
Ekstrakcja danych to proces zbierania określonych danych ze stron internetowych. Użytkownicy mogą wyodrębniać tekst, obrazy, filmy, recenzje, produkty itp. Możesz wyodrębniać dane w celu przeprowadzania badań rynkowych, analiz nastrojów, analiz konkurencji i agregowania danych.
Jeśli masz do czynienia z niewielką ilością danych, możesz wyodrębnić dane ręcznie, kopiując i wklejając określone informacje ze stron internetowych do arkusza kalkulacyjnego lub formatu dokumentu według własnych upodobań. Na przykład, jeśli jako klient szukasz recenzji online, które pomogą Ci podjąć decyzję o zakupie, możesz ręcznie usunąć dane.
Z drugiej strony, jeśli masz do czynienia z dużymi zbiorami danych, potrzebujesz zautomatyzowanej techniki wyodrębniania danych. Możesz stworzyć wewnętrzne rozwiązanie do ekstrakcji danych lub użyć do takich zadań Proxy API lub Scraping API.
Techniki te mogą być jednak mniej skuteczne, ponieważ niektóre witryny, na które kierujesz reklamy, mogą być chronione przez captcha. Może być również konieczne zarządzanie botami i serwerami proxy. Takie zadania mogą zająć dużo czasu i ograniczyć charakter zawartości, którą można wyodrębnić.
Spis treści:
Przeglądarka zeskrobująca: rozwiązanie
Możesz pokonać wszystkie te wyzwania za pomocą przeglądarki Scraping Browser firmy Bright Data. Ta wszechstronna przeglądarka pomaga zbierać dane ze stron internetowych, które są trudne do zeskrobania. Jest to przeglądarka korzystająca z graficznego interfejsu użytkownika (GUI) i kontrolowana przez Puppeteer lub Playwright API, dzięki czemu jest niewykrywalna przez boty.
Scraping Browser ma wbudowane funkcje odblokowujące, które automatycznie obsługują wszystkie blokady w Twoim imieniu. Przeglądarka jest otwierana na serwerach Bright Data, co oznacza, że nie potrzebujesz drogiej infrastruktury wewnętrznej, aby przetwarzać dane na potrzeby dużych projektów.
Funkcje przeglądarki Bright Data Scraping
- Automatyczne odblokowywanie stron internetowych: nie musisz ciągle odświeżać przeglądarki, ponieważ ta przeglądarka automatycznie dostosowuje się do rozwiązywania problemów CAPTCHA, nowych blokad, odcisków palców i ponownych prób. Scraping Browser naśladuje prawdziwego użytkownika.
- Duża sieć serwerów proxy: możesz kierować reklamy na dowolny kraj, ponieważ Scraping Browser ma ponad 72 miliony adresów IP. Możesz kierować reklamy na miasta, a nawet operatorów i korzystać z najlepszej w swojej klasie technologii.
- Skalowalność: możesz otwierać tysiące sesji jednocześnie, ponieważ ta przeglądarka wykorzystuje infrastrukturę Bright Data do obsługi wszystkich żądań.
- Zgodność z Puppeteer i Playwright: Ta przeglądarka umożliwia wykonywanie wywołań API i pobieranie dowolnej liczby sesji przeglądarki za pomocą Puppeteer (Python) lub Playwright (Node.js).
- Oszczędność czasu i zasobów: Zamiast konfigurować serwery proxy, Scraping Browser zajmuje się wszystkim w tle. Nie musisz też konfigurować wewnętrznej infrastruktury, ponieważ to narzędzie zajmuje się wszystkim w tle.
Jak skonfigurować przeglądarkę skrobania
- Udaj się na stronę internetową Bright Data i kliknij przeglądarkę Scraping Browser na karcie „Scraping Solutions”.
