

Ramki danych to podstawowa struktura danych w R, oferująca strukturę, wszechstronność i narzędzia niezbędne do analizy i manipulacji danymi. Ich znaczenie rozciąga się na różne dziedziny, w tym statystykę, analizę danych i podejmowanie decyzji w oparciu o dane w różnych branżach.
Ramki danych zapewniają strukturę i organizację niezbędną do odblokowania spostrzeżeń i podejmowania decyzji opartych na danych w systematyczny i wydajny sposób.
Ramki danych w R mają strukturę przypominającą tabele, z wierszami i kolumnami. Każdy wiersz reprezentuje obserwację, a każda kolumna reprezentuje zmienną. Taka struktura ułatwia organizowanie i pracę z danymi. Ramki DataFrame mogą przechowywać różne typy danych, w tym liczby, tekst i daty, co czyni je uniwersalnymi.
W tym artykule wyjaśnię znaczenie ramek danych i omówię ich tworzenie za pomocą funkcji data.frame().
Dodatkowo zbadamy metody manipulowania danymi i omówimy, jak tworzyć z plików CSV i Excel, konwertować inne struktury danych na ramki danych i korzystać z biblioteki tibble.
Oto kilka kluczowych powodów, dla których ramki DataFrame są kluczowe w R:
Spis treści:
Znaczenie ramek danych

- Strukturalne przechowywanie danych: Ramki danych zapewniają ustrukturyzowany i tabelaryczny sposób przechowywania danych, podobnie jak arkusz kalkulacyjny. Ten ustrukturyzowany format upraszcza zarządzanie i organizację danych.
- Mieszane typy danych: Ramki danych mogą pomieścić różne typy danych w tej samej strukturze. Możesz mieć kolumny z wartościami liczbowymi, ciągami znaków, współczynnikami, datami i nie tylko. Ta wszechstronność jest niezbędna podczas pracy z danymi ze świata rzeczywistego.
- Organizacja danych: każda kolumna w ramce danych reprezentuje zmienną, a każdy wiersz reprezentuje obserwację lub przypadek. Ten uporządkowany układ ułatwia zrozumienie organizacji danych, poprawiając przejrzystość danych.
- Import i eksport danych: DataFrame obsługują łatwy import i eksport danych z różnych formatów plików, takich jak CSV, Excel i bazy danych. Funkcja ta usprawnia proces pracy z zewnętrznymi źródłami danych.
- Interoperacyjność: Ramki DataFrame są szeroko obsługiwane przez pakiety i funkcje R, zapewniając kompatybilność z innymi narzędziami i bibliotekami statystycznymi i do analizy danych. Ta interoperacyjność pozwala na bezproblemową integrację z ekosystemem R.
- Manipulacja danymi: R oferuje bogaty ekosystem pakietów, a „dplyr” jest tego wyróżniającym się przykładem. Pakiety te ułatwiają filtrowanie, przekształcanie i podsumowywanie danych przy użyciu DataFrames. Możliwość ta ma kluczowe znaczenie przy czyszczeniu i przygotowywaniu danych.
- Analiza statystyczna: Ramki danych to standardowy format danych dla wielu funkcji statystycznych i analiz danych w języku R. Za pomocą ramek DataFrames można efektywnie przeprowadzać regresję, testowanie hipotez i wiele innych analiz statystycznych.
- Wizualizacja: pakiety wizualizacji danych R, takie jak ggplot2, bezproblemowo współpracują z DataFrames. Ułatwia to tworzenie wykresów informacyjnych i wykresów do eksploracji i komunikacji danych.
- Eksploracja danych: Ramki DataFrame ułatwiają eksplorację danych poprzez statystyki podsumowujące, wizualizację i inne metody analityczne. Pomaga to analitykom i badaczom danych zrozumieć charakterystykę danych i wykryć wzorce lub wartości odstające.
Jak utworzyć ramkę danych w R
Istnieje kilka sposobów tworzenia ramki danych w języku R. Oto niektóre z najpopularniejszych metod:
#1. Korzystanie z funkcji data.frame().
