
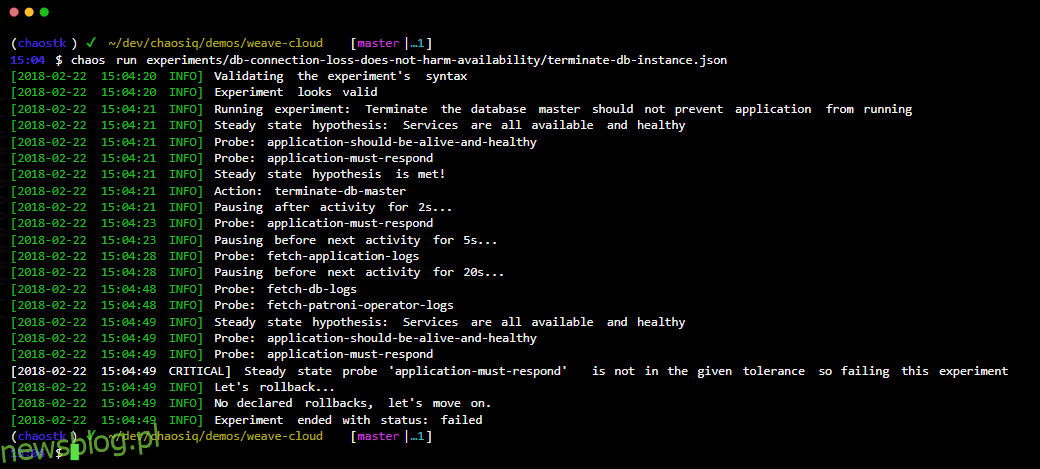
Przekonajmy się, jak możesz zachować niezawodność produkcji za pomocą narzędzi Chaos Engineering.
Inżynieria chaosu to dyscyplina, w której eksperymentujesz na swoim systemie lub aplikacji, aby odkryć jego słabości i awarie zdolności. To jest coś, o czym nie myślałeś, że może się zdarzyć podczas tworzenia. Tak więc celowo spowodowałbyś pewne awarie w systemie, aby ujawnić jego słabości, aby wprowadzić poprawki i zwiększyć odporność systemu i aplikacji.
Wiele popularnych organizacji, takich jak Netflix, LinkedIn i Facebook, przeprowadza inżynierię chaosu, aby lepiej zrozumieć swoją architekturę mikrousług i systemy rozproszone. Pomaga w znajdowaniu nowych problemów wcześniej niż prawdziwe skargi użytkowników i podejmowaniu niezbędnych działań w celu ich naprawienia. W ten sposób organizacje te mogą obsługiwać miliony użytkowników, zwiększać ich produktywność i oszczędzać miliony dolarów 🤑.
Korzyści z inżynierii chaosu:
- Kontroluj straty w przychodach, znajdując krytyczne problemy
- Redukcja awarii systemu lub aplikacji
- Lepsze wrażenia użytkownika przy mniejszych zakłóceniach i wysokiej dostępności usług
- Pomaga poznać system i zyskać pewność siebie.
Jak bardzo jesteś pewny swojej niezawodności produkcji? Czy to naprawdę odporne na katastrofy?
Przekonajmy się za pomocą następujących popularnych narzędzi do testowania chaosu.
Spis treści:
Siatka chaosu
Siatka chaosu to rozwiązanie do zarządzania inżynierią chaosu, które wprowadza błędy do każdej warstwy systemu Kubernetes. Obejmuje to pody, sieć, systemowe we/wy i jądro. Chaos Mesh może automatycznie zabijać pody Kubernetes i symulować opóźnienia. Może zakłócać komunikację między urządzeniami i symulować błędy odczytu/zapisu. Może zaplanować zasady eksperymentów i określić ich zakres. Te eksperymenty są określane za pomocą plików YAML.
