

Przetwarzanie dużych zbiorów danych to jedna z najbardziej złożonych procedur, z jakimi borykają się organizacje. Proces staje się bardziej skomplikowany, gdy masz dużą ilość danych w czasie rzeczywistym.
W tym poście dowiemy się, czym jest przetwarzanie big data, jak to się robi, oraz poznamy Apache Kafka i Spark – dwa z najbardziej znanych narzędzi do przetwarzania danych!
Spis treści:
Co to jest przetwarzanie danych? Jak to jest zrobione?
Przetwarzanie danych jest definiowane jako dowolna operacja lub zestaw operacji, niezależnie od tego, czy są przeprowadzane w sposób zautomatyzowany, czy też nie. Można ją traktować jako zbieranie, porządkowanie i organizowanie informacji zgodnie z logiczną i odpowiednią dyspozycją do interpretacji.
Gdy użytkownik uzyskuje dostęp do bazy danych i otrzymuje wyniki wyszukiwania, to przetwarzanie danych zapewnia mu potrzebne wyniki. Informacje wyodrębnione jako wynik wyszukiwania są wynikiem przetwarzania danych. Dlatego technologia informacyjna koncentruje się na przetwarzaniu danych.
Tradycyjne przetwarzanie danych odbywało się za pomocą prostego oprogramowania. Jednak wraz z pojawieniem się Big Data sytuacja się zmieniła. Big Data to informacje, których objętość może przekraczać sto terabajtów i petabajtów.
Ponadto informacje te są regularnie aktualizowane. Przykładami są dane pochodzące z contact center, mediów społecznościowych, danych giełdowych itp. Takie dane są czasami nazywane strumieniem danych – stałym, niekontrolowanym strumieniem danych. Jego główną cechą jest to, że dane nie mają określonych limitów, więc nie można powiedzieć, kiedy strumień się zaczyna lub kończy.
Dane są przetwarzane w momencie dotarcia do miejsca docelowego. Niektórzy autorzy nazywają to przetwarzaniem w czasie rzeczywistym lub online. Innym podejściem jest przetwarzanie blokowe, wsadowe lub offline, w którym bloki danych są przetwarzane w oknach czasowych godzin lub dni. Często partia to proces, który działa w nocy, konsolidując dane z danego dnia. Zdarzają się przypadki, gdy okna czasowe tygodnia lub nawet miesiąca generują nieaktualne raporty.
Biorąc pod uwagę, że najlepszymi platformami przetwarzania Big Data za pośrednictwem strumieniowania są otwarte źródła, takie jak Kafka i Spark, platformy te umożliwiają korzystanie z innych, różnych i uzupełniających się. Oznacza to, że będąc open source, ewoluują szybciej i wykorzystują więcej narzędzi. W ten sposób strumienie danych są odbierane z innych miejsc ze zmienną szybkością i bez żadnych przerw.
Teraz przyjrzymy się dwóm najbardziej znanym narzędziom do przetwarzania danych i porównamy je:
Apache Kafka
Apache Kafka to system przesyłania wiadomości, który tworzy aplikacje strumieniowe z ciągłym przepływem danych. Pierwotnie stworzona przez LinkedIn, Kafka jest oparta na dziennikach; dziennik jest podstawową formą przechowywania, ponieważ każda nowa informacja jest dodawana na końcu pliku.

Kafka to jedno z najlepszych rozwiązań dla big data, ponieważ jego główną cechą jest wysoka przepustowość. Dzięki Apache Kafka możliwe jest nawet przekształcenie przetwarzania wsadowego w czasie rzeczywistym,
Apache Kafka to system przesyłania wiadomości typu publikuj-subskrybuj, w którym aplikacja publikuje, a aplikacja subskrybująca otrzymuje wiadomości. Czas między opublikowaniem a odebraniem wiadomości może wynosić milisekundy, więc rozwiązanie Kafki ma małe opóźnienia.
Praca Kafki
Architektura Apache Kafka obejmuje producentów, konsumentów oraz sam klaster. Producentem jest dowolna aplikacja, która publikuje komunikaty w klastrze. Konsumentem jest dowolna aplikacja, która otrzymuje wiadomości od Kafki. Klaster Kafka to zestaw węzłów, które działają jako pojedyncza instancja usługi przesyłania wiadomości.
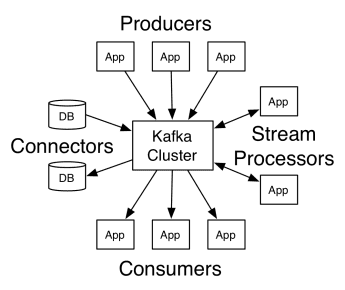 Praca Kafki
Praca Kafki
Klaster Kafka składa się z kilku brokerów. Broker to serwer Kafka, który odbiera komunikaty od producentów i zapisuje je na dysku. Każdy broker zarządza listą tematów, a każdy temat jest podzielony na kilka partycji.
