

Cóż, statystyki Forbesa podają, że aż 90% światowych organizacji wykorzystuje analitykę Big Data do tworzenia swoich raportów inwestycyjnych.
Wraz z rosnącą popularnością Big Data następuje większy niż wcześniej wzrost ofert pracy w Hadoop.
Dlatego też, aby pomóc Ci w zdobyciu roli eksperta Hadoop, możesz skorzystać z pytań i odpowiedzi do rozmowy kwalifikacyjnej, które zebraliśmy dla Ciebie w tym artykule, aby pomóc Ci przejść przez rozmowę kwalifikacyjną.
Być może znajomość faktów, takich jak zakres wynagrodzeń, który sprawia, że stanowiska Hadoop i Big Data są lukratywne, zmotywuje Cię do zdania tej rozmowy, prawda? 🤔
- Według Indeed.com, amerykański programista Big Data Hadoop zarabia średnio 144 000 USD.
- Według itjobswatch.co.uk średnia pensja programisty Big Data Hadoop wynosi 66 750 funtów.
- W Indiach źródło Indeed.com podaje, że zarabialiby średnio 16 000 000 funtów.
Dochodowe, nie sądzisz? A teraz przejdźmy do nauki o Hadoop.
Spis treści:
Co to jest Hadoop?
Hadoop to popularny framework napisany w Javie, który wykorzystuje modele programistyczne do przetwarzania, przechowywania i analizowania dużych zestawów danych.
Domyślnie jego konstrukcja umożliwia skalowanie z pojedynczych serwerów do wielu maszyn, które oferują lokalne obliczenia i przechowywanie. Ponadto jego zdolność do wykrywania i obsługi awarii warstwy aplikacji skutkujących usługami o wysokiej dostępności sprawia, że Hadoop jest dość niezawodny.
Przejdźmy od razu do często zadawanych pytań podczas rozmowy kwalifikacyjnej Hadoop i ich poprawnych odpowiedzi.
Wywiad z Hadoopem, pytania i odpowiedzi
Co to jest jednostka pamięci masowej w Hadoop?
Odpowiedź: Jednostka pamięci Hadoop nazywa się Hadoop Distributed File System (HDFS).
Czym różni się Network Attached Storage od rozproszonego systemu plików Hadoop?
Odpowiedź: HDFS, który jest podstawową pamięcią masową Hadoop, to rozproszony system plików, który przechowuje ogromne pliki przy użyciu zwykłego sprzętu. Z drugiej strony NAS to komputerowy serwer przechowywania danych na poziomie plików, który zapewnia heterogenicznym grupom klientów dostęp do danych.
Podczas gdy przechowywanie danych w NAS odbywa się na dedykowanym sprzęcie, HDFS dystrybuuje bloki danych na wszystkie maszyny w klastrze Hadoop.
NAS korzysta z wysokiej klasy urządzeń pamięci masowej, które są dość kosztowne, podczas gdy standardowy sprzęt używany w HDFS jest opłacalny.
NAS oddzielnie przechowuje dane z obliczeń, przez co nie nadaje się do MapReduce. Wręcz przeciwnie, konstrukcja HDFS pozwala na współpracę z frameworkiem MapReduce. Obliczenia przenoszą się do danych w strukturze MapReduce zamiast danych do obliczeń.
Wyjaśnij MapReduce w Hadoop i Shuffling
Odpowiedź: MapReduce odnosi się do dwóch odrębnych zadań, które programy Hadoop wykonują w celu umożliwienia dużej skalowalności od setek do tysięcy serwerów w klastrze Hadoop. Z drugiej strony tasowanie przenosi dane wyjściowe mapy z maperów do niezbędnego reduktora w MapReduce.
Rzuć okiem na architekturę Apache Pig
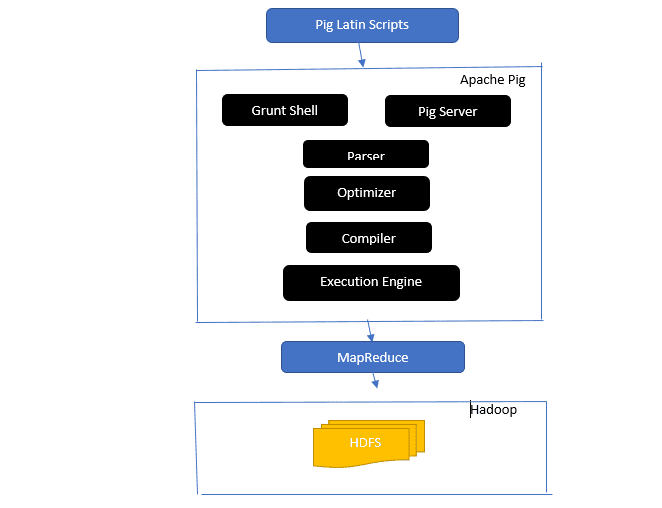 Architektura świni Apache
Architektura świni Apache
Odpowiedź: Architektura Apache Pig zawiera interpreter Pig Latin, który przetwarza i analizuje duże zbiory danych przy użyciu skryptów Pig Latin.