Chaos Mesh ma pulpit nawigacyjny do przeglądania analiz eksperymentów. Działa na Kubernetes i obsługuje większość platformy chmurowej. Jest open-source i został niedawno zaakceptowany jako projekt piaskownicy CNCF. Korzystając z zasad inżynierii chaosu, możesz dodać Chaos Mesh do przepływu pracy DevOps, aby tworzyć odporne aplikacje.
Cechy Inżynierii Chaosu:
- Łatwe wdrażanie w klastrach Kubernetes bez modyfikacji logiki wdrażania
- Do wdrożenia nie są wymagane żadne unikalne zależności
- Definiuje obiekty chaosu za pomocą CustomResourceDefinitions (CRD)
- Udostępnia pulpit nawigacyjny do śledzenia wszystkich eksperymentów
Zestaw narzędzi Chaosu jest otwartym i prostym narzędziem do automatyzacji eksperymentów inżynieryjnych Chaos.
Integrujesz Chaos ToolKit ze swoim systemem za pomocą zestawu sterowników lub wtyczek, które obsługuje AWS, Google Cloud, Slack, Prometheus itp.
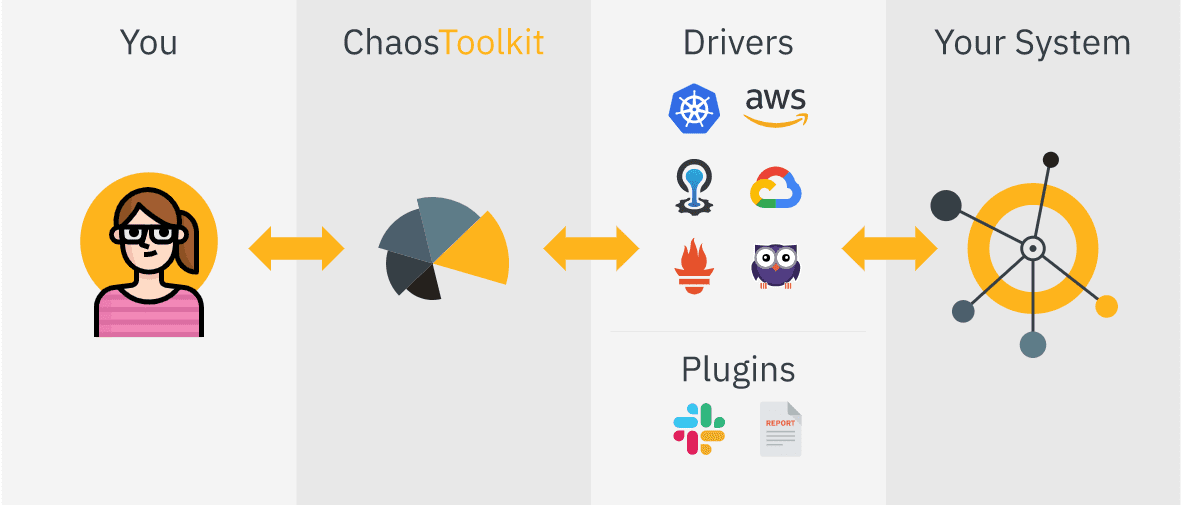
Funkcje zestawu narzędzi Chaos:
- Zapewnia deklaratywne Open API do tworzenia eksperymentów chaosu niezależnie od dostawcy lub technologii
- Może być łatwo osadzony w rurociągach CICD w celu automatyzacji
- Zapewnia wsparcie komercyjne i korporacyjne również poprzez: ChaosIQ
ChaosKube
Jak można się domyślić po nazwie, to dla Kubernetes.
Chaoskube to narzędzie chaosu typu open source, które okresowo zabija losowe pody w klastrze Kubernetes. Pomaga zrozumieć, jak twój system zareaguje, gdy kapsuła ulegnie awarii. Domyślnie zabija pod w dowolnej przestrzeni nazw co 10 minut. Możesz filtrować docelowe pody w Chaoskube za pomocą przestrzeni nazw, etykiet, adnotacji itp. Można je łatwo zainstalować za pomocą Chaokube.

