Wyjaśnienie regresji a klasyfikacja w uczeniu maszynowym
Regresja i klasyfikacja stanowią dwa fundamentalne filary w obszarze uczenia maszynowego, posiadające ogromne znaczenie w tej dziedzinie.
Dla osób dopiero rozpoczynających swoją przygodę z uczeniem maszynowym, odróżnienie algorytmów regresji od algorytmów klasyfikacji może być niełatwe. Zrozumienie sposobu działania tych algorytmów oraz wiedza, kiedy należy je stosować, jest kluczowa dla osiągnięcia trafnych prognoz i podejmowania skutecznych decyzji.
Zacznijmy od podstaw, czyli czym właściwie jest uczenie maszynowe.
Czym jest uczenie maszynowe?
Uczenie maszynowe to podejście, w którym komputery uczą się i podejmują decyzje w sposób autonomiczny, bez potrzeby bezpośredniego programowania. Opiera się ono na trenowaniu modelu komputerowego na podstawie obszernego zbioru danych. Dzięki temu model jest w stanie wyodrębnić wzorce i relacje w danych, co umożliwia mu dokonywanie predykcji lub podejmowanie decyzji.
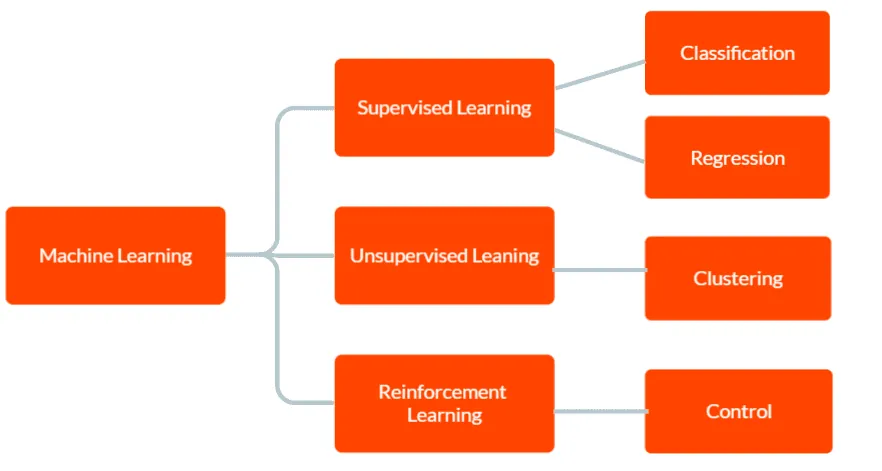
Wyróżniamy trzy główne kategorie uczenia maszynowego: uczenie nadzorowane, uczenie nienadzorowane oraz uczenie ze wzmocnieniem.
W uczeniu nadzorowanym model otrzymuje etykietowane dane treningowe, zawierające zarówno dane wejściowe, jak i odpowiadające im prawidłowe dane wyjściowe. Celem tego procesu jest umożliwienie modelowi przewidywania danych wyjściowych dla nowych, nieznanych wcześniej danych, w oparciu o wzorce, które model wypracował podczas treningu.
W uczeniu nienadzorowanym model nie korzysta z etykietowanych danych treningowych. Zamiast tego samodzielnie analizuje dane, aby odkryć ukryte wzorce i zależności. Może to posłużyć do identyfikacji grup lub klastrów w zbiorze danych lub do wykrycia anomalii czy nietypowych schematów.
Z kolei uczenie ze wzmocnieniem polega na tym, że agent uczy się poprzez interakcję z otoczeniem, dążąc do maksymalizacji uzyskanej nagrody. W tym przypadku model jest trenowany do podejmowania decyzji w oparciu o informacje zwrotne, które otrzymuje ze środowiska.
Uczenie maszynowe znajduje zastosowanie w wielu różnych dziedzinach, takich jak rozpoznawanie obrazów i mowy, przetwarzanie języka naturalnego, wykrywanie oszustw, a nawet w autonomicznych pojazdach. Ma ono potencjał do automatyzacji wielu zadań i usprawnienia procesu decyzyjnego w wielu branżach.
Ten artykuł skupi się na koncepcjach klasyfikacji i regresji, które mieszczą się w obszarze uczenia nadzorowanego. Przejdźmy zatem do szczegółów!
Klasyfikacja w uczeniu maszynowym

Klasyfikacja jest metodą uczenia maszynowego, w której model jest trenowany w celu przypisania odpowiedniej etykiety klasowej do analizowanych danych. Jest to przykład uczenia nadzorowanego, co oznacza, że model trenowany jest na podstawie etykietowanego zbioru danych. Zbiór ten składa się z par danych wejściowych oraz odpowiadających im etykiet klas.