Świnka Apache składa się również z zestawów zestawów danych, na których wykonywane są operacje na danych, takie jak łączenie, ładowanie, filtrowanie, sortowanie i grupowanie.
Język Pig Latin wykorzystuje mechanizmy wykonawcze, takie jak powłoki Grant, UDF i osadzone do pisania skryptów Pig, które wykonują wymagane zadania.
Pig ułatwia pracę programistom, konwertując te napisane skrypty na serie zadań Map-Reduce.
Komponenty architektury Apache Pig obejmują:
- Parser – obsługuje skrypty świni, sprawdzając składnię skryptu i sprawdzając typ. Dane wyjściowe parsera reprezentują instrukcje i operatory logiczne Pig Latin i są nazywane DAG (directed acyclic graph).
- Optymalizator – Optymalizator implementuje logiczne optymalizacje, takie jak projekcja i naciskanie w DAG.
- Kompilator — kompiluje zoptymalizowany plan logiczny z optymalizatora do serii zadań MapReduce.
- Execution Engine – w tym miejscu następuje ostateczne wykonanie zadań MapReduce do żądanego wyniku.
- Tryb wykonania – Tryby wykonania w Apache pig obejmują głównie lokalne i Map Reduce.
Odpowiedź: Usługa Metastore w Local Metastore działa w tej samej maszynie JVM co Hive, ale łączy się z bazą danych działającą w oddzielnym procesie na tej samej lub zdalnej maszynie. Z drugiej strony Metastore w Remote Metastore działa w swojej JVM niezależnie od JVM usługi Hive.
Jakie są pięć V Big Data?
Odpowiedź: Te pięć V oznacza główne cechy Big Data. Zawierają:
- Wartość: Big Data ma na celu zapewnienie znaczących korzyści w postaci wysokiego zwrotu z inwestycji (ROI) organizacji, która wykorzystuje duże zbiory danych w swoich operacjach związanych z danymi. Big data wnosi tę wartość dzięki odkrywaniu wglądu i rozpoznawaniu wzorców, co skutkuje między innymi silniejszymi relacjami z klientami i skuteczniejszymi operacjami.
- Różnorodność: reprezentuje heterogeniczność typów gromadzonych danych. Różne formaty obejmują CSV, wideo, audio itp.
- Wolumen: określa znaczącą ilość i rozmiar danych zarządzanych i analizowanych przez organizację. Te dane przedstawiają wzrost wykładniczy.
- Prędkość: Jest to wykładnicza szybkość wzrostu danych.
- Wiarygodność: Wiarygodność odnosi się do tego, w jaki sposób dostępne dane „niepewne” lub „niedokładne” wynikają z niekompletności lub niespójności danych.
Wyjaśnij różne typy danych świńskiej łaciny.
Odpowiedź: Typy danych w Pig Latin obejmują atomowe typy danych i złożone typy danych.
Atomowe typy danych to podstawowe typy danych używane w każdym innym języku. Obejmują one:
- Int — ten typ danych definiuje 32-bitową liczbę całkowitą ze znakiem. Przykład: 13
- Long — Long definiuje 64-bitową liczbę całkowitą. Przykład: 10 l
- Float — definiuje 32-bitową liczbę zmiennoprzecinkową ze znakiem. Przykład: 2,5 F
- Double — definiuje podpisany 64-bitowy zmiennoprzecinkowy. Przykład: 23.4
- Boolean – definiuje wartość logiczną. Zawiera: Prawda/Fałsz
- Datetime — definiuje wartość daty i godziny. Przykład: 1980-01-01T00:00.00.000+00:00
Złożone typy danych obejmują:
- Mapa- mapa odnosi się do zestawu par klucz-wartość. Przykład: [‘color’#’yellow’, ‘number’#3]
- Torba – Jest to zbiór zbioru krotek i używa symbolu „{}”. Przykład: {(Henryk, 32), (Kiti, 47)}
- Krotka — krotka definiuje uporządkowany zestaw pól. Przykład : (wiek, 33 lata)
Czym są Apache Oozie i Apache ZooKeeper?