Małpa Chaosu
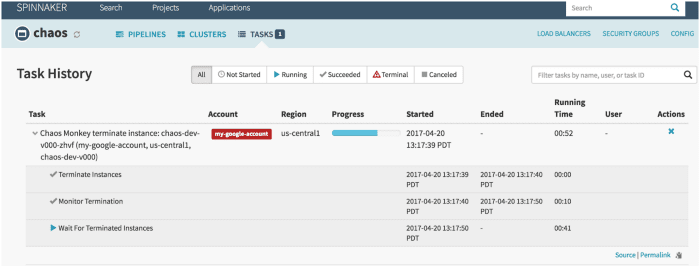
Małpa Chaosu to narzędzie służące do sprawdzania odporności systemów w chmurze poprzez celowe tworzenie awarii, aby te systemy mogły zrozumieć ich reakcję. Netflix stworzył go, aby przetestować odporność i odzyskiwanie swojej infrastruktury AWS. Został nazwany Chaos Monkey, ponieważ tworzy zniszczenie jak dzika i uzbrojona małpa, aby przetestować niepowodzenia.
To właśnie Chaos Monkey dał początek nowej praktyce inżynierskiej Chaos Engineering. Powstała w myśl zasady, że lepiej wielokrotnie ponosić porażkę, aby nagle uniknąć poważnej awarii.
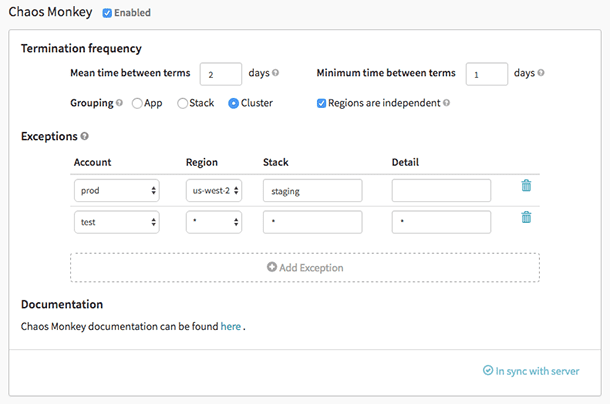
Cechy Małpy Chaosu:
- Pomaga przygotować się na przypadkowe awarie instancji.
- Zachęca do redundancji w przypadku nieoczekiwanych awarii
- Wykorzystuje Spinnaker, aby zapewnić kompatybilność między chmurami
- Zapewnia konfigurowalny harmonogram symulacji awarii
- Zintegrowany z gubernator dodać nowe zależności do chaos monkey
Simmy
Simmy to narzędzie chaosu do wstrzykiwania błędów, które integruje się z projektem odporności Polly dla platformy .NET. Umożliwia tworzenie zasad wprowadzania chaosu za pośrednictwem Polly, gdzie wykonujesz swoje kody. Oferuje różne polityki, takie jak polityka wyjątków do wstrzykiwania wyjątków do systemu, polityka zachowania do wstrzykiwania nowego zachowania itp. Te zasady są zaprojektowane do losowego wstrzykiwania zachowania.
