
Web scraping umożliwia efektywne i bardzo szybkie gromadzenie dużych ilości danych z Internetu i jest szczególnie przydatny w przypadkach, gdy strony internetowe nie udostępniają swoich danych w sposób ustrukturyzowany poprzez wykorzystanie interfejsów programowania aplikacji (API).
Wyobraź sobie na przykład, że tworzysz aplikację porównującą ceny produktów w witrynach handlu elektronicznego. Jak byś się do tego zabrał? Jednym ze sposobów jest ręczne sprawdzenie cen produktów we wszystkich witrynach i zapisanie swoich ustaleń. Nie jest to jednak mądry sposób, ponieważ na platformach handlu elektronicznego znajdują się tysiące produktów, a wyodrębnienie odpowiednich danych zajęłoby całą wieczność.
Lepszym sposobem na osiągnięcie tego jest złomowanie stron internetowych. Skrobanie sieci to proces automatycznego wyodrębniania danych ze stron internetowych i witryn internetowych za pomocą oprogramowania.
Skrypty programowe, zwane skrobakami sieciowymi, służą do uzyskiwania dostępu do witryn internetowych i pobierania z nich danych. Pobrane dane, zwykle w formie nieustrukturyzowanej, można następnie analizować i przechowywać w ustrukturyzowany sposób zrozumiały dla użytkowników.
Skrobanie sieci jest bardzo cenne w ekstrakcji danych, ponieważ zapewnia dostęp do dużej ilości danych i pozwala na automatyzację, dzięki czemu można zaplanować uruchamianie skryptu skrobania sieci w określonym czasie lub w odpowiedzi na określone wyzwalacze. Web scraping pozwala także uzyskać aktualizacje w czasie rzeczywistym i ułatwia prowadzenie badań rynkowych.

Wiele firm i firm korzysta ze skrobania sieci w celu wyodrębnienia danych do analizy. Firmy specjalizujące się w zasobach ludzkich, handlu elektronicznym, finansach, nieruchomościach, podróżach, mediach społecznościowych i badaniach wykorzystują web scraping do wydobywania odpowiednich danych ze stron internetowych.
Sam Google wykorzystuje web scraping do indeksowania witryn w Internecie, dzięki czemu może dostarczać użytkownikom trafne wyniki wyszukiwania.
Należy jednak zachować ostrożność podczas usuwania stron internetowych. Chociaż usuwanie publicznie dostępnych danych nie jest nielegalne, niektóre strony internetowe nie pozwalają na to. Może to być spowodowane tym, że zawierają wrażliwe informacje o użytkowniku, ich warunki świadczenia usług wyraźnie zabraniają usuwania stron internetowych lub chronią własność intelektualną.
Ponadto niektóre witryny internetowe nie pozwalają na skrobanie sieci, ponieważ może to przeciążyć serwer witryny i prowadzić do zwiększonych kosztów przepustowości, zwłaszcza gdy skrobanie sieci odbywa się na dużą skalę.
Aby sprawdzić, czy witrynę można usunąć, dołącz plik robots.txt do adresu URL witryny. Plik robots.txt służy do wskazywania botom, które części witryny mogą zostać pobrane. Na przykład, aby sprawdzić, czy możesz zeskrobać Google, przejdź do google.com/robots.txt
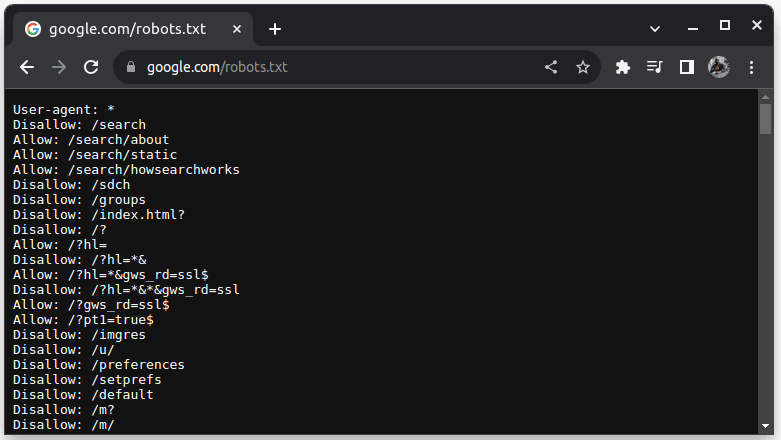
User-agent: * odnosi się do wszystkich botów, skryptów oprogramowania i robotów indeksujących. Disallow służy do informowania botów, że nie mogą uzyskać dostępu do żadnego adresu URL w katalogu, na przykład /search. Zezwalaj wskazuje katalogi, z których można uzyskać dostęp do adresów URL.