- Utwórz konto. Zobaczysz dwie opcje; „Rozpocznij bezpłatny okres próbny” i „Rozpocznij bezpłatnie z Google”. Wybierzmy na razie „Rozpocznij bezpłatny okres próbny” i przejdźmy do następnego kroku. Możesz utworzyć konto ręcznie lub użyć swojego konta Google.
- Po utworzeniu konta na pulpicie pojawi się kilka opcji. Wybierz „Proxy i infrastruktura skrobania”.
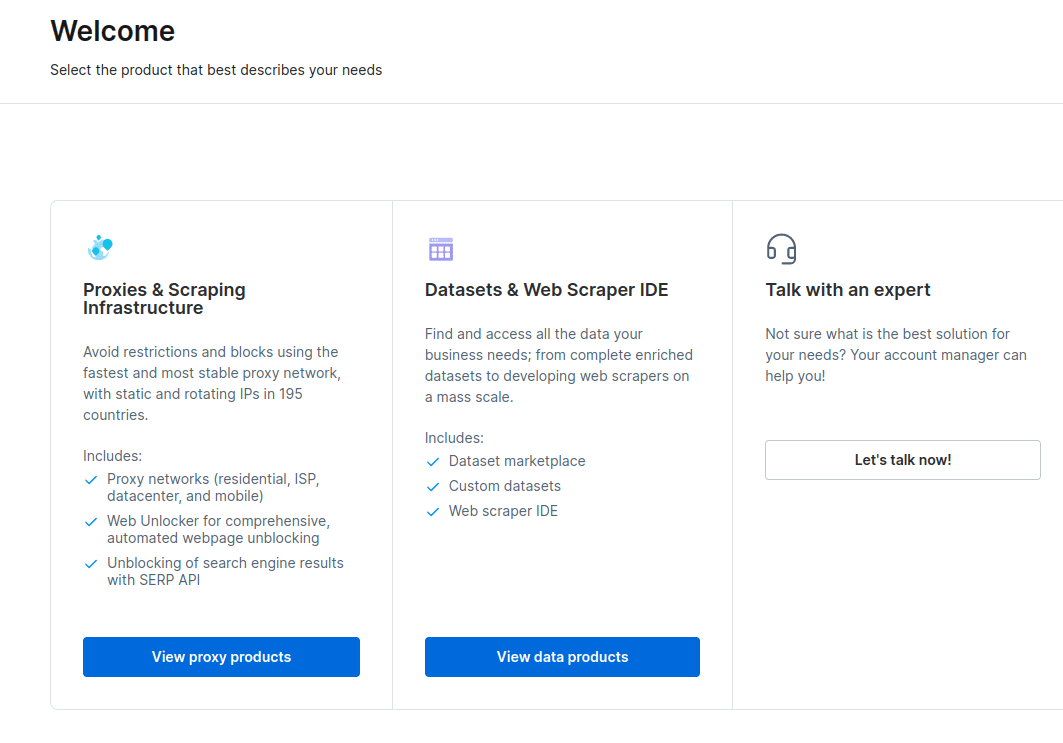
- W nowym oknie, które się otworzy, wybierz Scraping Browser i kliknij „Rozpocznij”.