Po odebraniu wiadomości broker wysyła je do zarejestrowanych konsumentów dla każdego tematu.
Ustawieniami Apache Kafka zarządza Apache Zookeeper, który przechowuje metadane klastra, takie jak lokalizacja partycji, lista nazw, lista tematów i dostępne węzły. W ten sposób Zookeeper utrzymuje synchronizację między różnymi elementami klastra.
Zookeeper jest ważny, ponieważ Kafka jest systemem rozproszonym; to znaczy, że pisanie i czytanie są wykonywane przez kilku klientów jednocześnie. W przypadku awarii Zookeeper wybiera zastępcę i odzyskuje operację.
Przypadków użycia
Kafka stała się popularna, zwłaszcza jako narzędzie do przesyłania wiadomości, ale jej wszechstronność wykracza poza to i może być używana w różnych scenariuszach, jak w poniższych przykładach.
Wiadomości
Asynchroniczna forma komunikacji, która oddziela komunikujące się strony. W tym modelu jedna strona wysyła dane jako wiadomość do Kafki, więc inna aplikacja później je wykorzystuje.
Śledzenie aktywności
Umożliwia przechowywanie i przetwarzanie danych śledzących interakcję użytkownika ze stroną internetową, takich jak wyświetlenia strony, kliknięcia, wprowadzanie danych itp.; tego typu działalność zwykle generuje duże ilości danych.
Metryka
Obejmuje agregowanie danych i statystyk z wielu źródeł w celu wygenerowania scentralizowanego raportu.
Agregacja logów
Centralnie agreguje i przechowuje pliki dziennika pochodzące z innych systemów.
Przetwarzanie strumienia
Przetwarzanie potoków danych składa się z wielu etapów, w których surowe dane z tematów są zużywane i agregowane, wzbogacane lub przekształcane w inne tematy.
W celu obsługi tych funkcji platforma zasadniczo udostępnia trzy interfejsy API:
- Streams API: działa jako procesor strumieniowy, który pobiera dane z jednego tematu, przekształca je i zapisuje w innym.
- Connectors API: Umożliwia łączenie tematów z istniejącymi systemami, takimi jak relacyjne bazy danych.
- Interfejsy API producenta i konsumenta: umożliwiają aplikacjom publikowanie i wykorzystywanie danych Kafka.
Plusy
Replikowane, partycjonowane i uporządkowane
Wiadomości w Kafce są replikowane na partycjach w węzłach klastra w kolejności, w jakiej docierają, aby zapewnić bezpieczeństwo i szybkość dostarczania.
Transformacja danych
Dzięki Apache Kafka możliwe jest nawet przekształcanie przetwarzania wsadowego w czasie rzeczywistym za pomocą interfejsu API strumieni ETL wsadowych.
Sekwencyjny dostęp do dysku
Apache Kafka utrzymuje komunikat na dysku, a nie w pamięci, ponieważ ma być szybszy. W rzeczywistości dostęp do pamięci jest szybszy w większości sytuacji, zwłaszcza gdy rozważa się dostęp do danych, które znajdują się w losowych miejscach w pamięci. Jednak Kafka ma dostęp sekwencyjny i w tym przypadku dysk jest bardziej wydajny.
Apache Spark
Apache Spark to silnik przetwarzania dużych zbiorów danych i zestaw bibliotek do przetwarzania danych równoległych w klastrach. Spark to ewolucja Hadoop i paradygmatu programowania Map-Reduce. Może być 100 razy szybszy dzięki wydajnemu wykorzystaniu pamięci, która nie przechowuje danych na dyskach podczas przetwarzania.
Spark jest zorganizowany na trzech poziomach:
- Interfejsy API niskiego poziomu: Ten poziom zawiera podstawowe funkcje do uruchamiania zadań i inne funkcje wymagane przez inne składniki. Inne ważne funkcje tej warstwy to zarządzanie bezpieczeństwem, siecią, planowaniem i logicznym dostępem do systemów plików HDFS, GlusterFS, Amazon S3 i innych.
- Strukturyzowane interfejsy API: Poziom Strukturyzowanego interfejsu API zajmuje się manipulacją danymi za pomocą zestawów DataSet lub DataFrames, które można odczytywać w formatach takich jak Hive, Parquet, JSON i innych. Używając SparkSQL (API, które pozwala nam pisać zapytania w SQL), możemy manipulować danymi tak, jak chcemy.