# Load the necessary library if not already loaded
if (!require("dplyr")) {
install.packages("dplyr")
library(dplyr)
}
# install.packages("dplyr")
library(dplyr)
# Set a seed for reproducibility
set.seed(42)
# Create a sample sales DataFrame with real product names
sales_data <- data.frame(
OrderID = 1001:1010,
Product = c("Laptop", "Smartphone", "Tablet", "Headphones", "Camera", "TV", "Printer", "Washing Machine", "Refrigerator", "Microwave Oven"),
Quantity = sample(1:10, 10, replace = TRUE),
Price = round(runif(10, 100, 2000), 2),
Discount = round(runif(10, 0, 0.3), 2),
Date = sample(seq(as.Date('2023-01-01'), as.Date('2023-01-10'), by="days"), 10)
)
# Display the sales DataFrame
print(sales_data)
Rozumiemy, co zrobi nasz kod:
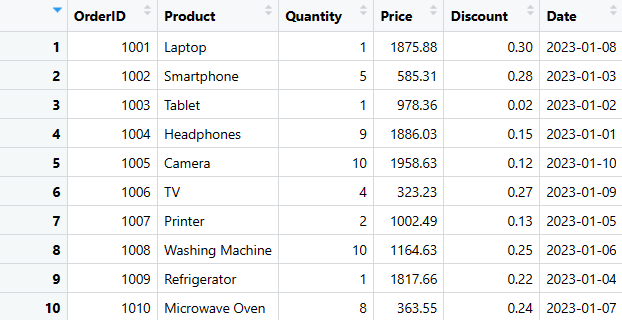 Ramka_danych sprzedaży
Ramka_danych sprzedaży
Jest to jeden z najprostszych sposobów tworzenia ramki DataFrame w języku R. Przyjrzymy się także sposobom wyodrębniania, dodawania, usuwania i wybierania określonych kolumn lub wierszy, a także sposobom podsumowywania danych.
Wyodrębnij kolumny
Istnieją dwie metody wyodrębnienia niezbędnych kolumn z naszej ramki danych:
- Aby pobrać ostatnie trzy kolumny DataFrame w R, możesz użyć indeksowania.
- Możesz wyodrębnić kolumny z ramki danych za pomocą operatora $, jeśli chcesz uzyskać dostęp do poszczególnych kolumn według nazwy.
Aby zaoszczędzić czas, zobaczymy oba razem:
# Extract the last three columns (Discount, Price, and Date) from the sales_data DataFrame
last_three_columns <- sales_data[, c("Discount", "Price", "Date")]
# Display the extracted columns
print(last_three_columns)
############################################# OR #########################################################
# Extract the last three columns (Discount, Price, and Date) using the $ operator
discount_column <- sales_data$Discount
price_column <- sales_data$Price
date_column <- sales_data$Date
# Create a new DataFrame with the extracted columns
last_three_columns <- data.frame(Discount = discount_column, Price = price_column, Date = date_column)
# Display the extracted columns
print(last_three_columns)
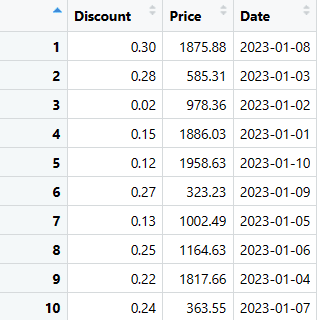
Możesz wyodrębnić niezbędne kolumny, używając dowolnego z tych kodów.
Możesz wyodrębnić wiersze z ramki danych w języku R, korzystając z różnych metod. Oto prosty sposób, aby to zrobić:
# Extract specific rows (rows 3, 6, and 9) from the last_three_columns DataFrame selected_rows <- last_three_columns[c(3, 6, 9), ] # Display the selected rows print(selected_rows)
Możesz także użyć określonych warunków:
# Extract and arrange rows that meet the specified conditions selected_rows <- sales_data %>% filter(Discount < 0.3, Price > 100, format(Date, "%Y-%m") == "2023-01") %>% arrange(OrderID) %>% select(Discount, Price, Date) # Display the selected rows print(selected_rows)
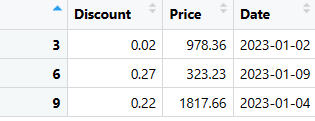 Wyodrębnione wiersze
Wyodrębnione wiersze
Dodaj nowy wiersz
Aby dodać nowy wiersz do istniejącej ramki danych w R, możesz użyć funkcji rbind():
# Create a new row as a data frame
new_row <- data.frame(
OrderID = 1011,
Product = "Coffee Maker",
Quantity = 2,
Price = 75.99,
Discount = 0.1,
Date = as.Date("2023-01-12")
)
# Use the rbind() function to add the new row to the DataFrame
sales_data <- rbind(sales_data, new_row)
# Display the updated DataFrame
print(sales_data)
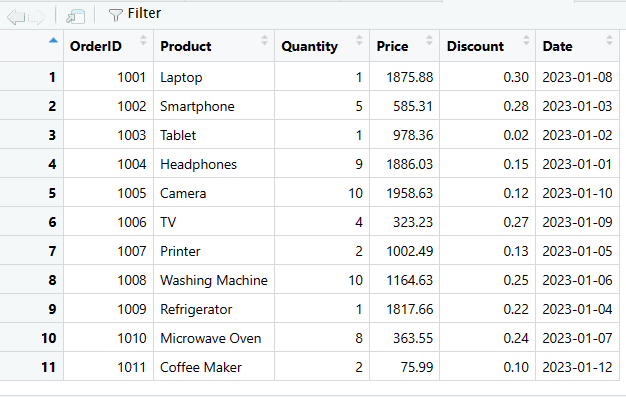 Dodano nowy wiersz
Dodano nowy wiersz
Dodaj nową kolumnę
Możesz dodać kolumny w ramce DataFrame za pomocą prostego kodu. Tutaj chcę dodać kolumnę Metoda płatności do moich danych.
