Co to jest macierz pomyłek w uczeniu maszynowym?
Macierz pomyłek stanowi istotne narzędzie w procesie oceny efektywności algorytmów uczenia maszynowego, które opierają się na klasyfikacji nadzorowanej.
Czym jest macierz pomyłek?
Ludzkie postrzeganie rzeczywistości jest zróżnicowane, co dotyczy nawet tak fundamentalnych pojęć jak prawda i fałsz. Długość, którą ja oceniam na 10 cm, dla kogoś innego może wynosić 9 cm. Rzeczywista wartość może być jednak inna. To, co postrzegamy, jest pewną prognozą, czyli przewidywaną wartością.
Analogia do ludzkiego myślenia
Tak jak ludzki mózg, bazując na własnej logice, dokonuje przewidywań, tak maszyny wykorzystują rozmaite algorytmy, nazywane algorytmami uczenia maszynowego, aby wyznaczyć przewidywaną wartość. Wartości te mogą być tożsame lub różne od rzeczywistych.
W dynamicznym i konkurencyjnym środowisku kluczowe jest zrozumienie, czy nasze prognozy są prawidłowe. To pozwala nam ocenić wyniki. Podobnie, sprawność algorytmu uczenia maszynowego możemy określić na podstawie tego, jak często jego predykcje pokrywają się z rzeczywistością.
Czym są algorytmy uczenia maszynowego?
Maszyny dążą do uzyskania konkretnych odpowiedzi na problemy, stosując określoną logikę lub zbiór instrukcji, nazywanych algorytmami uczenia maszynowego. Dzielimy je na trzy główne typy: nadzorowane, nienadzorowane i wzmacniające.
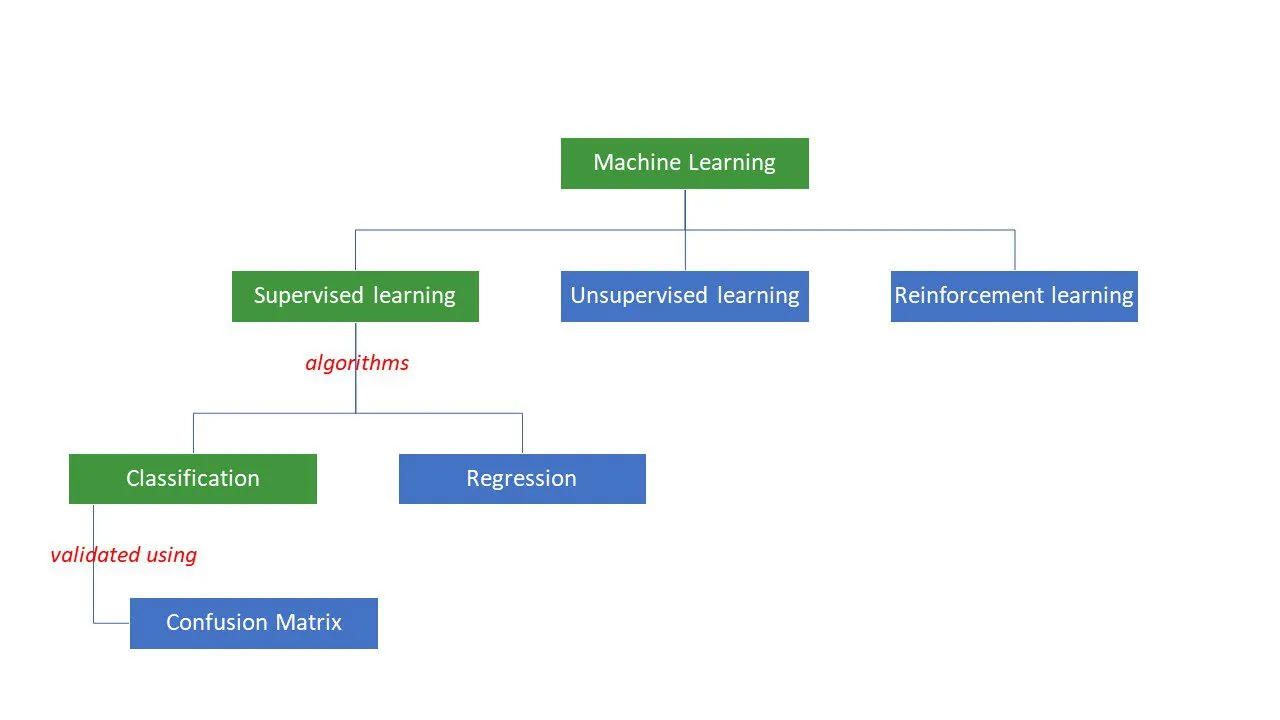 Rodzaje algorytmów uczenia maszynowego
Rodzaje algorytmów uczenia maszynowego
Algorytmy nadzorowane są najprostsze. Tutaj odpowiedź jest nam znana, a zadaniem jest nauczyć maszynę, jak do niej dojść. Algorytm jest trenowany na dużych zbiorach danych, podobnie jak dziecko uczy się rozróżniać osoby w różnym wieku, analizując ich cechy.