Model ma za zadanie nauczyć się zależności pomiędzy danymi wejściowymi a etykietami klas, aby móc przewidywać etykietę klasy dla nowych, nieznanych danych wejściowych.
Istnieje wiele różnych algorytmów, które można zastosować do klasyfikacji. Wśród nich warto wymienić regresję logistyczną, drzewa decyzyjne oraz maszyny wektorów nośnych. Wybór algorytmu zależy od charakterystyki analizowanych danych oraz oczekiwanej efektywności modelu.
Do popularnych zastosowań klasyfikacji zaliczamy między innymi wykrywanie spamu, analizę sentymentu oraz wykrywanie oszustw. W każdym z tych przypadków, dane wejściowe mogą składać się z tekstu, wartości liczbowych, lub ich kombinacji. Etykiety klas mogą być binarne (np. spam lub nie spam) lub wieloklasowe (np. nastawienie pozytywne, neutralne, negatywne).
Rozważmy dla przykładu zbiór danych z recenzjami klientów na temat produktu. Danymi wejściowymi może być treść recenzji, a etykietą klasy ocena (np. pozytywna, neutralna, negatywna). Model trenowany jest na zbiorze danych zawierającym recenzje, które zostały wcześniej oznaczone. Po przeszkoleniu model jest w stanie przewidzieć ocenę dla nowej, nieznanej wcześniej recenzji.
Typy algorytmów klasyfikacji ML
W uczeniu maszynowym istnieje kilka typów algorytmów klasyfikacyjnych:
Regresja logistyczna
Jest to model liniowy wykorzystywany do klasyfikacji binarnej. Używany jest do przewidywania prawdopodobieństwa wystąpienia określonego zdarzenia. Celem regresji logistycznej jest znalezienie optymalnych współczynników (wag), które minimalizują różnicę pomiędzy przewidywanym prawdopodobieństwem a zaobserwowanym wynikiem.
Realizuje się to za pomocą algorytmu optymalizacji, takiego jak spadek gradientu, który dostosowuje współczynniki do momentu, w którym model jak najlepiej pasuje do danych treningowych.
Drzewa decyzyjne
Drzewa decyzyjne to modele przypominające strukturą drzewa, które podejmują decyzje na podstawie wartości cech. Można je stosować zarówno w klasyfikacji binarnej, jak i wieloklasowej. Drzewa decyzyjne charakteryzują się prostotą oraz łatwością interpretacji.
Szybko uczą się i generują prognozy. Dodatkowo mogą analizować zarówno dane numeryczne, jak i kategoryczne. Należy jednak pamiętać, że są one podatne na przeuczenie, szczególnie gdy drzewo jest rozbudowane i posiada wiele gałęzi.
Klasyfikacja losowych lasów
Klasyfikacja losowych lasów to metoda zespołowa, łącząca prognozy z wielu drzew decyzyjnych, co przekłada się na dokładniejsze i stabilniejsze prognozy. Jest mniej podatna na przeuczenie niż pojedyncze drzewo decyzyjne. Wynika to z faktu, że prognozy poszczególnych drzew są uśredniane, co zmniejsza wariancję modelu.
AdaBoost
To algorytm wzmacniający, który adaptacyjnie modyfikuje wagę błędnie zaklasyfikowanych przykładów w zbiorze uczącym. Najczęściej wykorzystywany jest w klasyfikacji binarnej.
Naiwny Bayes
Naiwny Bayes opiera się na twierdzeniu Bayesa, które pozwala zaktualizować prawdopodobieństwo zdarzenia na podstawie nowych dowodów. Jest to klasyfikator probabilistyczny, często stosowany w klasyfikacji tekstu i filtrowaniu spamu.
K-Najbliższych sąsiadów
Algorytm K-Najbliższych sąsiadów (KNN) znajduje zastosowanie zarówno w klasyfikacji, jak i regresji. Jest to metoda nieparametryczna, która klasyfikuje punkt danych w oparciu o klasę jego najbliższych sąsiadów. KNN cechuje się prostotą oraz łatwością implementacji. Może również pracować zarówno na danych numerycznych, jak i kategorycznych. Nie zakłada on również żadnych założeń dotyczących rozkładu danych.
Wzmocnienie gradientowe
Modele te stanowią zespoły słabych uczniów, które są trenowane sekwencyjnie. Każdy model próbuje skorygować błędy poprzedniego. Wykorzystuje się je zarówno w klasyfikacji, jak i regresji.