Odpowiedź: Apache Oozie to program planujący Hadoop odpowiedzialny za planowanie i łączenie zadań Hadoop w jedną pracę logiczną.
Z drugiej strony Apache Zookeeper współpracuje z różnymi usługami w środowisku rozproszonym. Oszczędza czas programistów, po prostu ujawniając proste usługi, takie jak synchronizacja, grupowanie, konserwacja konfiguracji i nazewnictwo. Apache Zookeeper zapewnia również gotowe wsparcie dla kolejkowania i wyboru lidera.
Jaka jest rola Combiner, RecordReader i Partitioner w operacji MapReduce?
Odpowiedź: Sumator działa jak mini reduktor. Otrzymuje i pracuje na danych z zadań mapowych, a następnie przekazuje dane wyjściowe do fazy reduktora.
RecordHeader komunikuje się z InputSplit i konwertuje dane na pary klucz-wartość, aby program odwzorowujący mógł je odpowiednio odczytać.
Partitioner jest odpowiedzialny za podjęcie decyzji o liczbie zredukowanych zadań wymaganych do podsumowania danych i potwierdzenie, w jaki sposób wyjścia sumatora są wysyłane do reduktora. Partitioner kontroluje również partycjonowanie kluczy pośrednich danych wyjściowych mapy.
Wspomnij o różnych dystrybucjach Hadoop specyficznych dla dostawców.
Odpowiedź: Różni dostawcy rozszerzający możliwości Hadoop to:
- Otwarta platforma IBM.
- Dystrybucja Cloudera CDH Hadoop
- Dystrybucja MapR Hadoop
- Amazon Elastic MapReduce
- Platforma danych Hortonworks (HDP)
- Kluczowy pakiet Big Data
- Datastax Enterprise Analytics
- Usługa HDInsight platformy Microsoft Azure — oparta na chmurze dystrybucja Hadoop.
Dlaczego HDFS jest odporny na błędy?
Odpowiedź: System HDFS replikuje dane w różnych węzłach danych, dzięki czemu jest odporny na błędy. Przechowywanie danych w różnych węzłach umożliwia pobieranie z innych węzłów w przypadku awarii jednego z trybów.
Rozróżnienie między federacją a wysoką dostępnością.
Odpowiedź: Federacja HDFS oferuje odporność na awarie, która umożliwia ciągły przepływ danych w jednym węźle, gdy inny ulegnie awarii. Z drugiej strony Wysoka dostępność będzie wymagać dwóch oddzielnych maszyn konfigurujących aktywny NameNode i dodatkowy NameNode na pierwszym i drugim komputerze oddzielnie.
Federacja może mieć nieograniczoną liczbę niepowiązanych węzłów nazw, podczas gdy w przypadku wysokiej dostępności dostępne są tylko dwa powiązane węzły nazw, aktywny i rezerwowy, które działają nieprzerwanie.
Węzły nazw w federacji współużytkują pulę metadanych, przy czym każdy węzeł nazw ma swoją dedykowaną pulę. Jednak w przypadku wysokiej dostępności aktywne węzły nazw działają pojedynczo, podczas gdy rezerwowe węzły nazw pozostają bezczynne i tylko od czasu do czasu aktualizują swoje metadane.
Jak znaleźć stan bloków i stan systemu plików?
Odpowiedź: Aby sprawdzić stan systemu plików HDFS, użyj polecenia hdfs fsck / zarówno na poziomie użytkownika root, jak iw pojedynczym katalogu.
Używane polecenie HDFS fsck:
hdfs fsck / -files --blocks –locations> dfs-fsck.log
Opis polecenia:
- -files: Wydrukuj sprawdzane pliki.
- –lokalizacje: Drukuje lokalizacje wszystkich bloków podczas sprawdzania.
Polecenie sprawdzenia stanu bloków:
hdfs fsck <path> -files -blocks
- <ścieżka>: Rozpoczyna sprawdzanie od podanej tutaj ścieżki.
- – bloki: Drukuje bloki pliku podczas sprawdzania
Kiedy używasz poleceń rmadmin-refreshNodes i dfsadmin-refreshNodes?
Odpowiedź: Te dwa polecenia są pomocne przy odświeżaniu informacji o węźle podczas uruchamiania lub po zakończeniu uruchamiania węzła.