- Wysoki poziom: na najwyższym poziomie mamy ekosystem Spark z różnymi bibliotekami, w tym Spark Streaming, Spark MLlib i Spark GraphX. Są odpowiedzialni za dbanie o przetwarzanie strumieniowe i otaczające procesy, takie jak odzyskiwanie po awarii, tworzenie i weryfikację klasycznych modeli uczenia maszynowego oraz radzenie sobie z wykresami i algorytmami.
Praca Spark
Architektura aplikacji Spark składa się z trzech głównych części:
Program Driver: Jest odpowiedzialny za koordynację wykonywania przetwarzania danych.
Menedżer klastra: Jest to komponent odpowiedzialny za zarządzanie różnymi maszynami w klastrze. Potrzebne tylko wtedy, gdy Spark działa w trybie rozproszonym.
Węzły robocze: są to maszyny, które wykonują zadania programu. Jeśli Spark jest uruchamiany lokalnie na twoim komputerze, będzie pełnić rolę programu sterownika i Workes. Ten sposób uruchamiania Sparka nazywa się Standalone.
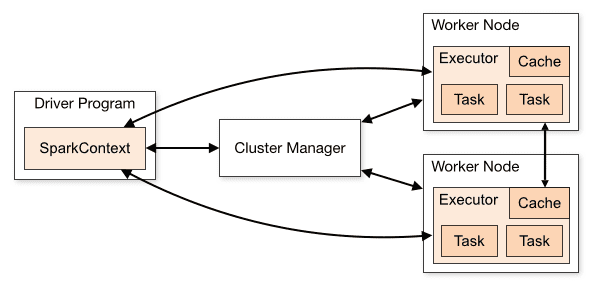 Przegląd klastra
Przegląd klastra
Kod Spark można napisać w wielu różnych językach. Konsola Spark, zwana Spark Shell, jest interaktywna do uczenia się i eksplorowania danych.
Tak zwana aplikacja Spark składa się z jednego lub więcej Jobów, umożliwiając wsparcie przetwarzania danych na dużą skalę.
Kiedy mówimy o wykonaniu, Spark ma dwa tryby:
- Klient: Sterownik działa bezpośrednio na kliencie, który nie przechodzi przez Menedżera zasobów.
- Klaster: Sterownik uruchomiony na wzorcu aplikacji za pośrednictwem Menedżera zasobów (w trybie klastra, jeśli klient się rozłączy, aplikacja będzie nadal działać).
Konieczne jest prawidłowe użycie Spark, aby połączone usługi, takie jak Menedżer zasobów, mogły zidentyfikować potrzebę każdego wykonania, zapewniając najlepszą wydajność. Od programisty zależy więc, jak najlepiej uruchomić swoje zadania Spark, ustrukturyzować wykonane połączenie. W tym celu możesz ustrukturyzować i skonfigurować executory Spark tak, jak chcesz.
Zadania Spark używają głównie pamięci, dlatego często dostosowuje się wartości konfiguracyjne Spark dla wykonawców węzła roboczego. W zależności od obciążenia Spark można określić, że pewna niestandardowa konfiguracja Spark zapewnia bardziej optymalne wykonania. W tym celu można przeprowadzić testy porównawcze pomiędzy różnymi dostępnymi opcjami konfiguracyjnymi i samą domyślną konfiguracją Sparka.
Wykorzystuje przypadki
Apache Spark pomaga w przetwarzaniu ogromnych ilości danych, zarówno w czasie rzeczywistym, jak i zarchiwizowanych, ustrukturyzowanych lub nieustrukturyzowanych. Oto niektóre z jego popularnych przypadków użycia.
Wzbogacanie danych
Często firmy wykorzystują kombinację danych historycznych klientów z danymi behawioralnymi w czasie rzeczywistym. Spark może pomóc w tworzeniu ciągłego potoku ETL w celu konwertowania nieustrukturyzowanych danych zdarzeń na dane strukturalne.
Wyzwalanie wykrywania zdarzeń
Spark Streaming umożliwia szybkie wykrywanie i reagowanie na niektóre rzadkie lub podejrzane zachowania, które mogą wskazywać na potencjalny problem lub oszustwo.
Złożona analiza danych sesji
Za pomocą Spark Streaming można grupować i analizować zdarzenia związane z sesją użytkownika, takie jak jego aktywność po zalogowaniu się do aplikacji. Te informacje mogą być również stale używane do aktualizowania modeli uczenia maszynowego.
Plusy
Przetwarzanie iteracyjne
Jeśli zadanie polega na wielokrotnym przetwarzaniu danych, odporne rozproszone zestawy danych (RDD) platformy Spark umożliwiają wiele operacji mapowania w pamięci bez konieczności zapisywania wyników pośrednich na dysku.