Regresja w uczeniu maszynowym
W uczeniu maszynowym regresja stanowi przykład uczenia nadzorowanego, w którym celem jest przewidywanie wartości zmiennej zależnej na podstawie jednej lub więcej cech wejściowych (zwanych predyktorami lub zmiennymi niezależnymi).
Algorytmy regresji służą do modelowania zależności między danymi wejściowymi i wyjściowymi oraz do generowania prognoz na podstawie tych zależności. Regresja może być stosowana zarówno w przypadku zmiennych zależnych o charakterze ciągłym, jak i kategorycznym.
Ogólnie rzecz biorąc, celem regresji jest utworzenie modelu, który jest w stanie dokładnie przewidzieć dane wyjściowe na podstawie cech wejściowych i zrozumieć fundamentalną zależność pomiędzy tymi cechami a wynikami.
Analiza regresji znajduje zastosowanie w wielu dziedzinach, takich jak ekonomia, finanse, marketing i psychologia, do analizy i prognozowania zależności między różnymi zmiennymi. Jest to podstawowe narzędzie w analizie danych i uczeniu maszynowym, wykorzystywane do prognozowania, identyfikacji trendów i zrozumienia mechanizmów leżących u podstaw danych.
Na przykład, w prostym modelu regresji liniowej, celem może być przewidzenie ceny domu na podstawie jego wielkości, lokalizacji i innych cech. Wielkość domu i jego lokalizacja byłyby zmiennymi niezależnymi, natomiast cena domu byłaby zmienną zależną.
Model jest trenowany na danych wejściowych obejmujących wielkość i lokalizację kilku domów oraz ich ceny. Po przeszkoleniu, model może zostać wykorzystany do przewidywania ceny domu na podstawie jego wielkości i lokalizacji.
Typy algorytmów regresji ML
Istnieje wiele różnych algorytmów regresji. Wybór konkretnego zależy od szeregu parametrów, takich jak typ wartości atrybutu, wzór linii trendu oraz liczba zmiennych niezależnych. Najczęściej stosowane techniki regresji to:
Regresja liniowa
Ten prosty model liniowy służy do przewidywania wartości ciągłej na podstawie zestawu cech. Używa się go do modelowania zależności między cechami a zmienną docelową poprzez dopasowanie linii do danych.
Regresja wielomianowa
Jest to model nieliniowy wykorzystywany do dopasowania krzywej do danych. Używa się go do modelowania relacji pomiędzy cechami a zmienną docelową, gdy zależność ta nie jest liniowa. Opiera się na dodawaniu terminów wyższego rzędu do modelu liniowego, w celu uchwycenia nieliniowych zależności między zmiennymi zależnymi i niezależnymi.
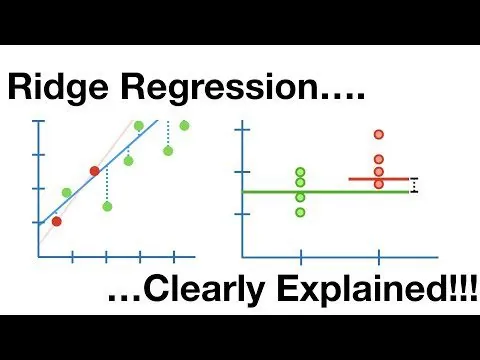
Regresja grzbietowa
Jest to model liniowy, który rozwiązuje problem nadmiernego dopasowania w regresji liniowej. To uregulowana odmiana regresji liniowej, która dodaje do funkcji kosztu element karny, w celu zmniejszenia złożoności modelu.
Regresja wektorów nośnych
Podobnie jak maszyny SVM, regresja wektorów nośnych jest modelem liniowym, który próbuje dopasować dane poprzez znalezienie hiperpłaszczyzny, która maksymalizuje margines między zmiennymi zależnymi i niezależnymi.
Jednak, w odróżnieniu od SVM, które są stosowane w klasyfikacji, SVR służy do zadań regresji, gdzie celem jest przewidywanie wartości ciągłej, a nie etykiety klasy.
Regresja Lasso
To kolejna uregulowana odmiana modelu liniowego, służąca do zapobiegania nadmiernemu dopasowaniu w regresji liniowej. Dodaje do funkcji kosztu element karny w oparciu o wartość bezwzględną współczynników.
Bayesowska regresja liniowa
Bayesowska regresja liniowa to probabilistyczne podejście do regresji liniowej oparte na twierdzeniu Bayesa, które pozwala zaktualizować prawdopodobieństwo zdarzenia na podstawie nowych dowodów.