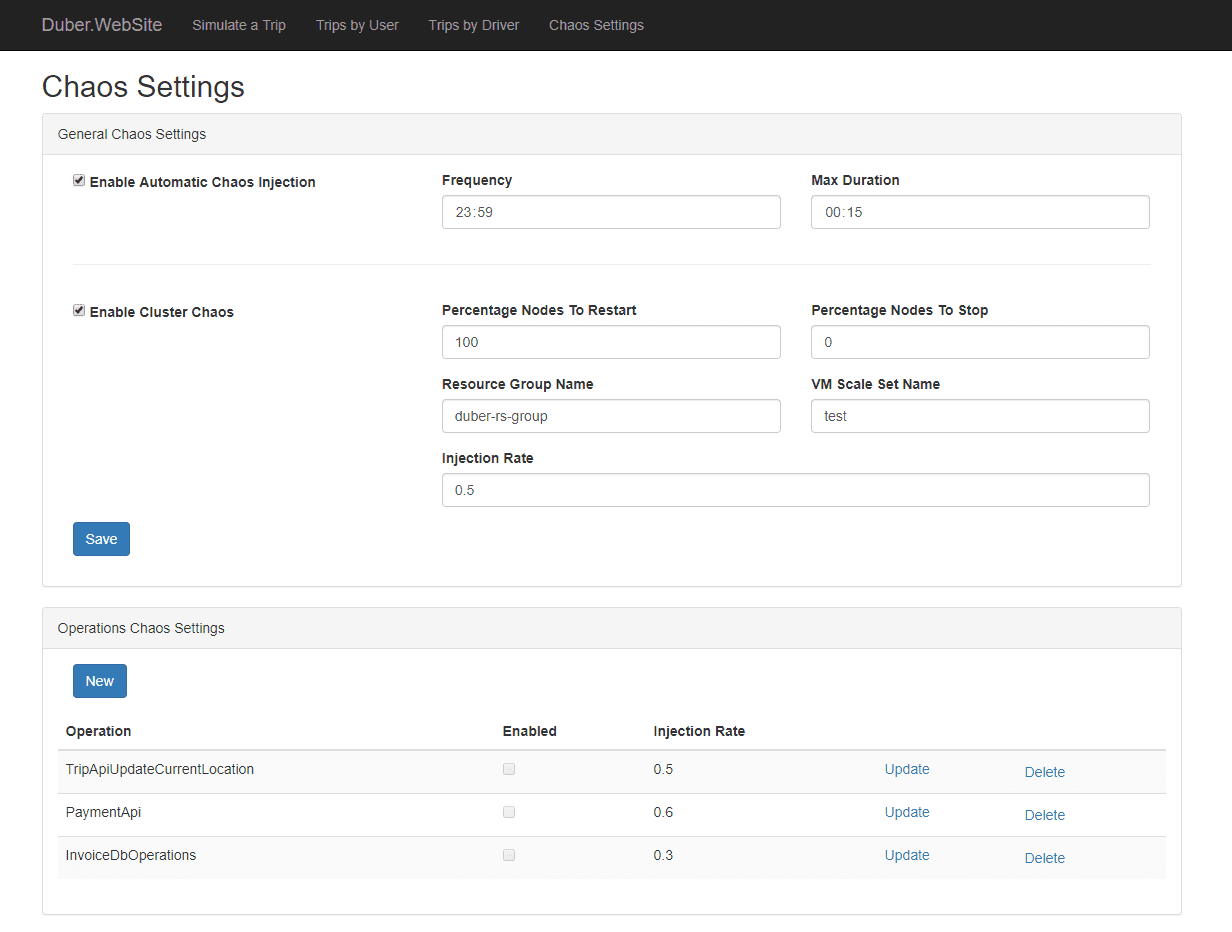
Funkcje Simmy:
- Udostępnia zasady Monkey lub zasady Chaos, aby wprowadzić chaos
- Łatwe do przetestowania wszelkie awarie zależności
- Pomaga szybko powrócić do modelu roboczego i kontroluje promień wybuchu.
- Jest gotowy do produkcji.