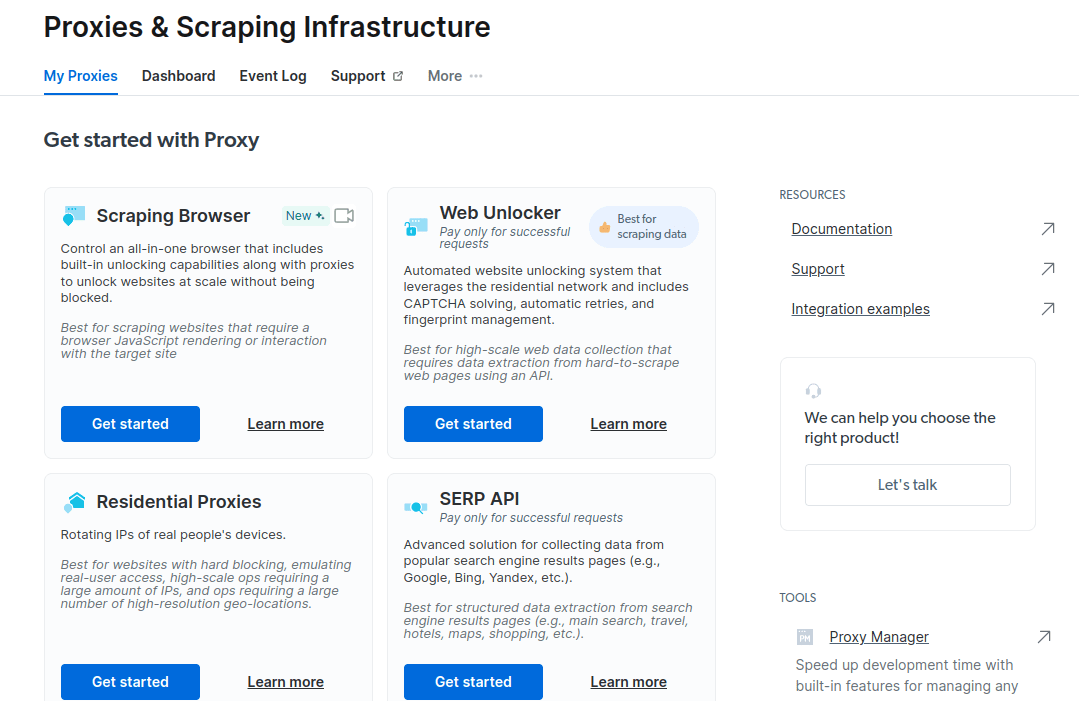
- Zapisz i aktywuj swoje konfiguracje.
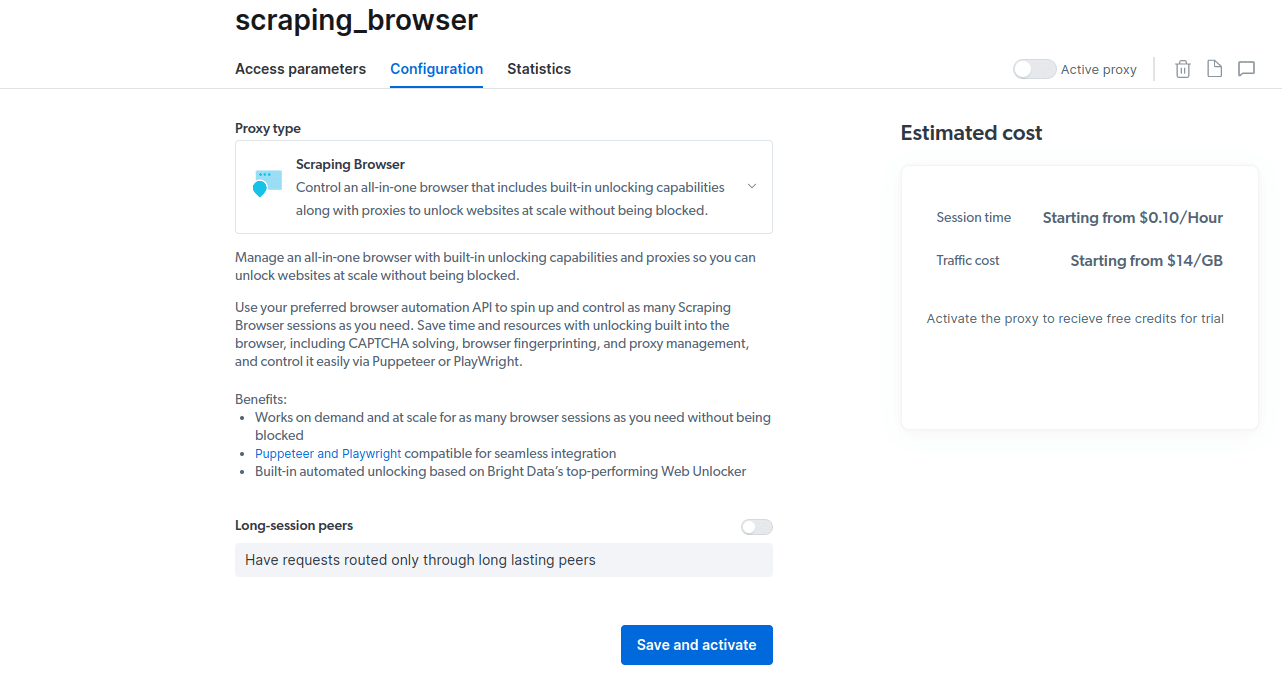
- Aktywuj bezpłatny okres próbny. Pierwsza opcja daje kredyt w wysokości 5 USD, który możesz wykorzystać na korzystanie z serwera proxy. Kliknij pierwszą opcję, aby wypróbować ten produkt. Jeśli jednak jesteś ciężkim użytkownikiem, możesz kliknąć drugą opcję, która daje 50 USD za darmo, jeśli doładujesz konto kwotą 50 USD lub więcej.
