

Federated stanowi zerwanie z tradycyjnym sposobem gromadzenia danych i uczenia modeli uczenia maszynowego.
Dzięki uczeniu stowarzyszonemu rozwój uczenia maszynowego korzysta z tańszych szkoleń, które szanują prywatność danych. W tym artykule omówiono, czym jest uczenie się stowarzyszone, jak działa, jakie są zastosowania i struktury.
Spis treści:
Co to jest uczenie się stowarzyszone?
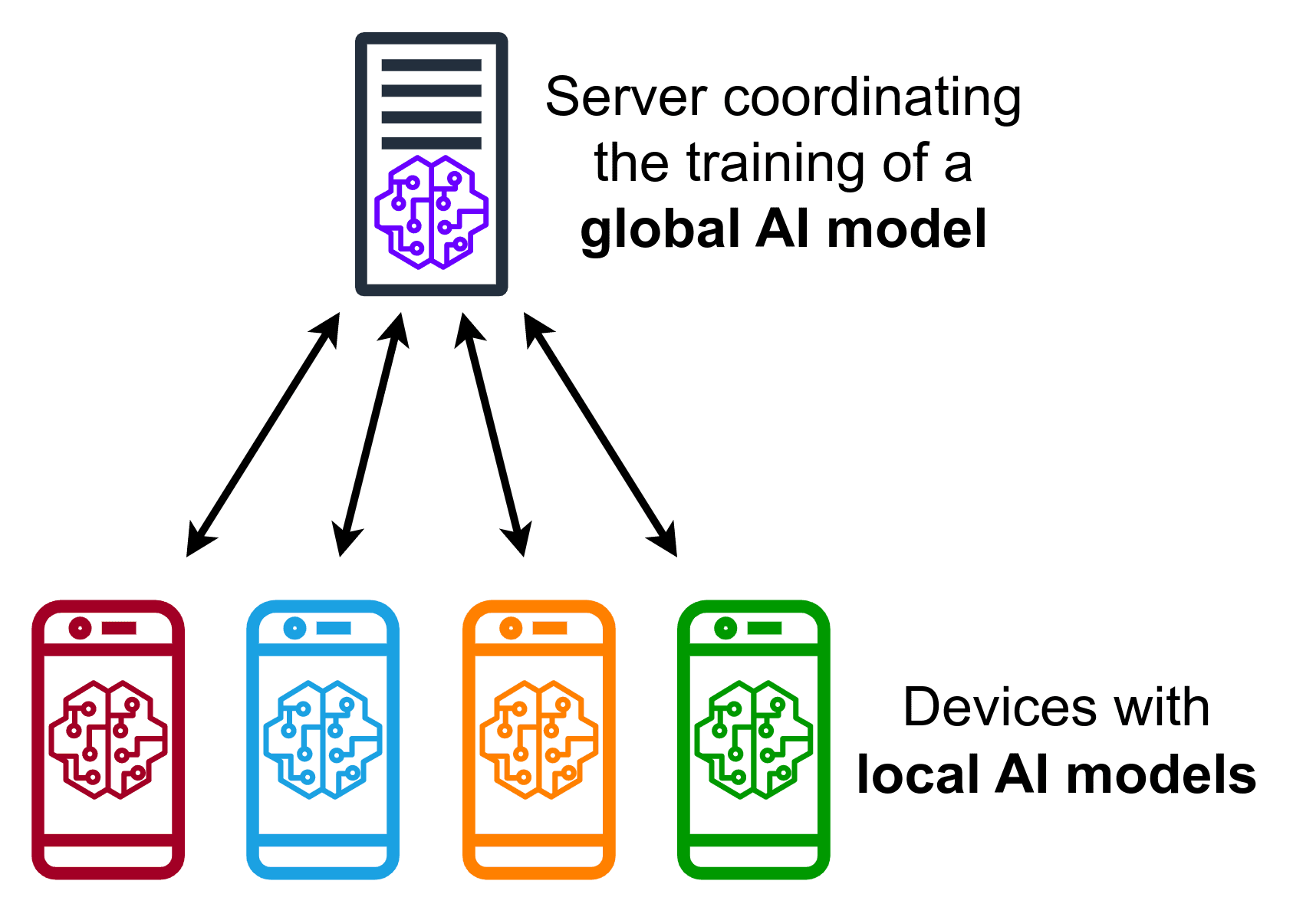 Źródło: Wikipedia
Źródło: Wikipedia
Federated Learning to zmiana w sposobie uczenia modeli uczenia maszynowego. W większości modeli uczenia maszynowego dane są gromadzone w centralnym repozytorium od kilku klientów. Z tego centralnego repozytorium szkolone są modele uczenia maszynowego, a następnie wykorzystywane do prognozowania. Federacyjne uczenie się działa odwrotnie. Zamiast wysyłać dane do centralnego repozytorium, klienci uczą modele na swoich danych. Pomaga im to zachować prywatność ich prywatnych danych.