Algorytmy nadzorowane ML dzielą się na dwie kategorie: klasyfikację i regresję.
Algorytmy klasyfikacji przyporządkowują dane do określonych kategorii, bazując na ustalonych kryteriach. Przykładowo, jeśli chcesz, by algorytm grupował klientów pod względem preferencji żywieniowych (miłośników i nie-miłośników pizzy), skorzystasz z algorytmu klasyfikacji, takiego jak drzewo decyzyjne, losowy las, naiwny klasyfikator Bayesa lub SVM (Maszyna Wektorów Nośnych).
Który z tych algorytmów będzie najbardziej efektywny? Jak dokonać wyboru między różnymi algorytmami?
Tu pojawia się macierz pomyłek…
Macierz pomyłek to tabela, która prezentuje informacje o tym, jak skuteczny jest algorytm klasyfikacji w przypisywaniu danych do odpowiednich kategorii. Nazwa może być myląca, ale zbyt duża liczba błędnych przewidywań jest sygnałem, że algorytm nie działa poprawnie.
Macierz pomyłek to metoda oceny wydajności algorytmu klasyfikacyjnego.
Jak to działa?
Załóżmy, że zastosowałeś różne algorytmy do zadania binarnej klasyfikacji: podział ludzi na tych, którzy lubią pizzę i tych, którzy za nią nie przepadają. Aby wybrać algorytm, który generuje najbardziej trafne prognozy, skorzystasz z macierzy pomyłek. W przypadku problemu klasyfikacji binarnej (lubię/nie lubię, prawda/fałsz, 1/0) macierz pomyłek składa się z czterech podstawowych wartości:
- Prawdziwie pozytywna (TP)
- Prawdziwie negatywna (TN)
- Fałszywie pozytywna (FP)
- Fałszywie negatywna (FN)
Jakie są cztery składowe macierzy pomyłek?
Te cztery wartości tworzą siatkę macierzy pomyłek.
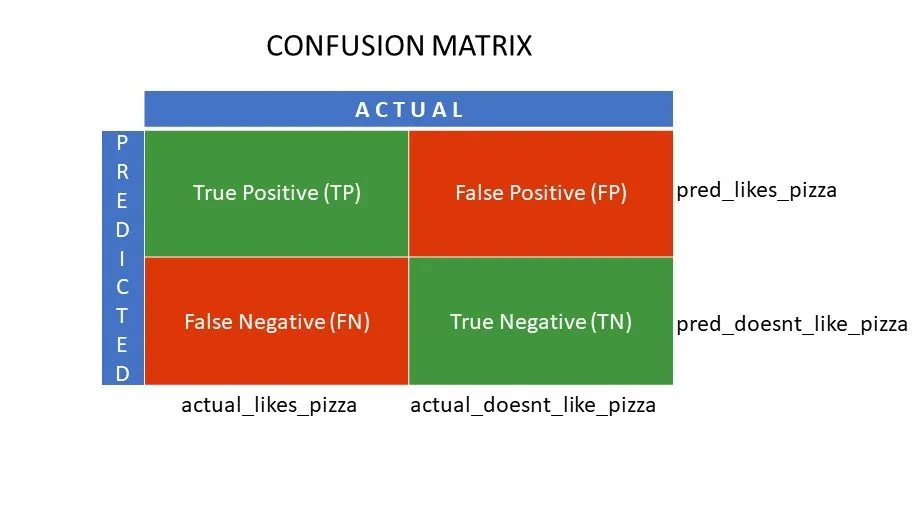 Składowe macierzy pomyłek
Składowe macierzy pomyłek
True Positive (TP) oraz True Negative (TN) oznaczają wartości, które algorytm sklasyfikował poprawnie.