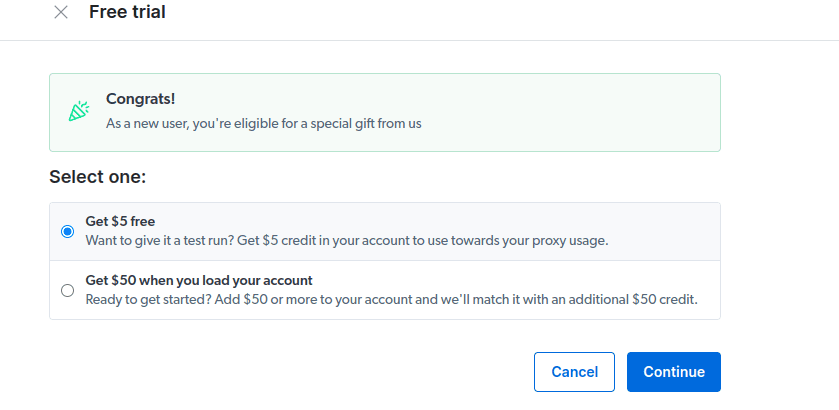
- Wpisz swoje informacje rozliczeniowe. Nie martw się, ponieważ platforma nie obciąży Cię niczym. Informacje rozliczeniowe po prostu sprawdzają, czy jesteś nowym użytkownikiem i nie szukasz gratisów, tworząc wiele kont.
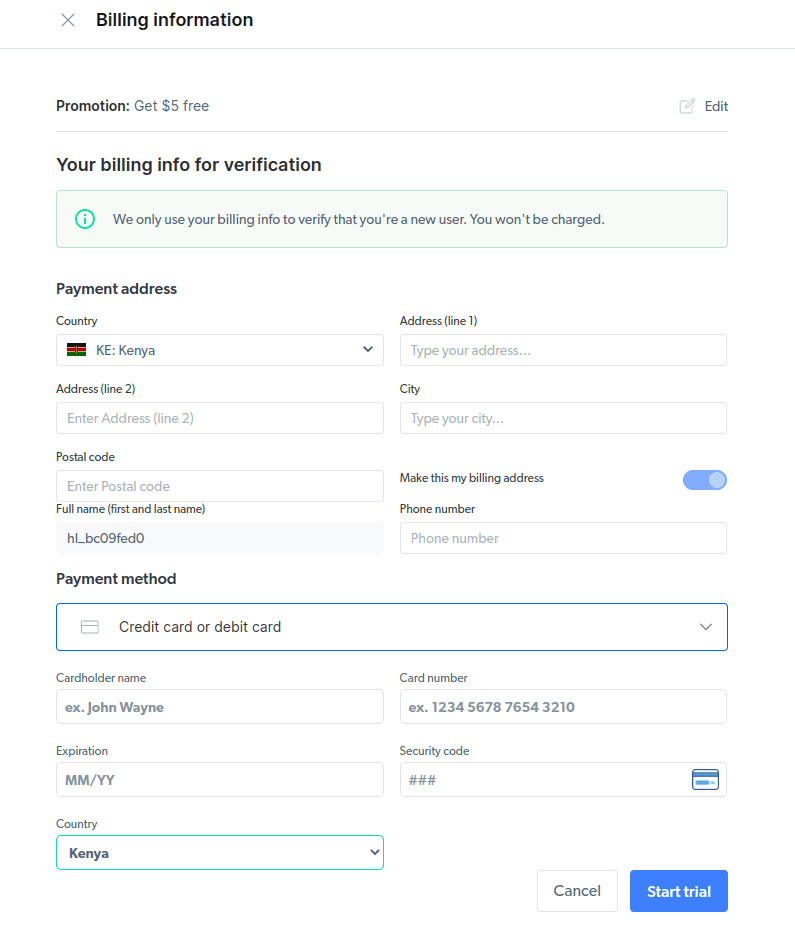
- Utwórz nowy serwer proxy. Po zapisaniu danych rozliczeniowych możesz utworzyć nowe proxy. Kliknij ikonę „dodaj” i wybierz opcję Scraping Browser jako „Typ serwera proxy”. Kliknij „Dodaj proxy” i przejdź do następnego kroku.