Przeczytaj także: Wyjaśnienie najlepszych modeli uczenia maszynowego
Jak działa uczenie się stowarzyszone?
Uczenie się w ramach uczenia się stowarzyszonego składa się z szeregu pojedynczych kroków, w wyniku których powstaje model. Kroki te nazywane są rundami uczenia się. Typowa konfiguracja uczenia się powtarza te rundy, ulepszając model na każdym kroku. Każda runda uczenia się obejmuje następujące kroki.
Typowa runda nauki
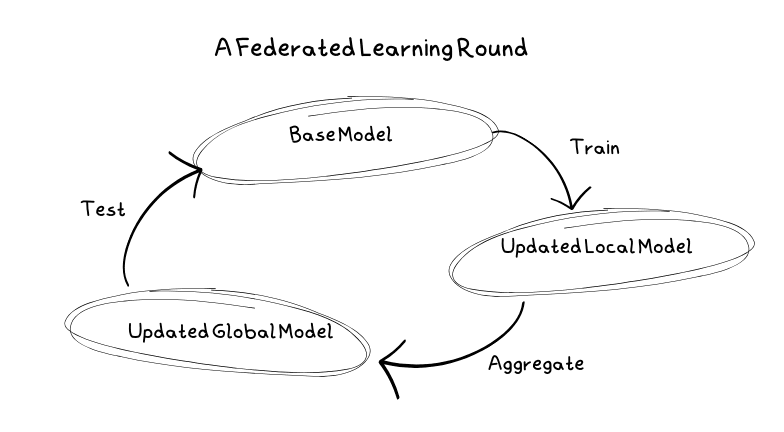
Najpierw serwer wybiera model do trenowania i hiperparametry, takie jak liczba rund, używane węzły klienckie i część węzłów używanych w każdym węźle. W tym momencie model jest również inicjowany z początkowymi parametrami, tworząc model podstawowy.
Następnie klienci otrzymują kopie modelu podstawowego do trenowania. Tymi klientami mogą być urządzenia mobilne, komputery osobiste lub serwery. Uczą model na swoich danych lokalnych, unikając w ten sposób udostępniania wrażliwych danych serwerom.
Gdy klienci przeszkolą model na swoich danych lokalnych, wysyłają go z powrotem na serwer jako aktualizację. Po odebraniu przez serwer aktualizacja jest uśredniana wraz z aktualizacjami od innych klientów w celu utworzenia nowego modelu podstawowego. Ponieważ klienci mogą być zawodni, w tym momencie niektórzy klienci mogą nie wysyłać swoich aktualizacji. W tym momencie serwer obsłuży wszystkie błędy.
Zanim będzie można ponownie wdrożyć model podstawowy, należy go przetestować. Serwer nie przechowuje jednak danych. Dlatego w celu przetestowania modelu jest on odsyłany do klientów, gdzie jest testowany z ich danymi lokalnymi. Jeśli jest lepszy od poprzedniego modelu podstawowego, zostaje przyjęty i używany zamiast niego.