# Create a new column "PaymentMethod" with values for each row
sales_data$PaymentMethod <- c("Credit Card", "PayPal", "Cash", "Credit Card", "Cash", "PayPal", "Cash", "Credit Card", "Credit Card", "Cash", "Credit Card")
# Display the updated DataFrame
print(sales_data)
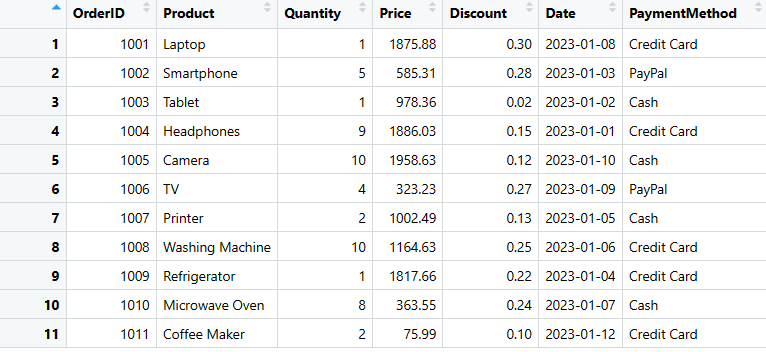 Kolumna dodana w ramce danych
Kolumna dodana w ramce danych
Usuń wiersze
Jeśli chcesz usunąć niepotrzebne wiersze, ta metoda może być pomocna:
# Identify the row to be deleted by its OrderID row_to_delete <- sales_data$OrderID == 1010 # Use the identified row to exclude it and create a new DataFrame sales_data <- sales_data[!row_to_delete, ] # Display the updated DataFrame without the deleted row print(sales_data)
Usuń kolumny
Możesz usunąć kolumnę z ramki danych w R za pomocą pakietu dplyr.
# install.packages("dplyr")
library(dplyr)
# Remove the "Discount" column using the select() function
sales_data <- sales_data %>% select(-Discount)
# Display the updated DataFrame without the "Discount" column
print(sales_data)
Uzyskaj podsumowanie
Aby uzyskać podsumowanie danych w R, możesz użyć funkcji podsumowania(). Ta funkcja zapewnia szybki przegląd głównych tendencji i rozkładu zmiennych numerycznych w danych.
# Obtain a summary of the data data_summary <- summary(sales_data) # Display the summary print(data_summary)
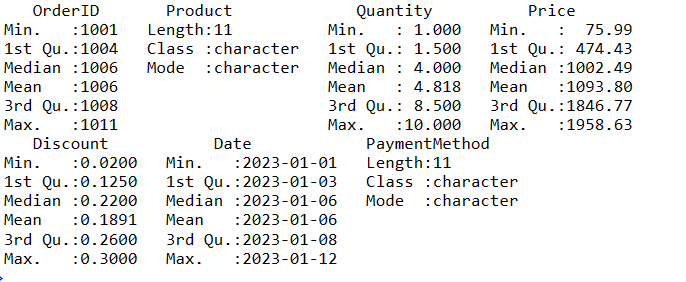
Oto kilka kroków, które możesz wykonać, aby manipulować danymi w ramce DataFrame.
Przejdźmy do drugiej metody tworzenia DataFrame.