Obróbka graficzna
Model obliczeniowy Sparka z GraphX API doskonale nadaje się do obliczeń iteracyjnych typowych dla przetwarzania grafiki.
Nauczanie maszynowe
Spark ma MLlib — wbudowaną bibliotekę uczenia maszynowego, która ma gotowe algorytmy, które działają również w pamięci.
Kafka kontra Spark
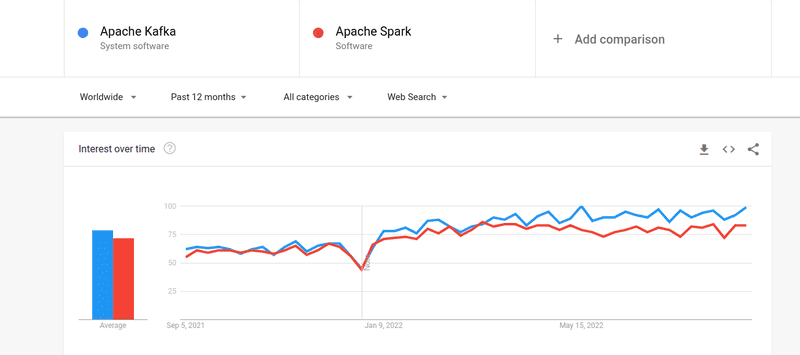
Mimo że zainteresowanie ludzi zarówno Kafką, jak i Sparkiem było prawie podobne, istnieją między nimi pewne zasadnicze różnice; Spójrzmy.
#1. Przetwarzanie danych
Kafka to narzędzie do strumieniowania i przechowywania danych w czasie rzeczywistym odpowiedzialne za przesyłanie danych między aplikacjami, ale nie wystarczy do zbudowania kompletnego rozwiązania. Dlatego do zadań, których nie wykonuje Kafka, potrzebne są inne narzędzia, takie jak Spark. Z drugiej strony Spark jest platformą przetwarzania danych typu „batch first”, która czerpie dane z tematów Kafki i przekształca je w połączone schematy.
#2. Zarządzanie pamięcią
Spark używa solidnych rozproszonych zestawów danych (RDD) do zarządzania pamięcią. Zamiast próbować przetwarzać ogromne zbiory danych, rozdziela je na wiele węzłów w klastrze. Natomiast Kafka korzysta z dostępu sekwencyjnego podobnego do HDFS i przechowuje dane w pamięci buforowej.
#3. Transformacja ETL
Zarówno Spark, jak i Kafka wspierają proces transformacji ETL, który kopiuje rekordy z jednej bazy danych do drugiej, zwykle z bazy transakcyjnej (OLTP) do bazy analitycznej (OLAP). Jednak w przeciwieństwie do Sparka, który ma wbudowaną możliwość obsługi procesu ETL, Kafka korzysta z interfejsu Streams API do jego obsługi.
#4. Trwałość danych

Użycie RRD przez Spark umożliwia przechowywanie danych w wielu lokalizacjach do późniejszego wykorzystania, podczas gdy w Kafce musisz zdefiniować obiekty zestawu danych w konfiguracji, aby utrwalić dane.
#5. Trudność
Spark to kompletne rozwiązanie i łatwiejsze do nauczenia dzięki obsłudze różnych języków programowania wysokiego poziomu. Kafka zależy od wielu różnych interfejsów API i modułów innych firm, co może utrudnić pracę.
#6. Powrót do zdrowia
Zarówno Spark, jak i Kafka zapewniają opcje odzyskiwania. Spark używa RRD, co pozwala na ciągłe zapisywanie danych, a jeśli wystąpi awaria klastra, można go odzyskać.

Kafka stale replikuje dane w klastrze i replikację między brokerami, co umożliwia przejście do różnych brokerów w przypadku awarii.
Podobieństwa między Sparkiem a Kafka
Apache SparkApache KafkaOpenSourceOpenSourceTworzenie aplikacji do strumieniowania danychTworzenie aplikacji do strumieniowego przesyłania danychObsługuje przetwarzanie stanoweObsługuje przetwarzanie stanoweObsługuje SQLObsługuje SQLPodobieństwa między platformami Spark i Kafka
Ostatnie słowa
Kafka i Spark to narzędzia typu open source napisane w Scali i Javie, które umożliwiają tworzenie aplikacji do strumieniowego przesyłania danych w czasie rzeczywistym. Mają kilka cech wspólnych, w tym przetwarzanie stanowe, obsługę SQL i ETL. Kafka i Spark mogą być również używane jako narzędzia uzupełniające, pomagające rozwiązać problem złożoności przesyłania danych między aplikacjami.