- Utwórz nową „strefę”. Pojawi się wyskakujące okienko z pytaniem, czy chcesz utworzyć nową strefę; kliknij „Tak” i kontynuuj.
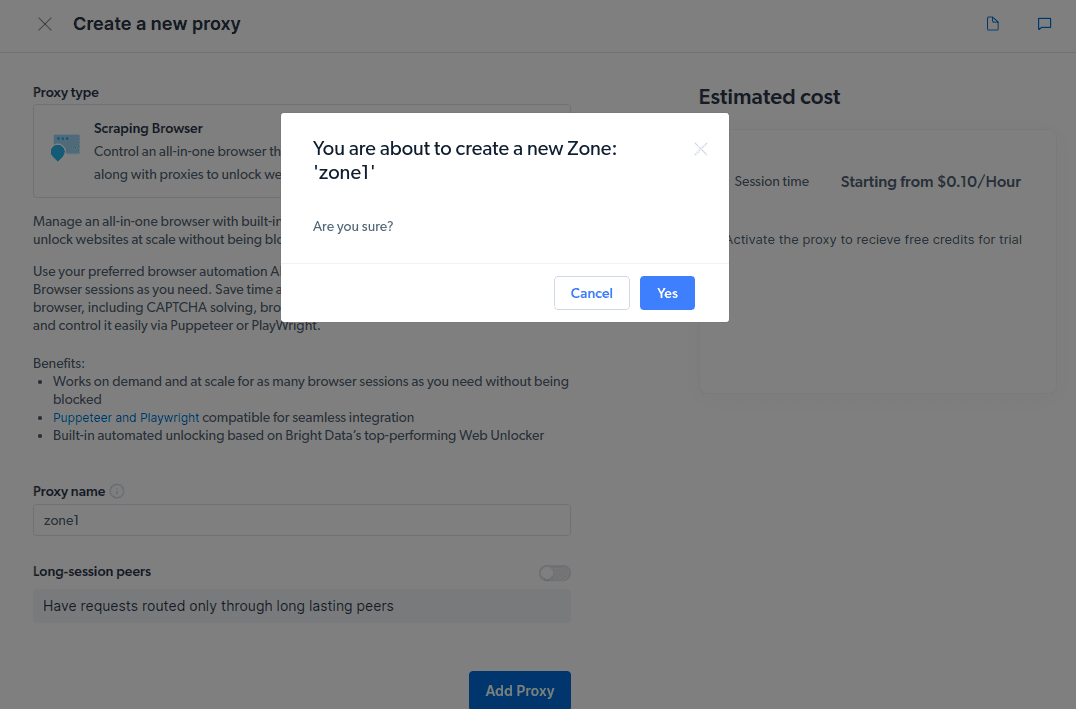
- Kliknij „Sprawdź przykłady kodu i integracji”. Otrzymasz teraz przykłady integracji z serwerem proxy, których możesz użyć do usunięcia danych z docelowej witryny. Możesz użyć Node.js lub Python do wyodrębnienia danych z docelowej witryny.
