

1 września 2020 roku firma NVIDIA ujawniła swoją nową linię procesorów graficznych do gier: serię RTX 3000, opartą na architekturze Ampere. Omówimy nowości, dołączone oprogramowanie oparte na sztucznej inteligencji i wszystkie szczegóły, które sprawiają, że to pokolenie jest naprawdę niesamowite.
Spis treści:
Poznaj procesory graficzne z serii RTX 3000

Główną zapowiedzią firmy NVIDIA były nowe, lśniące układy GPU, wszystkie zbudowane w niestandardowym procesie produkcyjnym 8 nm i wszystkie zapewniające znaczne przyspieszenie zarówno w zakresie rasteryzacji, jak i śledzenia promieni.
Na najniższym końcu zestawu znajduje się plik RTX 3070, która kosztuje 499 USD. Jest to trochę drogie jak na najtańszą kartę ujawnioną przez NVIDIA w pierwszym ogłoszeniu, ale to absolutna kradzież, gdy dowiesz się, że pokonuje istniejący RTX 2080 Ti, najwyższą kartę z linii, która regularnie sprzedawana jest za ponad 1400 USD. Jednak po ogłoszeniu przez firmę NVIDIA ceny sprzedaży stron trzecich spadły, a wiele z nich zostało sprzedanych w panice w serwisie eBay za mniej niż 600 USD.
W momencie ogłoszenia nie ma żadnych solidnych testów porównawczych, więc nie jest jasne, czy karta jest naprawdę obiektywnie „lepsza” niż 2080 Ti, czy też NVIDIA trochę przekręca marketing. Testy porównawcze były w rozdzielczości 4K i prawdopodobnie miały włączony RTX, co może sprawić, że różnica będzie wyglądać na większą niż w grach czysto rasteryzowanych, ponieważ seria 3000 oparta na Ampere będzie działać ponad dwukrotnie lepiej w ray tracingu niż Turing. Ale ponieważ ray tracing jest teraz czymś, co nie szkodzi zbytnio wydajności i jest obsługiwany w konsolach najnowszej generacji, głównym punktem sprzedaży jest to, aby działał tak szybko, jak flagowiec ostatniej generacji za prawie jedną trzecią ceny.
Nie jest również jasne, czy cena pozostanie na tym poziomie. Projekty innych firm regularnie dodają co najmniej 50 USD do ceny, a biorąc pod uwagę, jak wysoki będzie popyt, nie będzie zaskakujące, że w październiku 2020 r. Będzie sprzedawany za 600 USD.
Tuż nad tym jest RTX 3080 kosztuje 699 USD, co powinno być dwa razy szybsze niż RTX 2080 i około 25-30% szybciej niż 3080.
Następnie u góry nowym okrętem flagowym jest RTX 3090, co jest komicznie ogromne. Firma NVIDIA jest tego świadoma i nazywa ją „BFGPU”, co według firmy oznacza „Big Ferocious GPU”.

NVIDIA nie przedstawiła żadnych bezpośrednich wskaźników wydajności, ale firma pokazała, że działa w 8K gier przy 60 FPS, co jest naprawdę imponujące. To prawda, NVIDIA prawie na pewno używa DLSS, aby osiągnąć ten cel, ale gry 8K to gry 8K.
Oczywiście ostatecznie pojawi się 3060 i inne odmiany kart bardziej zorientowanych na budżet, ale te zwykle pojawiają się później.
Aby faktycznie wszystko schłodzić, NVIDIA potrzebowała odświeżonego, fajniejszego projektu. Model 3080 jest oceniany na 320 watów, co jest dość wysokie, więc NVIDIA zdecydowała się na konstrukcję z dwoma wentylatorami, ale zamiast dwóch wentylatorów vwinf umieszczonych na dole, NVIDIA umieściła wentylator na górnym końcu, gdzie zwykle idzie tylna płyta. Wentylator kieruje powietrze w górę w kierunku chłodnicy procesora i górnej części obudowy.

Sądząc po tym, na ile wydajność może wpłynąć zły przepływ powietrza w etui, ma to sens. Jednak płytka drukowana jest z tego powodu bardzo ciasna, co prawdopodobnie wpłynie na ceny sprzedaży stron trzecich.
DLSS: zaleta oprogramowania
Śledzenie promieni to nie jedyna zaleta tych nowych kart. Naprawdę, to trochę hack – seria RTX 2000 i seria 3000 nie jest dużo lepsza w wykonywaniu rzeczywistego ray tracingu w porównaniu ze starszymi generacjami kart. Śledzenie promieni pełnych scen w oprogramowaniu 3D, takim jak Blender, zwykle zajmuje kilka sekund lub nawet minut na klatkę, więc brutalne forsowanie go w czasie poniżej 10 milisekund jest wykluczone.
Oczywiście istnieje dedykowany sprzęt do wykonywania obliczeń promieni, zwany rdzeniami RT, ale w dużej mierze NVIDIA zdecydowała się na inne podejście. Firma NVIDIA ulepszyła algorytmy odszumiania, które pozwalają procesorom graficznym renderować bardzo tani pojedynczy przebieg, który wygląda okropnie, i w jakiś sposób – dzięki magii sztucznej inteligencji – przekształcić to w coś, na co gracz chce spojrzeć. W połączeniu z tradycyjnymi technikami opartymi na rasteryzacji zapewnia przyjemne wrażenia wzmocnione efektami ray tracingu.