- Może definiować awarie również w oparciu o czynniki zewnętrzne (na przykład awarie spowodowane globalną konfiguracją)
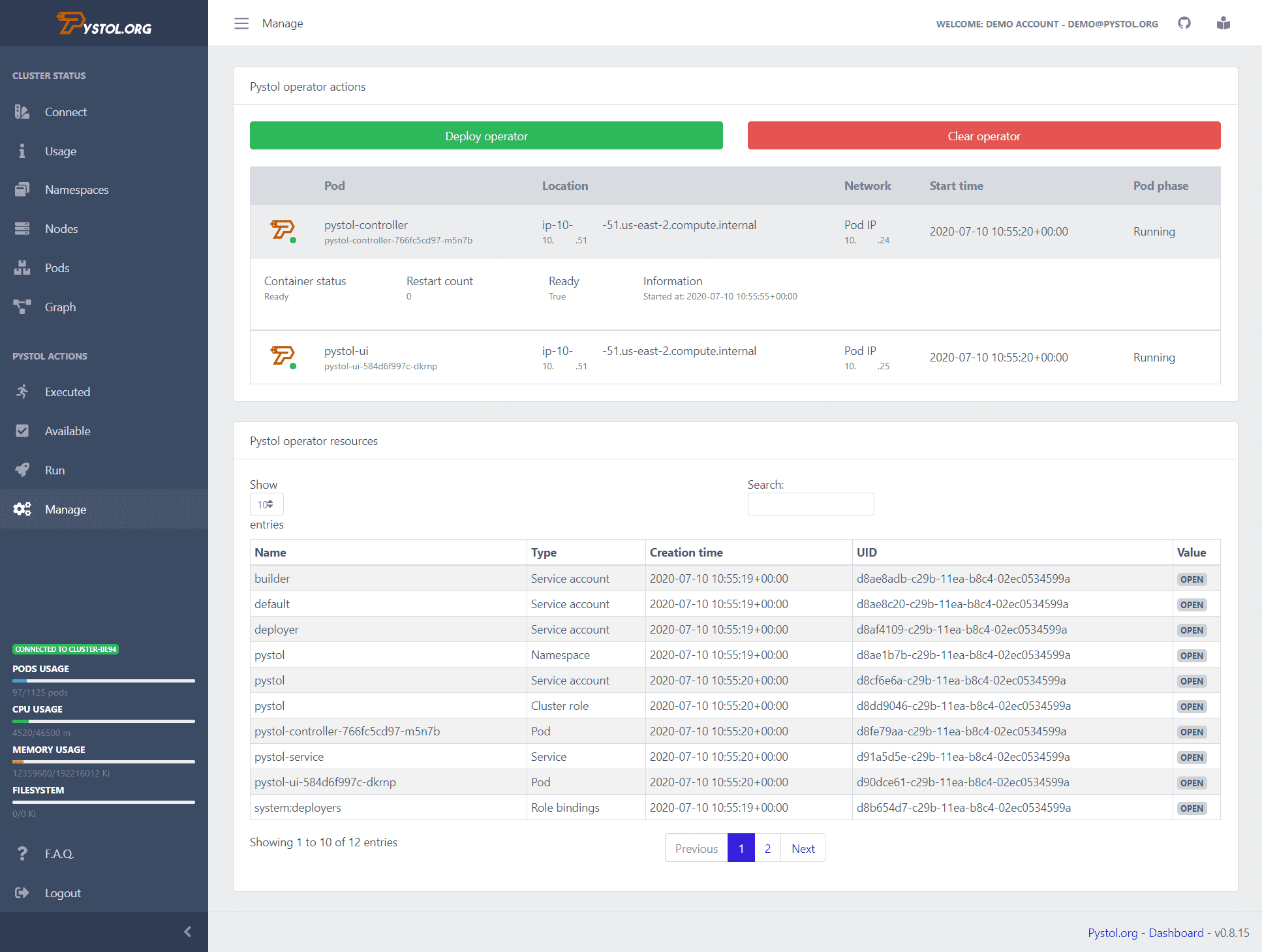
Pistol
Pistol to narzędzie, które służy do wstrzykiwania wadliwych wstrzyknięć w środowiskach natywnych dla chmury. Obserwuje zdarzenia w ETCD za pośrednictwem operatorów Kubernetes. Po wykonaniu akcji wstrzykiwania błędu operatorzy tworzą pody i uruchamiają niektóre kolekcje Ansible. Tak więc programiści nie muszą pisać własnych działań do wykonania.
Pystol udostępnia gotowe akcje do testowania systemu. Jeśli jednak programista chce stworzyć nową akcję, może to zrobić za pomocą GoLanga i Pythona.