- TP to osoby, które lubią pizzę i model prawidłowo je zidentyfikował.
- TN to osoby, które nie lubią pizzy, a model prawidłowo je sklasyfikował.
False Positive (FP) oraz False Negative (FN) to wartości, które klasyfikator błędnie zaklasyfikował.
- FP to osoby, które nie lubią pizzy (negatywne), a klasyfikator błędnie przypisał je do lubiących pizzę (pozytywne). FP określa się mianem błędu I rodzaju.
- FN to osoby, które lubią pizzę (pozytywne), a klasyfikator nieprawidłowo uznał, że jej nie lubią (negatywne). FN jest nazywane błędem II rodzaju.
Dla lepszego zrozumienia, rozważmy przykład z życia.
Załóżmy, że dysponujesz zbiorem danych 400 osób, które przeszły test na obecność Covid-19. Dysponujesz także wynikami różnych algorytmów, które określiły liczbę osób z wynikiem pozytywnym i negatywnym.
Poniżej przedstawiono dwie macierze pomyłek dla porównania:
Na pierwszy rzut oka można wnioskować, że pierwszy algorytm jest bardziej dokładny. Jednak aby uzyskać konkretną ocenę, potrzebujemy metryk, które umożliwią pomiar dokładności, precyzji i innych wskaźników, które wskażą, który algorytm jest skuteczniejszy.
Metryki wykorzystujące macierz pomyłek i ich znaczenie
Główne wskaźniki, które pozwalają ocenić, czy klasyfikator dokonał właściwych prognoz, to:
#1. Przypomnienie/czułość (Recall/Sensitivity)
Recall, znany też jako Sensitivity lub True Positive Rate (TPR) to stosunek poprawnych pozytywnych prognoz (TP) do wszystkich rzeczywistych pozytywnych (czyli TP i FN).
R = TP/(TP + FN)
Recall mierzy, ile poprawnych wyników dodatnich zostało wykrytych spośród wszystkich możliwych do wykrycia. Wyższa wartość Recall oznacza mniej błędnych negatywnych prognoz, co jest korzystne. Przypomnienie jest ważne, gdy kluczowa jest eliminacja fałszywych wyników negatywnych. Na przykład, jeśli u pacjenta występują poważne problemy z sercem, a algorytm wskazuje, że jest zdrowy, może to mieć tragiczne skutki.
#2. Precyzja (Precision)
Precyzja mierzy, ile poprawnych wyników dodatnich zostało uzyskanych spośród wszystkich wyników przewidzianych jako pozytywne (zarówno prawdziwych, jak i fałszywych).
Pr = TP/(TP + FP)
Precyzja jest istotna, gdy fałszywe alarmy mogą mieć poważne konsekwencje. Na przykład, jeśli pacjent nie ma cukrzycy, ale model to wskazuje, a lekarz przepisuje leki. Może to doprowadzić do poważnych skutków ubocznych.
#3. Specyficzność (Specificity)
Specyficzność, czyli True Negative Rate (TNR), to odsetek prawidłowych wyników ujemnych spośród wszystkich możliwych ujemnych wyników.
S = TN/(TN + FP)
Ta metryka informuje o tym, jak efektywnie klasyfikator rozpoznaje wartości ujemne.
#4. Dokładność (Accuracy)
Dokładność to stosunek liczby poprawnych prognoz do całkowitej liczby prognoz. Zatem, jeśli z próby 50 wyników 20 dodatnich i 10 ujemnych zostało poprawnie zidentyfikowanych, to dokładność modelu wynosi 30/50.