Jednak aby zrobić to szybko, firma NVIDIA dodała rdzenie przetwarzające specyficzne dla sztucznej inteligencji zwane rdzeniami Tensor. Przetwarzają one całą matematykę wymaganą do uruchamiania modeli uczenia maszynowego i robią to bardzo szybko. Są w sumie Zmieniacz gry dla AI w przestrzeni serwera w chmurze, ponieważ sztuczna inteligencja jest szeroko stosowana przez wiele firm.
Oprócz odszumiania, głównym zastosowaniem rdzeni Tensor dla graczy jest DLSS lub superpróbkowanie głębokiego uczenia. Przyjmuje klatkę o niskiej jakości i skaluje ją do pełnej jakości natywnej. Zasadniczo oznacza to, że możesz grać z liczbą klatek na sekundę 1080p, patrząc na obraz 4K.
Pomaga to również w działaniu śledzenia promieni –testy porównawcze z PCMag pokaż RTX 2080 Super Running Control w ultra jakości, z wszystkimi ustawieniami ray tracingu ustawionymi na maksa. W 4K boryka się tylko z 19 FPS, ale z włączonym DLSS uzyskuje znacznie lepsze 54 FPS. DLSS to darmowa wydajność dla NVIDII, możliwa dzięki rdzeniom Tensor w Turing i Ampere. Każda gra, która to obsługuje i jest ograniczona do GPU, może zobaczyć poważne przyspieszenia tylko z samego oprogramowania.
DLSS nie jest nowe i zostało ogłoszone jako funkcja, gdy seria RTX 2000 została wypuszczona dwa lata temu. W tamtym czasie był obsługiwany przez bardzo niewiele gier, ponieważ wymagał od firmy NVIDIA trenowania i dostrajania modelu uczenia maszynowego dla każdej gry.
Jednak w tym czasie NVIDIA całkowicie go przepisała, nazywając nową wersję DLSS 2.0. Jest to interfejs API ogólnego przeznaczenia, co oznacza, że każdy programista może go zaimplementować i jest już dostępny w większości głównych wydań. Zamiast pracować na jednej klatce, pobiera w ruchu dane wektorowe z poprzedniej klatki, podobnie jak TAA. Rezultat jest znacznie ostrzejszy niż DLSS 1.0, aw niektórych przypadkach faktycznie wygląda lepiej i ostrzej niż nawet rozdzielczość natywna, więc nie ma powodu, aby go nie włączać.
Jest jeden haczyk – podczas całkowitego przełączania scen, tak jak w przerywnikach filmowych, DLSS 2.0 musi renderować pierwszą klatkę z jakością 50%, czekając na dane wektora ruchu. Może to spowodować niewielki spadek jakości na kilka milisekund. Ale 99% wszystkiego, na co patrzysz, zostanie wyrenderowane poprawnie, a większość ludzi nie zauważa tego w praktyce.
Architektura Ampere: stworzona dla sztucznej inteligencji
Ampere jest szybki. Poważnie szybki, zwłaszcza przy obliczeniach AI. Rdzeń RT jest 1,7x szybszy niż Turing, a nowy rdzeń Tensor jest 2,7x szybszy niż Turing. Połączenie tych dwóch elementów to prawdziwy skok pokoleniowy w wydajności śledzenia promieni.

