do konkretnych zastosowań Redis i Memcached.
Zastosowania Redis i Memcached
#1. Obsługa handlu elektronicznego na dużą skalę: Shopify

Jeśli kiedykolwiek poszukiwałeś możliwości sprzedaży online, prawdopodobnie natknąłeś się na Shopify. Ta wielokanałowa platforma e-commerce pozwala na łatwe stworzenie sklepu internetowego. W szczytowym momencie Shopify obsługuje 80 000 zapytań na sekundę dla 600 000 sprzedawców. Obsługa tak dużego ruchu z minimalnymi opóźnieniami jest wyzwaniem.
Aby temu sprostać, Shopify wykorzystuje zarówno Memcached, jak i Redis. Jego architektura opiera się na MySQL jako bazie danych, Memcached jako magazynie klucz-wartość i Redis jako kolejce. Czasami najlepszym rozwiązaniem jest połączenie obu tych technologii w architekturze aplikacji.
W platformach e-commerce występuje wiele statycznych danych, które nie zmieniają się często, np. zdjęcia produktów, opisy i informacje o sklepie. Zamiast za każdym razem odpytywać bazę, przechowywanie tych danych w pamięci podręcznej przyspiesza działanie systemu i zwiększa jego wydajność.
Wykorzystanie Memcached do buforowania treści statycznych odciąża serwery i bazy danych.
#2. Rozproszone buforowanie danych aplikacji: Pinterest

Pinterest to popularna platforma, gdzie ludzie szukają inspiracji. Za kulisami każde żądanie przechodzi przez różne usługi i wymaga wielu obliczeń, włączając w to analizę pinów i rekomendacji.
Aby chronić usługi zaplecza przed obciążeniem i uniknąć powtarzania obliczeń, Pinterest wykorzystuje rozproszoną warstwę pamięci podręcznej. Przechowuje ona wyniki powtarzanych operacji, dzięki czemu żądania nie docierają do zasobożernych usług i baz danych. Pamięć podręczna Pinteresta składa się z tysięcy komputerów i obsługuje ponad 150 milionów zapytań na sekundę.
Pinterest wykorzystuje Memcached i mcrouter. Dzięki asynchronicznej i wielowątkowej obsłudze zdarzeń Memcached jest niezwykle wydajny. Jego prosta architektura umożliwia tworzenie własnych abstrakcji i skalowanie horyzontalne, co pozwala Pinterestowi obsłużyć tak duży ruch.
#3. Zarządzanie bezpieczeństwem danych na dużą skalę: CloudSponge
CloudSponge to usługa SaaS, która umożliwia użytkownikom szybkie wysyłanie zaproszeń, kuponów i kartek. Umożliwia importowanie kontaktów z różnych książek adresowych, eliminując konieczność ręcznego wpisywania adresów e-mail.
CloudSponge przetwarza prawie 2 biliony adresów e-mail rocznie. Wiąże się to z wyzwaniami dotyczącymi bezpieczeństwa, gdyż każda luka może narazić dane na kradzież.
Redis jest używany nie tylko jako pamięć podręczna, lecz również jako magazyn danych kontaktowych. Dane przechowywane są tak długo, jak klienci ich potrzebują, a potem są usuwane. Pomimo możliwości utrwalania danych na dysku, CloudSponge z tej opcji nie korzysta.
#4. Inne typowe zastosowania buforowania
Oto kilka dodatkowych przykładów wykorzystania buforowania:
❇️ Systemy przesyłania wiadomości na czacie
W systemach czatu buforowanie jest kluczowe. Pozwala przechowywać profile użytkowników, listy kontaktów i ostatnie wiadomości. Zmniejsza to obciążenie bazy danych i poprawia responsywność.
Buforowanie wspiera też funkcje działające w czasie rzeczywistym, takie jak wskaźniki pisania czy powiadomienia o obecności. Rozproszona pamięć podręczna ułatwia skalowanie serwerów bez konieczności rozbudowy pamięci.
❇️ Usługi lokalizacyjne
Aplikacje oparte na lokalizacji, które szacują odległość, czas przybycia lub proponują obiekty w pobliżu, korzystają z pamięci podręcznych dostosowanych do danych lokalizacyjnych. Dane zapisywane są jako indeksy geoprzestrzenne.
Indeks geoprzestrzenny umożliwia przechowywanie lokalizacji obiektów. Redis domyślnie obsługuje indeksy geoprzestrzenne, umożliwiając efektywne udostępnianie informacji o lokalizacji w czasie rzeczywistym.
❇️ Analityka w czasie rzeczywistym
Gry online i aplikacje sportowe często wymagają analiz w czasie rzeczywistym. Dzięki buforowaniu możliwe jest np. tworzenie rankingów. Aplikacje typu fantasy sports przechowują statystyki graczy w pamięci, co zwiększa wydajność aplikacji.
Które rozwiązanie wybrać?
Redis to wszechstronne rozwiązanie, które obsługuje różne struktury danych, dzięki czemu nadaje się do zaawansowanych aplikacji, które potrzebują więcej niż podstawowego buforowania. Opóźnienia poniżej milisekundy i wysoka przepustowość w połączeniu z obsługą bibliotek dla wielu języków programowania czynią z niego potężne narzędzie. Redis oferuje również natywne wsparcie utrwalania danych na dysku.
Z kolei Memcached wyróżnia się prostotą i szybkością buforowania. To idealny wybór do buforowania surowych, wstępnie serializowanych danych. Wykorzystuje on dostępną pamięć w różnych częściach systemu, a jego prosta architektura zapewnia bardzo wysoką wydajność, szczególnie w środowisku z szybką siecią.
Wybór pomiędzy Redis i Memcached powinien zależeć od złożoności aplikacji, wymagań dotyczących struktury danych i potrzeb skalowalności. Redis jest idealny tam, gdzie potrzebne są różnorodne struktury i bardziej zaawansowane funkcje, natomiast Memcached zapewnia najniższe opóźnienia i najwyższą przepustowość w prostych scenariuszach buforowania.
Ostatecznie decyzja o wyborze między Redis a Memcached powinna wynikać z konkretnych celów projektu. Czasami samo buforowanie danych aplikacji może okazać się niewystarczające.
Następnie dowiesz się, jak skonfigurować lokalny serwer buforujący DNS w systemie Linux.
newsblog.pl
Maciej – redaktor, pasjonat technologii i samozwańczy pogromca błędów w systemie Windows. Zna Linuxa lepiej niż własną lodówkę, a kawa to jego główne źródło zasilania. Pisze, testuje, naprawia – i czasem nawet wyłącza i włącza ponownie. W wolnych chwilach udaje, że odpoczywa, ale i tak kończy z laptopem na kolanach.