Dokładność A = (TP + TN)/(TP + TN + FP + FN)
#5. Rozpowszechnienie (Prevalence)
Rozpowszechnienie określa odsetek wyników pozytywnych spośród wszystkich analizowanych.
P = (TP + FN)/(TP + TN + FP + FN)
#6. Wynik F (F-score)
Porównywanie dwóch klasyfikatorów (modeli) za pomocą wyłącznie Precyzji i Recall, które są prostymi średnimi arytmetycznymi, może być niewystarczające. W takich sytuacjach można skorzystać z Wyniku F lub F1 Score, który jest średnią harmoniczną, bardziej precyzyjną, gdyż nie ulega tak dużym wahaniom w przypadku wartości ekstremalnych. Im wyższy Wynik F (maksymalnie 1), tym lepszy model.
Wynik F = 2*Precyzja*Recall/ (Recall + Precyzja)
Wynik F1 jest wartościową metryką, gdy istotne jest uwzględnienie zarówno fałszywie pozytywnych, jak i fałszywie negatywnych wyników. Na przykład, osoby, które nie są nosicielami wirusa (ale algorytm je tak sklasyfikował) nie powinny być niepotrzebnie izolowane. Tak samo, osoby zarażone koronawirusem (które algorytm uznał za zdrowe) muszą być poddane izolacji.
7. Krzywe ROC
Parametry takie jak Dokładność i Precyzja są odpowiednie, gdy dane są zbalansowane. W przypadku niezbalansowanego zbioru wysoka Dokładność nie musi świadczyć o efektywności klasyfikatora. Przykładowo, jeśli w grupie 100 uczniów 90 zna język hiszpański, a algorytm stwierdzi, że wszyscy go znają, jego dokładność wyniesie 90%. Może to prowadzić do błędnej oceny modelu. W przypadku niezbalansowanych zbiorów danych, metryki takie jak ROC są bardziej miarodajne.
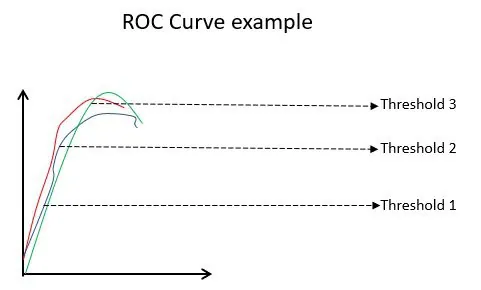 Przykład krzywej ROC
Przykład krzywej ROC
Krzywa ROC (Receiver Operating Characteristic) prezentuje w sposób graficzny efektywność binarnego modelu klasyfikacji przy różnych progach. Przedstawia ona zależność między TPR (True Positive Rate) i FPR (False Positive Rate), które są obliczane jako (1 - specyficzność) dla różnych wartości progowych. Najbardziej dokładną wartością progową jest wartość, która leży najbliżej linii 45 stopni (w lewym górnym rogu). Zbyt wysoki próg zmniejsza liczbę fałszywych trafień, ale zwiększa liczbę fałszywych alarmów. W przeciwnym wypadku, próg zbyt niski powoduje odwrotną zależność.
Ogólnie, porównując krzywe ROC różnych modeli, model z największym obszarem pod krzywą (AUC) uznaje się za lepszy.