Tutaj jest pomocny przewodnik o tym, jak działa uczenie federacyjne, powiedział zespół ds. uczenia się stowarzyszonego w Google AI.
Scentralizowane vs. Sfederowane vs. Heterogeniczne
W tej konfiguracji istnieje centralny serwer odpowiedzialny za kontrolowanie nauki. Ten typ konfiguracji jest znany jako scentralizowane stowarzyszone uczenie się.
Przeciwieństwem scentralizowanego uczenia się byłoby zdecentralizowane stowarzyszone uczenie się, w którym klienci koordynują się wzajemnie.
Druga konfiguracja nazywa się uczeniem heterogenicznym. W tej konfiguracji klienci niekoniecznie mają tę samą globalną architekturę modelu.
Zalety uczenia się stowarzyszonego
- Największą zaletą korzystania z uczenia stowarzyszonego jest to, że pomaga zachować prywatność prywatnych danych. Klienci dzielą się wynikami szkoleń, a nie danymi wykorzystanymi na szkoleniach. Można również wdrożyć protokoły w celu agregacji wyników, aby nie można było ich powiązać z konkretnym klientem.
- Zmniejsza także przepustowość sieci, ponieważ żadne dane nie są udostępniane pomiędzy klientem a serwerem. Zamiast tego modele są wymieniane między klientem a serwerem.
- Zmniejsza także koszt modeli szkoleniowych, ponieważ nie ma potrzeby kupowania drogiego sprzętu szkoleniowego. Zamiast tego programiści wykorzystują sprzęt klienta do uczenia modeli. Ze względu na niewielką ilość danych nie obciąża urządzenia klienta.
Wady uczenia się stowarzyszonego
- Model ten zależy od udziału wielu różnych węzłów. Niektóre z nich nie są kontrolowane przez dewelopera. Dlatego ich dostępność nie jest gwarantowana. To sprawia, że sprzęt szkoleniowy jest zawodny.
- Klienci, na których szkolone są modele, nie są szczególnie wydajnymi procesorami graficznymi. Zamiast tego są to zwykłe urządzenia, takie jak telefony. Urządzenia te, nawet łącznie, mogą nie mieć wystarczającej mocy w porównaniu z klastrami GPU.
- Uczenie się stowarzyszone zakłada również, że wszystkie węzły klienckie są godne zaufania i działają dla wspólnego dobra. Jednak niektórzy mogą tego nie robić i mogą wydawać złe aktualizacje, powodując dryf modelu.
Zastosowania uczenia się stowarzyszonego
Federated Learning umożliwia naukę przy jednoczesnym zachowaniu prywatności. Jest to przydatne w wielu sytuacjach, np.:
- Podpowiadanie kolejnych słów na klawiaturach smartfonów.
- Urządzenia IoT, które mogą lokalnie szkolić modele pod kątem konkretnych wymagań sytuacji, w której się znajdują.
- Branża farmaceutyczna i opieka zdrowotna.
- Przemysł obronny również odniósłby korzyści z modeli szkoleniowych bez udostępniania wrażliwych danych.
Ramy uczenia się stowarzyszonego
Istnieje wiele ram wdrażania wzorców uczenia się stowarzyszonego. Do najlepszych należą NVFlare, FATE, Flower i PySft. Przeczytaj ten przewodnik, aby uzyskać szczegółowe porównanie różnych frameworków, których możesz użyć.
Wniosek
Artykuł ten stanowił wprowadzenie do Federated Learning, jak to działa, a także zalety i wady jego wdrożenia. Ponadto omówiłem także popularne aplikacje i frameworki wykorzystywane do wdrażania Federated Learning w środowisku produkcyjnym.
Następnie przeczytaj artykuł na temat najlepszych platform MLOps do uczenia modeli uczenia maszynowego.