#2. Utwórz ramkę danych R z pliku CSV
Aby utworzyć ramkę danych R z pliku CSV, możesz użyć funkcji read.csv()
# Read the CSV file into a DataFrame
df <- read.csv("my_data.csv")
# View the first few rows of the DataFrame
head(df)
Funkcja ta odczytuje dane z pliku CSV i je konwertuje. Następnie możesz pracować z danymi w R, jeśli zajdzie taka potrzeba.
# Install and load the readr package if not already installed
if (!requireNamespace("readr", quietly = TRUE)) {
install.packages("readr")
}
library(readr)
# Read the CSV file into a DataFrame
df <- read_csv("data.csv")
# View the first few rows of the DataFrame
head(df)
możesz użyć pakietu readr do odczytania pliku CSV w R. W tym celu powszechnie używana jest funkcja read_csv() z pakietu readr. Jest szybsza niż zwykła metoda.
#3. Korzystanie z funkcji as.data.frame().
Możesz utworzyć ramkę danych w R za pomocą funkcji as.data.frame(). Ta funkcja umożliwia konwersję innych struktur danych, takich jak macierze lub listy, na ramkę DataFrame.
Oto jak z niego korzystać:
# Create a nested list to represent the data
data_list <- list(
OrderID = 1001:1011,
Product = c("Laptop", "Smartphone", "Tablet", "Headphones", "Camera", "TV", "Printer", "Washing Machine", "Refrigerator", "Microwave Oven", "Coffee Maker"),
Quantity = c(1, 5, 1, 9, 10, 4, 2, 10, 1, 8, 2),
Price = c(1875.88, 585.31, 978.36, 1886.03, 1958.63, 323.23, 1002.49, 1164.63, 1817.66, 363.55, 75.99),
Discount = c(0.3, 0.28, 0.02, 0.15, 0.12, 0.27, 0.13, 0.25, 0.22, 0.24, 0.1),
Date = as.Date(c("2023-01-08", "2023-01-03", "2023-01-02", "2023-01-01", "2023-01-10", "2023-01-09", "2023-01-05", "2023-01-06", "2023-01-04", "2023-01-07", "2023-01-12")),
PaymentMethod = c("Credit Card", "PayPal", "Cash", "Credit Card", "Cash", "PayPal", "Cash", "Credit Card", "Credit Card", "Cash", "Credit Card")
)
# Convert the nested list to a DataFrame
sales_data <- as.data.frame(data_list)
# Display the DataFrame
print(sales_data)
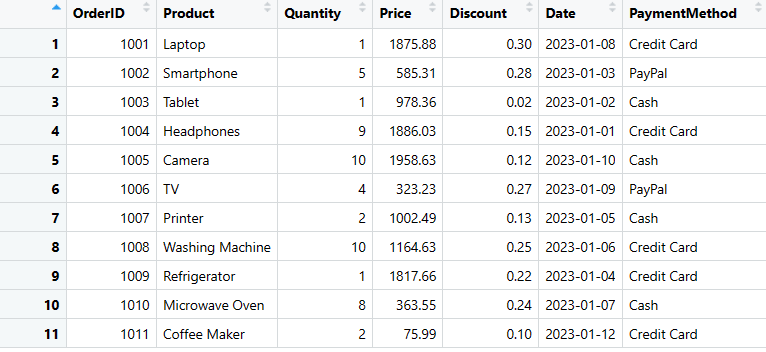 Dane_sprzedaży
Dane_sprzedaży
Ta metoda umożliwia utworzenie DataFrame bez określania każdej kolumny jedna po drugiej i jest szczególnie przydatna, gdy masz dużą ilość danych.
#4. Z istniejącej ramki danych
Aby utworzyć nową ramkę danych, wybierając określone kolumny lub wiersze z istniejącej ramki danych w R, możesz użyć nawiasów kwadratowych [] do indeksowania. Oto jak to działa:
# Select rows and columns
sales_subset <- sales_data[c(1, 3, 4), c("Product", "Quantity")]
# Display the selected subset
print(sales_subset)
W tym kodzie tworzymy nową ramkę danych o nazwie sales_subset, która zawiera określone wiersze (1, 3 i 4) oraz określone kolumny („Produkt” i „Ilość”) z danych sales_data.
Możesz dostosować indeksy i nazwy wierszy i kolumn, aby wybrać potrzebne dane.
 Podzbiór sprzedaży
Podzbiór sprzedaży
#5. Z wektora
Wektor to jednowymiarowa struktura danych w języku R, która składa się z elementów tego samego typu danych, w tym logicznych, całkowitych, podwójnych, znakowych, złożonych lub surowych.