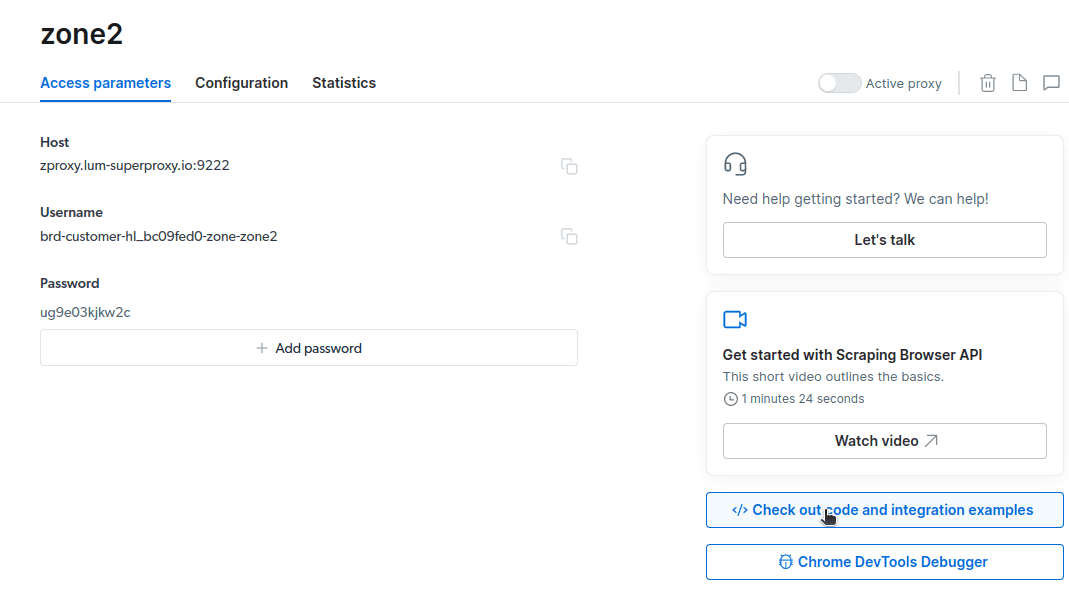
Masz teraz wszystko, czego potrzebujesz, aby wyodrębnić dane ze strony internetowej. Użyjemy naszej strony internetowej newsblog.pl.com, aby zademonstrować, jak działa Scraping Browser. W tej demonstracji użyjemy pliku node.js. Możesz śledzić dalej, jeśli masz zainstalowany node.js.