Zapewnia pulpit nawigacyjny ciągłej integracji, który zapewnia podsumowanie wszystkich operacji związanych z pracą. Możesz uruchomić Pystol lokalnie lub wdrożyć go w kontenerze za pomocą jego obrazu dockera. Pystol zapewnia dwa interfejsy, jeden to Web UI, a drugi przez CLI. Oczywiście lepszym rozwiązaniem jest interfejs sieciowy.
Muxy
Muxy jest serwerem proxy do testowania wzorców odporności i odporności na awarie pod kątem rzeczywistych awarii systemów rozproszonych. Może manipulować poziomem transportu (warstwa 4), poziomem sesji TCP (warstwa 5) i poziomem protokołu HTTP (warstwa 7).
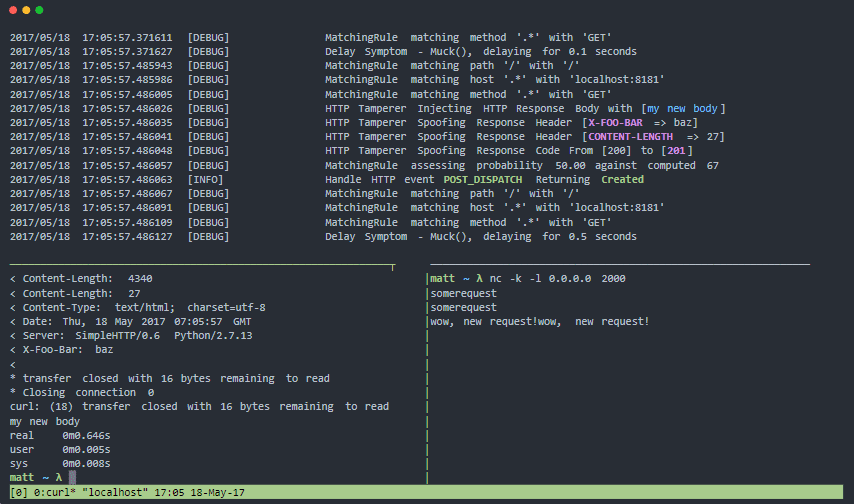
Funkcje Muxy:
- Modułowa architektura i łatwość rozbudowy
- Ma oficjalny kontener dockera
- Łatwy w instalacji, nie wymaga żadnych zależności.
- Idealny do ciągłego testowania odporności
- Symuluje problemy z łącznością sieciową dla systemów rozproszonych i urządzeń mobilnych
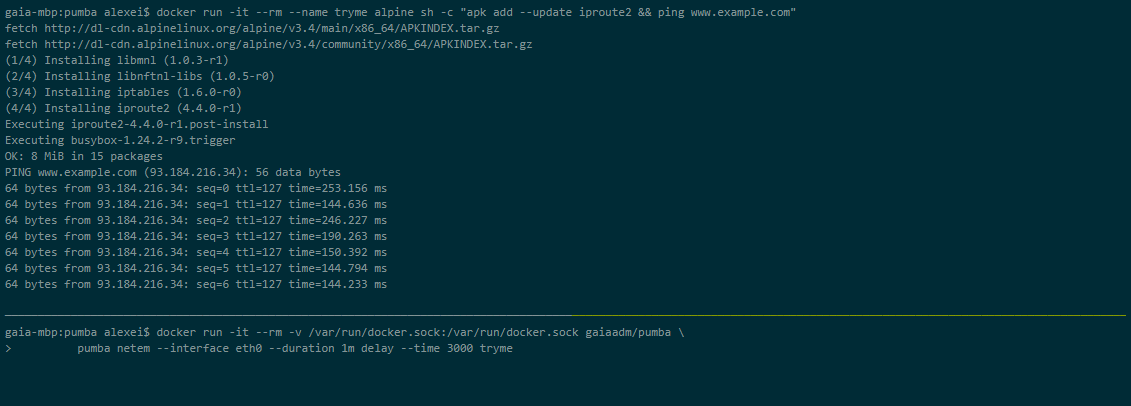
Pumba
Pumba to narzędzie wiersza poleceń, które wykonuje testy chaosu dla kontenerów dockera. W przypadku Pumby celowo zawieszasz kontenery dockera aplikacji, aby zobaczyć, jak zareaguje system. Możesz także przeprowadzić testy warunków skrajnych na zasobach kontenera, takich jak procesor, pamięć, system plików, wejście/wyjście itp.