Z drugiej strony ramka danych R to dwuwymiarowa struktura przeznaczona do przechowywania danych w formacie tabelarycznym z wierszami i kolumnami. Istnieją różne metody tworzenia ramki danych R z wektora, a jeden z takich przykładów przedstawiono poniżej.
# Create vectors for each column
OrderID <- 1001:1011
Product <- c("Laptop", "Smartphone", "Tablet", "Headphones", "Camera", "TV", "Printer", "Washing Machine", "Refrigerator", "Microwave Oven", "Coffee Maker")
Quantity <- c(1, 5, 1, 9, 10, 4, 2, 10, 1, 8, 2)
Price <- c(1875.88, 585.31, 978.36, 1886.03, 1958.63, 323.23, 1002.49, 1164.63, 1817.66, 363.55, 75.99)
Discount <- c(0.3, 0.28, 0.02, 0.15, 0.12, 0.27, 0.13, 0.25, 0.22, 0.24, 0.1)
Date <- as.Date(c("2023-01-08", "2023-01-03", "2023-01-02", "2023-01-01", "2023-01-10", "2023-01-09", "2023-01-05", "2023-01-06", "2023-01-04", "2023-01-07", "2023-01-12"))
PaymentMethod <- c("Credit Card", "PayPal", "Cash", "Credit Card", "Cash", "PayPal", "Cash", "Credit Card", "Credit Card", "Cash", "Credit Card")
# Create the DataFrame using data.frame()
sales_data <- data.frame(
OrderID = OrderID,
Product = Product,
Quantity = Quantity,
Price = Price,
Discount = Discount,
Date = Date,
PaymentMethod = PaymentMethod
)
# Display the DataFrame
print(sales_data)
W tym kodzie tworzymy osobne wektory dla każdej kolumny, a następnie używamy funkcji data.frame() w celu połączenia tych wektorów w ramkę danych o nazwie sales_data.
Umożliwia to utworzenie strukturalnej tabelarycznej ramki danych z poszczególnych wektorów w języku R.
#6. Z pliku Excel
Aby utworzyć ramkę DataFrame poprzez import pliku Excel w języku R, możesz skorzystać z pakietów innych firm, takich jak readxl, ponieważ podstawowy R nie oferuje natywnej obsługi odczytu plików CSV. Jedną z takich funkcji do odczytu plików Excel jest read_excel().
# Load the readxl library library(readxl) # Define the file path to the Excel file excel_file_path <- "your_file.xlsx" # Replace with the actual file path # Read the Excel file and create a DataFrame data_frame_from_excel <- read_excel(excel_file_path) # Display the DataFrame print(data_frame_from_excel)
Ten kod odczyta plik Excel i zapisze jego dane w ramce danych R, umożliwiając pracę z danymi w środowisku R.
#7. Z pliku tekstowego
Możesz zastosować funkcję read.table() w R, aby zaimportować plik tekstowy do ramki DataFrame. Funkcja ta wymaga dwóch podstawowych parametrów: nazwy pliku, który chcesz przeczytać oraz ogranicznika, który określa sposób oddzielenia pól w pliku.
# Define the file name and delimiter file_name <- "your_text_file.txt" # Replace with the actual file name delimiter <- "\t" # Replace with the actual delimiter (e.g., "\t" for tab-separated, "," for CSV) # Use the read.table() function to create a DataFrame data_frame_from_text <- read.table(file_name, header = TRUE, sep = delimiter) # Display the DataFrame print(data_frame_from_text)
Ten kod odczyta plik tekstowy i utworzy go w języku R, udostępniając go do analizy danych w środowisku R.