Polecenie dfsadmin-refreshNodes uruchamia klienta HDFS i odświeża konfigurację węzła NameNode. Z drugiej strony polecenie rmadmin-refreshNodes wykonuje zadania administracyjne ResourceManager.
Co to jest punkt kontrolny?
Odpowiedź: Punkt kontrolny to operacja, która łączy ostatnie zmiany w systemie plików z najnowszym FSImage, dzięki czemu pliki dziennika edycji pozostają wystarczająco małe, aby przyspieszyć proces uruchamiania NameNode. Punkt kontrolny występuje w Secondary NameNode.
Dlaczego używamy systemu plików HDFS w aplikacjach z dużymi zbiorami danych?
Odpowiedź: HDFS zapewnia architekturę DataNode i NameNode, która implementuje rozproszony system plików.
Te dwie architektury zapewniają wysokowydajny dostęp do danych za pośrednictwem wysoce skalowalnych klastrów Hadoop. Jego NameNode przechowuje metadane systemu plików w pamięci RAM, co powoduje, że ilość pamięci ogranicza liczbę plików systemu plików HDFS.
Co robi polecenie „jps”?
Odpowiedź: Polecenie Java Virtual Machine Process Status (JPS) sprawdza, czy działają określone demony usługi Hadoop, w tym NodeManager, DataNode, NameNode i ResourceManager. To polecenie jest wymagane do uruchomienia z poziomu katalogu głównego w celu sprawdzenia działających węzłów w hoście.
Co to jest „wykonanie spekulacyjne” w Hadoop?
Odpowiedź: Jest to proces, w którym główny węzeł w Hadoop, zamiast naprawiać wykryte powolne zadania, uruchamia inną instancję tego samego zadania jako zadanie tworzenia kopii zapasowej (zadanie spekulacyjne) na innym węźle. Wykonanie spekulacyjne pozwala zaoszczędzić dużo czasu, zwłaszcza w środowisku o dużym obciążeniu pracą.
Wymień trzy tryby, w których Hadoop może działać.
Odpowiedź: Trzy główne węzły, na których działa Hadoop, to:
- Węzeł autonomiczny to tryb domyślny, który uruchamia usługi Hadoop przy użyciu lokalnego systemu plików i pojedynczego procesu Java.
- Pseudo-rozproszony węzeł wykonuje wszystkie usługi Hadoop przy użyciu jednego wdrożenia Hadoop ode.
- W pełni rozproszony węzeł obsługuje usługi główne i podrzędne Hadoop przy użyciu oddzielnych węzłów.
Co to jest UDF?
Odpowiedź: UDF (funkcje zdefiniowane przez użytkownika) umożliwia kodowanie niestandardowych funkcji, których można używać do przetwarzania wartości kolumn podczas zapytania Impala.
Co to jest DistCp?
Odpowiedź: DistCp lub Distributed Copy, w skrócie, jest użytecznym narzędziem do kopiowania dużych danych między klastrami lub wewnątrz klastra. Korzystając z MapReduce, DistCp skutecznie wdraża rozproszoną kopię dużej ilości danych, między innymi zadaniami, takimi jak obsługa błędów, odzyskiwanie i raportowanie.
Odpowiedź: Hive metastore to usługa, która przechowuje metadane Apache Hive dla tabel Hive w relacyjnej bazie danych, takiej jak MySQL. Zapewnia interfejs API usługi magazynu metadanych, który umożliwia centowy dostęp do metadanych.
Zdefiniuj RDD.
Odpowiedź: RDD, co oznacza Resilient Distributed Datasets, to struktura danych Sparka i niezmienny rozproszony zbiór elementów danych, który jest obliczany na różnych węzłach klastra.
W jaki sposób można uwzględnić biblioteki natywne w zadaniach YARN?
Odpowiedź: Możesz to zaimplementować, używając -Djava.library. path w poleceniu lub ustawiając LD+LIBRARY_PATH w pliku .bashrc w następującym formacie:
<property> <name>mapreduce.map.env</name> <value>LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/path/to/my/libs</value> </property>
Wyjaśnij „WAL” w HBase.
Odpowiedź: Dziennik zapisu z wyprzedzeniem (WAL) to protokół odzyskiwania, który rejestruje zmiany danych MemStore w HBase w magazynie opartym na plikach. WAL odzyskuje te dane, jeśli RegionalServer ulegnie awarii lub przed opróżnieniem MemStore.
Czy YARN zastępuje Hadoop MapReduce?