Wcześniej w maju tego roku NVIDIA wypuściła procesor graficzny Ampere A100, procesor graficzny dla centrum danych przeznaczony do obsługi sztucznej inteligencji. Dzięki niemu szczegółowo opisali, co sprawia, że Ampere jest o wiele szybszy. W przypadku centrów danych i obciążeń obliczeniowych o wysokiej wydajności Ampere jest generalnie około 1,7 raza szybszy niż Turing. W przypadku treningu AI jest do 6 razy szybszy.
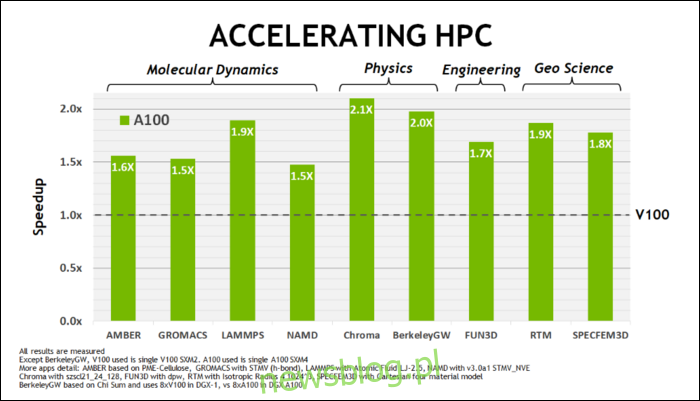
W przypadku Ampere firma NVIDIA używa nowego formatu liczb, zaprojektowanego w celu zastąpienia w niektórych obciążeniach standardu branżowego „32 zmiennoprzecinkowe” lub FP32. Pod maską każda liczba przetwarzana przez komputer zajmuje wstępnie zdefiniowaną liczbę bitów w pamięci, niezależnie od tego, czy jest to 8 bitów, 16 bitów, 32, 64 czy nawet więcej. Liczby, które są większe, są trudniejsze do przetworzenia, więc jeśli możesz użyć mniejszego rozmiaru, będziesz miał mniej do zgryzienia.
FP32 przechowuje 32-bitową liczbę dziesiętną i używa 8 bitów dla zakresu liczby (jak duża lub mała może być) i 23 bitów dla precyzji. Firma NVIDIA twierdzi, że te 23 precyzyjne bity nie są całkowicie konieczne dla wielu obciążeń sztucznej inteligencji i można uzyskać podobne wyniki i znacznie lepszą wydajność z zaledwie 10 z nich. Zmniejszenie rozmiaru do zaledwie 19 bitów zamiast 32 powoduje dużą różnicę w wielu obliczeniach.
Ten nowy format nazywa się Tensor Float 32, a rdzenie Tensor w A100 są zoptymalizowane do obsługi formatu o dziwnych rozmiarach. Oznacza to, że oprócz kurczenia się matrycy i wzrostu liczby rdzeni, uzyskują ogromne 6-krotne przyspieszenie w treningu AI.

Oprócz nowego formatu liczb, Ampere obserwuje znaczne przyspieszenie wydajności w określonych obliczeniach, takich jak FP32 i FP64. Nie przekładają się one bezpośrednio na większą liczbę klatek na sekundę dla laika, ale są częścią tego, co sprawia, że jest prawie trzy razy szybszy w operacjach Tensora.

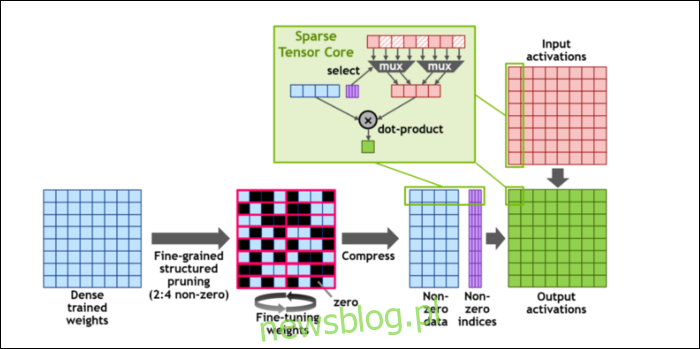
Następnie, aby jeszcze bardziej przyspieszyć obliczenia, wprowadzili koncepcję drobnoziarnista struktura rzadka, co jest bardzo wymyślnym słowem na dość prostą koncepcję. Sieci neuronowe działają z dużymi listami liczb, zwanymi wagami, które mają wpływ na ostateczny wynik. Im więcej liczb do zgryzienia, tym wolniej będzie.
Jednak nie wszystkie z tych liczb są w rzeczywistości przydatne. Niektóre z nich są dosłownie zerowe i można je w zasadzie wyrzucić, co prowadzi do ogromnych przyspieszeń, gdy możesz zgnieść więcej liczb w tym samym czasie. Rzadkość zasadniczo kompresuje liczby, co wymaga mniej wysiłku przy wykonywaniu obliczeń. Nowy „Sparse Tensor Core” jest zbudowany do działania na skompresowanych danych.
Pomimo zmian, NVIDIA twierdzi, że nie powinno to w żaden sposób wpłynąć na dokładność trenowanych modeli.
W przypadku rzadkich obliczeń INT8, jednego z najmniejszych formatów liczb, szczytowa wydajność pojedynczego GPU A100 wynosi ponad 1,25 PetaFLOP, co jest oszałamiająco wysoką liczbą. Oczywiście dzieje się tak tylko podczas obliczania jednego konkretnego rodzaju liczby, ale mimo to robi wrażenie.