#8. Korzystanie z Tibble’a
Aby utworzyć go przy użyciu dostarczonych wektorów i skorzystać z biblioteki tidyverse, możesz wykonać następujące kroki:
# Load the tidyverse library
library(tidyverse)
# Create a tibble using the provided vectors
sales_data <- tibble(
OrderID = 1001:1011,
Product = c("Laptop", "Smartphone", "Tablet", "Headphones", "Camera", "TV", "Printer", "Washing Machine", "Refrigerator", "Microwave Oven", "Coffee Maker"),
Quantity = c(1, 5, 1, 9, 10, 4, 2, 10, 1, 8, 2),
Price = c(1875.88, 585.31, 978.36, 1886.03, 1958.63, 323.23, 1002.49, 1164.63, 1817.66, 363.55, 75.99),
Discount = c(0.3, 0.28, 0.02, 0.15, 0.12, 0.27, 0.13, 0.25, 0.22, 0.24, 0.1),
Date = as.Date(c("2023-01-08", "2023-01-03", "2023-01-02", "2023-01-01", "2023-01-10", "2023-01-09", "2023-01-05", "2023-01-06", "2023-01-04", "2023-01-07", "2023-01-12")),
PaymentMethod = c("Credit Card", "PayPal", "Cash", "Credit Card", "Cash", "PayPal", "Cash", "Credit Card", "Credit Card", "Cash", "Credit Card")
)
# Display the created sales tibble
print(sales_data)
W tym kodzie użyto funkcji tibble() z biblioteki tidyverse do utworzenia ramki danych tibble o nazwie sales_data. Jak wspomniałeś, format tibble zapewnia drukowanie zawierające więcej informacji w porównaniu z domyślną ramką danych R.
Jak efektywnie używać ramek danych w R
Efektywne używanie DataFrames w R jest niezbędne do manipulacji i analizy danych. Ramki danych są podstawową strukturą danych w języku R i zazwyczaj są tworzone i manipulowane przy użyciu funkcji data.frame. Oto kilka wskazówek, jak efektywnie pracować:
- Przed utworzeniem upewnij się, że Twoje dane są czyste i mają dobrą strukturę. Usuń wszystkie niepotrzebne wiersze lub kolumny, zajmij się brakującymi wartościami i upewnij się, że typy danych są odpowiednie.
- Ustaw odpowiednie typy danych dla swoich kolumn (np. numeryczne, znakowe, współczynnikowe, daty). Może to poprawić wykorzystanie pamięci i szybkość obliczeń.
- Użyj indeksowania i podzbiorów, aby pracować z mniejszymi porcjami danych. Podzbiór() i [ ] operatory są do tego przydatne.
- Funkcja dołączania() i odłączania() może być wygodna, ale może również prowadzić do niejednoznaczności i nieoczekiwanego zachowania.
- R jest wysoce zoptymalizowany pod kątem operacji wektorowych. Jeśli to możliwe, do manipulacji danymi używaj funkcji wektorowych zamiast pętli.
- Zagnieżdżone pętle mogą działać wolno w R. Zamiast zagnieżdżonych pętli spróbuj użyć operacji wektorowych lub zastosować funkcje takie jak lapply lub sapply.
- Duże ramki danych mogą zużywać dużo pamięci. Rozważ użycie pakietów data.table lub dtplyr, które są bardziej wydajne pod względem pamięci w przypadku większych zestawów danych.
- R oferuje szeroką gamę pakietów do manipulacji danymi. Wykorzystaj pakiety takie jak dplyr, tidyr i data.table do wydajnej transformacji danych.
- Minimalizuj użycie zmiennych globalnych, szczególnie podczas pracy z wieloma ramkami danych. Użyj funkcji i przekaż DataFrames jako argumenty.
- Podczas pracy z danymi zagregowanymi użyj funkcji group_by() i podsumowania() w dplyr, aby efektywnie wykonywać obliczenia.
- W przypadku dużych zestawów danych rozważ użycie przetwarzania równoległego z pakietami takimi jak równoległy lub foreach, aby przyspieszyć operacje.
- Podczas wczytywania danych do R używaj funkcji takich jak readr lub data.table::fread zamiast podstawowych funkcji R, takich jak read.csv, aby przyspieszyć import danych.
- W przypadku bardzo dużych zbiorów danych rozważ użycie systemów baz danych lub wyspecjalizowanych formatów przechowywania, takich jak Feather, Arrow lub Parquet.
Postępując zgodnie z tymi najlepszymi praktykami, możesz wydajnie pracować z ramkami DataFrames w R, dzięki czemu zadania manipulacji i analizy danych są łatwiejsze w zarządzaniu i szybsze.
Końcowe przemyślenia
Tworzenie ramek danych w R jest proste i masz do dyspozycji różne metody. Podkreśliłem znaczenie ramek danych i omówiłem ich tworzenie za pomocą funkcji data.frame().
Dodatkowo zbadaliśmy metody manipulowania danymi i omówiliśmy sposoby tworzenia z plików CSV i Excel, konwertowania innych struktur danych na ramki danych i korzystania z biblioteki tibble.
Być może zainteresują Cię najlepsze środowiska IDE do programowania w języku R.