Możesz także uruchomić Pumbę w klastrze Kubernetes. Musisz użyć DaemonSets, aby wdrożyć Pumbę na węzłach Kubernetes. Możesz użyć wielu kontenerów Pumba, aby uruchomić wiele poleceń Pumba w tym samym DaemonSet.
Ostrze Chaosu
Ostrze chaosu to narzędzie typu open source do wstrzykiwania eksperymentów do systemów firmy Alibaba. Testuje wszystkie awarie, z jakimi Alibaba miał do czynienia w ciągu ostatnich dziesięciu lat i stosuje najlepsze praktyki, aby ich uniknąć. Przestrzega zasad inżynierii chaosu, aby sprawdzić odporność na awarie systemów rozproszonych.
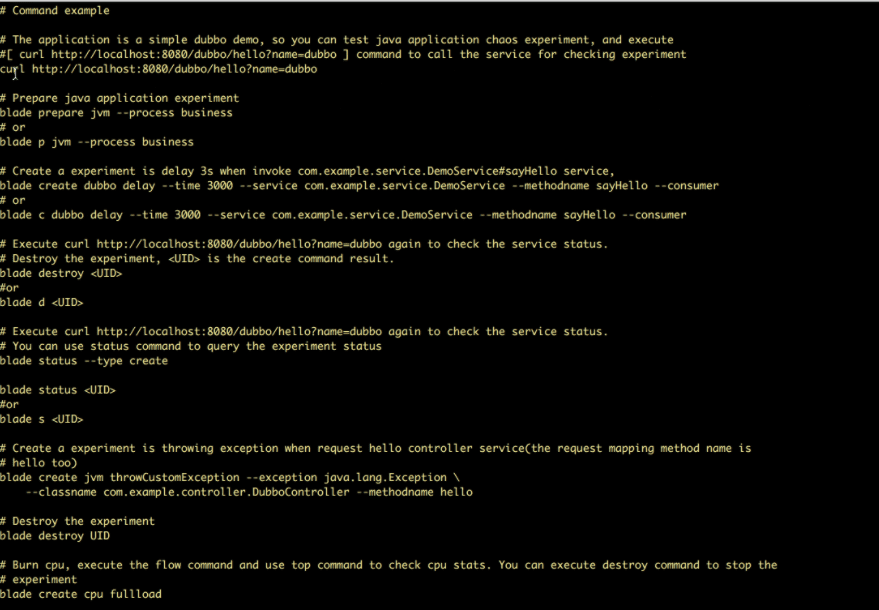
Funkcje ChaosBlade:
- Zapewnia eksperymentalne scenariusze dla wielu zasobów, takich jak procesor, sieć, pamięć, dysk itp.
- Zapewnia eksperymentalne scenariusze dla węzłów, sieci i podów na platformie Kubernetes
- Zapewnia łatwe w użyciu polecenia CLI do wykonywania eksperymentów
Lakmus
Lakmus przestrzega zasad inżynierii chaosu natywnych dla chmury. Misją narzędzia lakmusowego jest dostarczenie kompletnego frameworka do znajdowania słabych punktów w Twoich systemach Kubernetes i działających aplikacjach na Kubernetes.
Ma wokół niego operatora chaosu i CRD (CustomResourceDefinitions), co umożliwia korzystanie z funkcji plug-and-play. Chodzi o umieszczenie logiki chaosu w obrazie dokowanym, wrzucenie go do struktury lakmusowej i zorganizowanie ich za pomocą CRD.