Odpowiedź: Nie, YARN nie jest zamiennikiem Hadoop MapReduce. Zamiast tego zaawansowana technologia o nazwie Hadoop 2.0 lub MapReduce 2 obsługuje MapReduce.
Jaka jest różnica między ORDER BY a SORT BY w HIVE?
Odpowiedź: Podczas gdy oba polecenia pobierają dane w Hive w sposób posortowany, wyniki użycia SORTUJ WEDŁUG mogą być uporządkowane tylko częściowo.
Ponadto SORTOWANIE WEDŁUG wymaga reduktora w celu uporządkowania wierszy. Te reduktory wymagane do końcowego wyniku mogą być również wielokrotne. W takim przypadku produkt końcowy może być częściowo uporządkowany.
Z drugiej strony ORDER BY wymaga tylko jednego reduktora dla całkowitego zamówienia na wyjściu. Możesz także użyć słowa kluczowego LIMIT, które skraca całkowity czas sortowania.
Jaka jest różnica między Spark a Hadoop?
Odpowiedź: Chociaż zarówno Hadoop, jak i Spark to struktury przetwarzania rozproszonego, kluczową różnicą między nimi jest przetwarzanie. Tam, gdzie Hadoop jest wydajny do przetwarzania wsadowego, Spark jest wydajny do przetwarzania danych w czasie rzeczywistym.
Dodatkowo Hadoop głównie odczytuje i zapisuje pliki w HDFS, podczas gdy Spark wykorzystuje koncepcję Resilient Distributed Dataset do przetwarzania danych w pamięci RAM.
Opierając się na ich opóźnieniach, Hadoop to platforma obliczeniowa o dużym opóźnieniu bez interaktywnego trybu przetwarzania danych, podczas gdy Spark to platforma obliczeniowa o niskim opóźnieniu, która interaktywnie przetwarza dane.
Porównaj Sqoop i Flume.
Odpowiedź: Sqoop i Flume to narzędzia Hadoop, które zbierają dane zebrane z różnych źródeł i ładują je do HDFS.
- Sqoop (SQL-to-Hadoop) wyodrębnia ustrukturyzowane dane z baz danych, w tym Teradata, MySQL, Oracle itp., podczas gdy Flume jest przydatny do wyodrębniania nieustrukturyzowanych danych ze źródeł baz danych i ładowania ich do HDFS.
- Jeśli chodzi o zdarzenia sterowane, Flume jest sterowany zdarzeniami, podczas gdy Sqoop nie jest sterowany zdarzeniami.
- Sqoop wykorzystuje architekturę opartą na konektorach, w której konektory wiedzą, jak połączyć się z innym źródłem danych. Flume wykorzystuje architekturę opartą na agencie, a napisany kod jest agentem odpowiedzialnym za pobieranie danych.
- Ze względu na rozproszony charakter Flume może łatwo gromadzić i agregować dane. Sqoop jest przydatny do równoległego przesyłania danych, co powoduje, że dane wyjściowe znajdują się w wielu plikach.
Wyjaśnij plik BloomMapFile.
Odpowiedź: BloomMapFile jest klasą rozszerzającą klasę MapFile i wykorzystuje dynamiczne filtry Bloom, które zapewniają szybki test członkostwa dla kluczy.
Wypisz różnicę między HiveQL a PigLatin.
Odpowiedź: Podczas gdy HiveQL jest językiem deklaratywnym podobnym do SQL, PigLatin jest proceduralnym językiem przepływu danych wysokiego poziomu.
Co to jest czyszczenie danych?
Odpowiedź: Oczyszczanie danych to kluczowy proces usuwania lub naprawiania zidentyfikowanych błędów danych, które obejmują nieprawidłowe, niekompletne, uszkodzone, zduplikowane i źle sformatowane dane w zbiorze danych.
Proces ten ma na celu poprawę jakości danych oraz dostarczenie dokładniejszych, spójniejszych i rzetelniejszych informacji niezbędnych do sprawnego podejmowania decyzji w organizacji.
Wniosek💃
Przy obecnym wzroście ofert pracy w Big Data i Hadoop możesz chcieć zwiększyć swoje szanse na dostanie się do pracy. Pytania i odpowiedzi na rozmowę kwalifikacyjną w Hadoop zawarte w tym artykule pomogą ci wygrać nadchodzącą rozmowę kwalifikacyjną.
Następnie możesz sprawdzić dobre zasoby do nauki Big Data i Hadoop.
Powodzenia! 👍