Obliczmy teraz wartości wszystkich metryk dla macierzy pomyłek Klasyfikatora I i Klasyfikatora II:
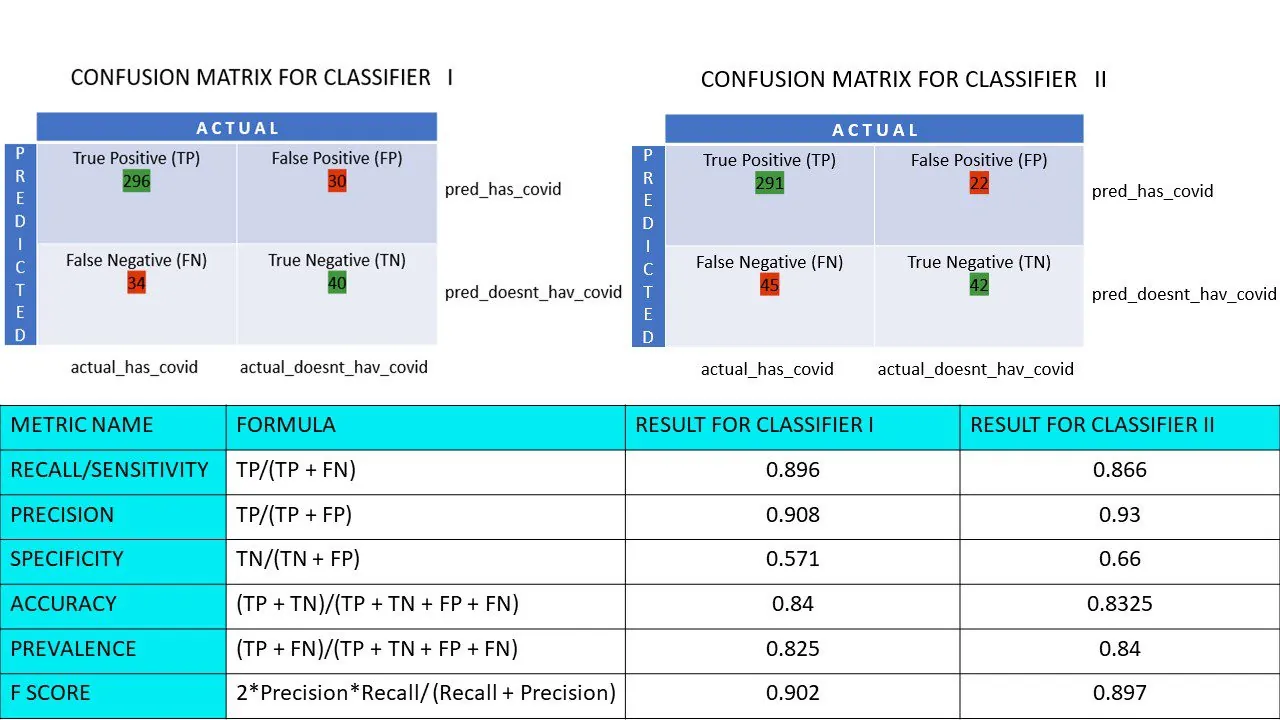 Porównanie metryczne klasyfikatorów 1 i 2 z badania pizzy
Porównanie metryczne klasyfikatorów 1 i 2 z badania pizzy
Widzimy, że Precyzja jest wyższa dla klasyfikatora II, podczas gdy Dokładność jest minimalnie większa dla klasyfikatora I. W zależności od konkretnego problemu, decydenci mogą wybrać Klasyfikator I lub II.
Macierz pomyłek N x N
Do tej pory rozważaliśmy macierz pomyłek dla klasyfikacji binarnej. Co w sytuacji, gdy mamy więcej kategorii, niż tylko tak/nie lub lubię/nie lubię? Na przykład, jeśli algorytm ma za zadanie sortować obrazy na podstawie kolorów (czerwony, zielony, niebieski). Takie zadanie klasyfikacji nazywa się klasyfikacją wieloklasową. Liczba zmiennych wyjściowych determinuje wielkość macierzy. W tym przykładzie macierz pomyłek będzie miała wymiar 3×3.
 Macierz pomyłek dla klasyfikatora wieloklasowego
Macierz pomyłek dla klasyfikatora wieloklasowego
Podsumowanie
Macierz pomyłek stanowi niezwykle wartościowy system oceny, dostarczając szczegółowych informacji o sposobie działania algorytmu klasyfikacyjnego. Sprawdza się zarówno w przypadku klasyfikatorów binarnych, jak i wieloklasowych, gdy należy wziąć pod uwagę więcej niż dwa parametry. Wizualizacja macierzy jest prosta, a wszystkie inne metryki, takie jak Wynik F, Precyzja, ROC i Dokładność, można wygenerować na jej podstawie.
Warto również zapoznać się z metodami doboru algorytmów ML dla problemów regresji.