Cechy lakmusowe:
- Pomaga inżynierom i programistom ds. niezawodności witryny znaleźć słabe punkty w systemie Kubernetes
- Zapewnia gotowe do użycia ogólne eksperymenty
- Zapewnia Chaos API do zarządzania przepływem chaosu
- Litmus SDK obsługuje Go, Python i Ansible do tworzenia własnych eksperymentów.
Zły duch
Zły duch pomaga inżynierom budować bardziej odporne oprogramowanie. Zapewnia platformę do bezpiecznego i prostego przeprowadzania eksperymentów inżynierii chaosu.

Możesz przemyślanie wstrzykiwać błędy do hostów lub kontenerów za pomocą gremlina, niezależnie od tego, gdzie się znajdują, czy jest to chmura publiczna, czy własne centrum danych.
Cechy Gremlina:
- Instaluje lekkiego agenta na hostach lub kontenerach, aby wstrzykiwać awarie
- Zapewnia ponad 10 różnych trybów ataku na infrastrukturę
- Gremliny stanowe pozwalają manipulować czasem systemowym, wyłączać lub restartować hosty i zabijać procesory.
- Gremliny sieciowe mogą wstrzykiwać opóźnienia, aby spowodować utratę pakietów lub odrzucić ruch.
- Ataki biblioteki Gremlin Alfi można konfigurować, uruchamiać i zatrzymywać za pomocą aplikacji internetowej. API lub CLI
- Pozwala precyzyjnie wycelować w promień wybuchu, który chcesz zaatakować
- Pozwala zatrzymać wszystkie ataki i przywrócić system do stanu stabilnego
Stałybit
Stałybit ma na celu proaktywną redukcję przestojów i zapewnia wgląd w problemy systemowe. Możesz uruchomić to narzędzie lokalnie w swojej infrastrukturze lub chmurze jako usługa (SaaS).
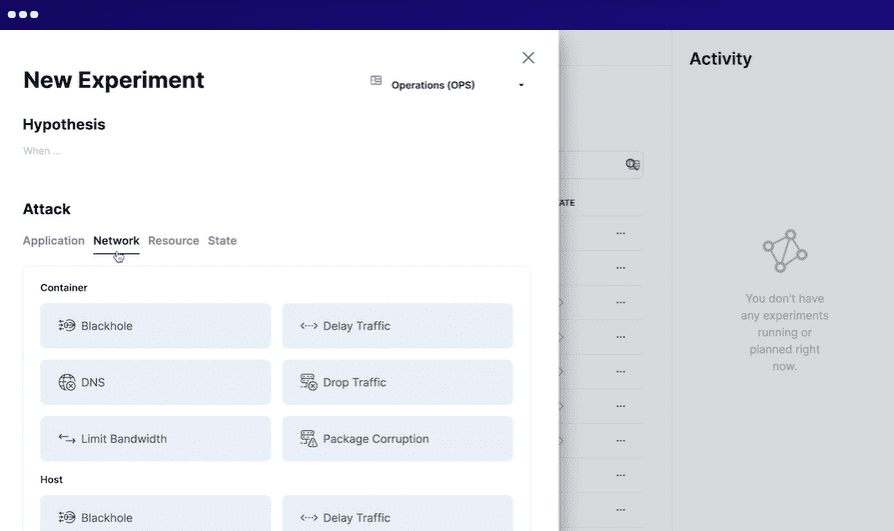
Aby użyć Steadybit, definiujesz sytuację, symulujesz eksperymenty, przeprowadzasz symulowane eksperymenty na produkcji i automatyzujesz wszystkie eksperymenty. Uruchamia w systemie inteligentnych agentów, aby wykryć potencjalne problemy i słabości. Z łatwością integruje się z wieloma systemami.
Wniosek
Śmiało i bądź na tyle odważny, aby zastosować zasady inżynierii chaosu i przetestować swoją produkcję za pomocą wyżej wymienionych narzędzi. Narzędzia te pomogą Ci znaleźć wiele niezidentyfikowanych słabości w Twoim systemie i pomogą Ci zwiększyć jego odporność.