Ten model regresji ma na celu oszacowanie późniejszego rozkładu parametrów modelu na podstawie danych. Realizuje się to poprzez zdefiniowanie wcześniejszego rozkładu parametrów, a następnie użycie twierdzenia Bayesa do zaktualizowania rozkładu na podstawie zaobserwowanych danych.
Regresja a klasyfikacja
Regresja i klasyfikacja są dwoma rodzajami uczenia nadzorowanego, co oznacza, że są wykorzystywane do prognozowania wyników na podstawie zestawu cech wejściowych. Istnieje jednak kilka kluczowych różnic między nimi:
RegresjaKlasyfikacjaDefinicjaTyp uczenia nadzorowanego, który przewiduje wartość ciągłąTyp uczenia nadzorowanego, który przewiduje wartość kategorycznąTyp wynikuCiągłeDyskretneMetryki ocenyŚredni błąd kwadratowy (MSE), pierwiastek błędu średniokwadratowego (RMSE)Dokładność, precyzja, czułość, wynik F1AlgorytmyRegresja liniowa, Lasso, Ridge, KNN, Drzewo decyzyjneRegresja logistyczna, SVM, Naïve Bayes, KNN, Drzewo decyzyjneZłożoność modeluModele mniej złożoneModele bardziej złożoneZałożeniaLiniowa zależność między cechami a celemBrak konkretnych założeń dotyczących relacji między cechami a wartością docelowąNierównowaga klasNie dotyczyMoże stanowić problemWartości odstająceMogą wpływać na wydajność modeluZwykle nie stanowią problemuWażność cechyCechy są uszeregowane według ważnościCechy nie są uszeregowane według ważnościPrzykładowe zastosowaniaPrzewidywanie cen, temperatur, ilościPrzewidywanie spamu e-mailowego, przewidywanie rezygnacji klientów
Zasoby edukacyjne
Wybór najlepszych źródeł do nauki koncepcji uczenia maszynowego może być trudne. Przeanalizowaliśmy popularne kursy oferowane przez sprawdzone platformy, aby przedstawić nasze rekomendacje dotyczące najlepszych kursów ML dotyczących regresji i klasyfikacji.
# 1. Bootcamp klasyfikacji uczenia maszynowego w Pythonie
Jest to kurs dostępny na platformie Udemy. Obejmuje różnorodne algorytmy i techniki klasyfikacji, w tym drzewa decyzyjne i regresję logistyczną, a także maszyny wektorów nośnych.

Możesz także zapoznać się z tematami takimi jak nadmierne dopasowanie, kompromis między obciążeniem a wariancją oraz ocena modelu. W trakcie kursu wykorzystywane są biblioteki Pythona, takie jak sci-kit-learn i pandas, do implementacji i oceny modeli uczenia maszynowego. Aby rozpocząć ten kurs, wymagana jest podstawowa wiedza z zakresu języka Python.
#2. Masterclass regresji uczenia maszynowego w Pythonie
W tym kursie na Udemy instruktor omawia podstawy i teorię różnych algorytmów regresji, w tym regresji liniowej, wielomianowej oraz technik regresji Lasso & Ridge.

Po zakończeniu tego kursu będziesz w stanie wdrożyć algorytmy regresji i ocenić wydajność wytrenowanych modeli uczenia maszynowego za pomocą różnych kluczowych wskaźników wydajności.
Podsumowanie
Algorytmy uczenia maszynowego znajdują szerokie zastosowanie w różnych aplikacjach, pomagając zautomatyzować i usprawnić wiele procesów. Wykorzystują one techniki statystyczne, aby uczyć się wzorców w danych i na ich podstawie dokonywać prognoz lub podejmować decyzje.
Można je trenować na dużych zbiorach danych i wykorzystywać do realizacji zadań, które byłyby trudne lub czasochłonne dla ludzi do ręcznego wykonania.
Każdy algorytm ML ma swoje mocne i słabe strony, a wybór konkretnego zależy od charakterystyki danych i wymagań zadania. Kluczowe jest dobranie odpowiedniego algorytmu lub ich kombinacji, dla konkretnego problemu, który chcemy rozwiązać.
Ważne jest, aby wybrać odpowiedni rodzaj algorytmu, ponieważ zastosowanie nieodpowiedniego algorytmu może skutkować niską wydajnością i niedokładnymi prognozami. W przypadku wątpliwości, który algorytm zastosować, warto wypróbować zarówno algorytmy regresji jak i klasyfikacji oraz porównać ich efektywność dla danego zbioru danych.
Mam nadzieję, że ten artykuł okazał się pomocny w zrozumieniu różnic między regresją a klasyfikacją w uczeniu maszynowym. Być może zainteresują Cię również informacje na temat najlepszych modeli uczenia maszynowego.