Wykonaj następujące kroki;
const puppeteer = require('puppeteer-core');
// should look like 'brd-customer-<ACCOUNT ID>-zone-<ZONE NAME>:<PASSWORD>'
const auth="USERNAME:PASSWORD";
async function run(){
let browser;
try {
browser = await puppeteer.connect({browserWSEndpoint: `wss://${auth}@zproxy.lum-superproxy.io:9222`});
const page = await browser.newPage();
page.setDefaultNavigationTimeout(2*60*1000);
await page.goto('https://example.com');
const html = await page.evaluate(() => document.documentElement.outerHTML);
console.log(html);
}
catch(e) {
console.error('run failed', e);
}
finally {
await browser?.close();
}
}
if (require.main==module)
run();
Zmienię mój kod w linii 10 na następujący;
czekać na stronę.goto(’https://newsblog.pl.com/authors/’);
Mój ostateczny kod teraz będzie;
const puppeteer = require('puppeteer-core');
// should look like 'brd-customer-<ACCOUNT ID>-zone-<ZONE NAME>:<PASSWORD>'
const auth="brd-customer-hl_bc09fed0-zone-zone2:ug9e03kjkw2c";
async function run(){
let browser;
try {
browser = await puppeteer.connect({browserWSEndpoint: `wss://${auth}@zproxy.lum-superproxy.io:9222`});
const page = await browser.newPage();
page.setDefaultNavigationTimeout(2*60*1000);
await page.goto('https://newsblog.pl.com/authors/');
const html = await page.evaluate(() => document.documentElement.outerHTML);
console.log(html);
}
catch(e) {
console.error('run failed', e);
}
finally {
await browser?.close();
}
}
if (require.main==module)
run();
node script.js
Będziesz miał coś takiego na swoim terminalu
Jak wyeksportować dane
Możesz użyć kilku podejść do eksportowania danych, w zależności od tego, jak zamierzasz ich użyć. Dziś możemy wyeksportować dane do pliku html zmieniając skrypt tak, aby tworzył nowy plik o nazwie data.html zamiast drukować go na konsoli.
Możesz zmienić zawartość swojego kodu w następujący sposób;
const puppeteer = require('puppeteer-core');
const fs = require('fs');
// should look like 'brd-customer-<ACCOUNT ID>-zone-<ZONE NAME>:<PASSWORD>'
const auth="brd-customer-hl_bc09fed0-zone-zone2:ug9e03kjkw2c";
async function run() {
let browser;
try {
browser = await puppeteer.connect({ browserWSEndpoint: `wss://${auth}@zproxy.lum-superproxy.io:9222` });
const page = await browser.newPage();
page.setDefaultNavigationTimeout(2 * 60 * 1000);
await page.goto('https://newsblog.pl.com/authors/');
const html = await page.evaluate(() => document.documentElement.outerHTML);
// Write HTML content to a file
fs.writeFileSync('data.html', html);
console.log('Data export complete.');
} catch (e) {
console.error('run failed', e);
} finally {
await browser?.close();
}
}
if (require.main == module) {
run();
}
Możesz teraz uruchomić kod za pomocą tego polecenia;
node script.js
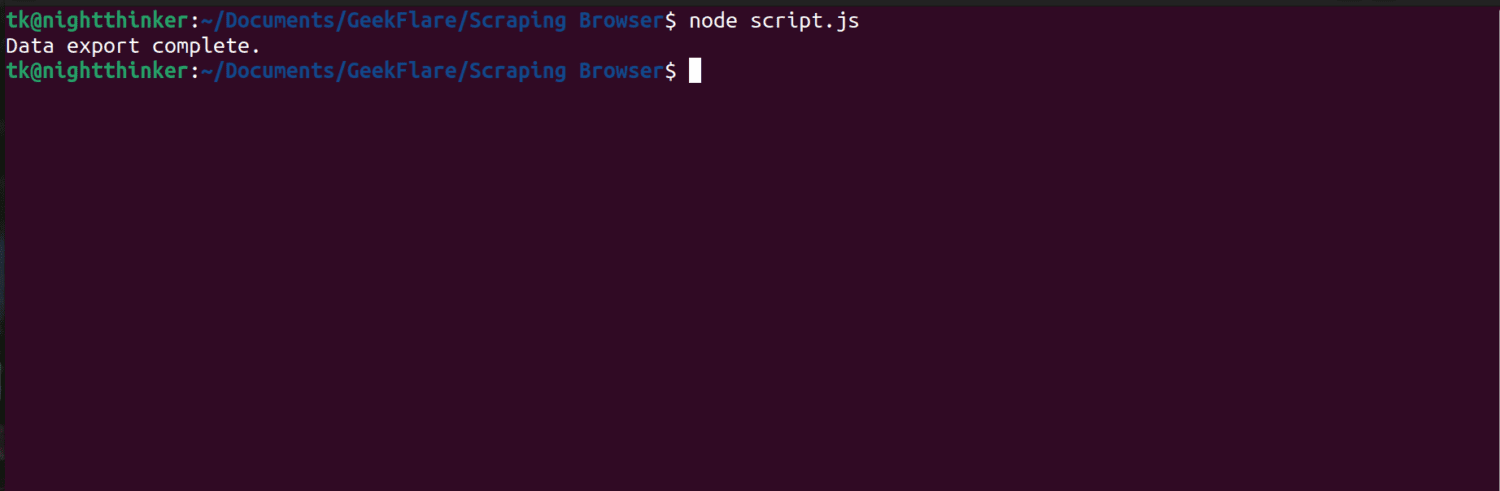
Jak widać na poniższym zrzucie ekranu, terminal wyświetla komunikat „Eksport danych zakończony”.
Jeśli sprawdzimy nasz folder projektu, możemy teraz zobaczyć plik o nazwie data.html z tysiącami linii kodu.
Właśnie podrapałem się po powierzchni, jak wyodrębnić dane za pomocą przeglądarki Scraping. Za pomocą tego narzędzia mogę nawet zawęzić i usunąć tylko nazwiska autorów i ich opisy.
Jeśli chcesz korzystać z przeglądarki skrobania, zidentyfikuj zestawy danych, które chcesz wyodrębnić, i odpowiednio zmodyfikuj kod. Możesz wyodrębnić tekst, obrazy, filmy, metadane i linki, w zależności od docelowej witryny i struktury pliku HTML.
Często zadawane pytania
Czy ekstrakcja danych i web scraping są legalne?
Skrobanie sieci to kontrowersyjny temat, jedna grupa twierdzi, że jest niemoralna, podczas gdy inni uważają, że jest w porządku. Legalność web scrapingu będzie zależała od charakteru treści i polityki docelowej strony internetowej.
Zasadniczo pobieranie danych z danymi osobowymi, takimi jak adresy i dane finansowe, jest uważane za nielegalne. Zanim zaczniesz zbierać dane, sprawdź, czy witryna, na którą kierujesz reklamy, ma jakieś wytyczne. Zawsze upewnij się, że nie usuwasz tych danych, które nie są publicznie dostępne.
Czy Scraping Browser jest darmowym narzędziem?
Nie. Scraping Browser jest usługą płatną. Jeśli zarejestrujesz się na bezpłatny okres próbny, narzędzie da ci kredyt w wysokości 5 USD. Płatne pakiety zaczynają się od 15 USD/GB + 0,1 USD/h. Możesz także wybrać opcję Pay As You Go, która zaczyna się od 20 USD/GB + 0,1 USD/h.
Jaka jest różnica między przeglądarkami Scraping a przeglądarkami bezgłowymi?
Scraping Browser to zaawansowana przeglądarka, co oznacza, że ma graficzny interfejs użytkownika (GUI). Z drugiej strony przeglądarki bezgłowe nie mają interfejsu graficznego. Przeglądarki bezgłowe, takie jak Selenium, są używane do automatyzacji przeglądania stron internetowych, ale czasami są ograniczone, ponieważ muszą radzić sobie z kodami CAPTCHA i wykrywaniem botów.
Podsumowanie
Jak widać, Scraping Browser upraszcza wyodrębnianie danych ze stron internetowych. Scraping Browser jest prosty w użyciu w porównaniu do narzędzi takich jak Selenium. Nawet osoby niebędące programistami mogą korzystać z tej przeglądarki z niesamowitym interfejsem użytkownika i dobrą dokumentacją. Narzędzie posiada możliwości odblokowywania niedostępne w innych narzędziach do złomowania, dzięki czemu jest skuteczne dla wszystkich, którzy chcą zautomatyzować takie procesy.
Możesz także dowiedzieć się, jak powstrzymać wtyczki ChatGPT przed pobieraniem treści z Twojej witryny.