Przykładem witryny, która nie pozwala na scrapowanie, jest LinkedIn. Aby sprawdzić, czy możesz zeskrobać LinkedIn, przejdź dolinkedin.com/robots.txt
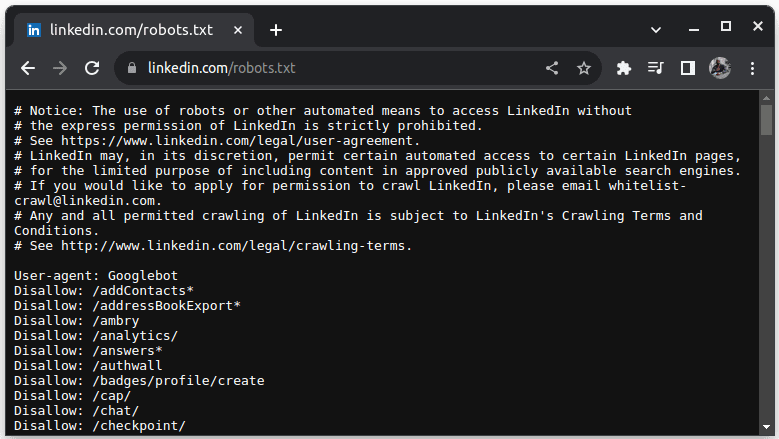
Jak widać, nie wolno Ci scrapować LinkedIn bez ich zgody. Zawsze sprawdzaj, czy witryna umożliwia skrobanie, aby uniknąć problemów prawnych.
Spis treści:
Dlaczego Java jest odpowiednim językiem do skrobania sieci Web
Podczas gdy możesz stworzyć skrobak sieciowy z różnymi językami programowania, Java jest szczególnie idealna do tego zadania z wielu powodów. Po pierwsze, Java ma bogaty ekosystem i dużą społeczność oraz zapewnia różnorodne biblioteki do skrobania sieci, takie jak JSoup, WebMagic i HTMLUnit, które ułatwiają pisanie skrobaków sieciowych.

Udostępnia także biblioteki analizujące HTML, które upraszczają proces wyodrębniania danych z dokumentów HTML i biblioteki sieciowe, takie jak HttpURLConnection, służące do wysyłania żądań do różnych adresów URL witryn internetowych.
Silna obsługa współbieżności i wielowątkowości w Javie jest również korzystna w przypadku scrapowania stron internetowych, ponieważ umożliwia równoległe przetwarzanie i obsługę zadań skrobania sieci z wieloma żądaniami, co pozwala na jednoczesne pobieranie wielu stron. Ponieważ skalowalność jest kluczową zaletą Javy, możesz wygodnie przeglądać strony internetowe na masową skalę, korzystając ze skrobaka sieciowego napisanego w Javie.
Przydatna jest także wieloplatformowa obsługa języka Java, ponieważ umożliwia napisanie skrobaka sieciowego i uruchomienie go w dowolnym systemie wyposażonym w kompatybilną wirtualną maszynę Java. Dlatego możesz napisać skrobak sieciowy w jednym systemie operacyjnym lub urządzeniu i uruchomić go w innym systemie operacyjnym bez konieczności modyfikowania skrobaka sieciowego.
Java może być również używana w przeglądarkach bezgłowych, takich jak między innymi Headless Chrome, HTML Unit, Headless Firefox i PhantomJs. Przeglądarka bezgłowa to przeglądarka bez graficznego interfejsu użytkownika. Przeglądarki bezgłowe mogą symulować interakcje użytkownika i są bardzo przydatne podczas przeglądania stron internetowych wymagających interakcji użytkownika.
Podsumowując, Java jest bardzo popularnym i szeroko używanym językiem, który jest obsługiwany i można go łatwo zintegrować z różnymi narzędziami, takimi jak bazy danych i platformy przetwarzania danych. Jest to korzystne, ponieważ gwarantuje, że podczas skrobania danych wszystkie narzędzia potrzebne do skrobania, przetwarzania i przechowywania danych prawdopodobnie będą obsługiwać język Java.
Zobaczmy, jak możemy wykorzystać Javę do scrapowania stron internetowych.
Java do skrobania sieci Web: wymagania wstępne
Aby używać języka Java do skrobania stron internetowych, należy spełnić następujące wymagania wstępne:
1. Java – powinieneś mieć zainstalowaną Javę, najlepiej najnowszą wersję z długoterminowym wsparciem. Jeśli nie masz zainstalowanej Java, przejdź do instalacji Java, aby dowiedzieć się, jak zainstalować Java na swoim komputerze
2. Zintegrowane środowisko programistyczne (IDE) – powinieneś mieć zainstalowane IDE na swoim komputerze. W tym samouczku użyjemy IntelliJ IDEA, ale możesz użyć dowolnego IDE, które znasz.
3. Maven – będzie używany do zarządzania zależnościami i instalowania biblioteki do skrobania sieci.
Jeśli nie masz zainstalowanego Mavena, możesz go zainstalować, otwierając terminal i wykonując:
sudo apt install maven
Spowoduje to zainstalowanie Mavena z oficjalnego repozytorium. Możesz potwierdzić, że Maven został pomyślnie zainstalowany, wykonując:
mvn -version
Jeśli instalacja przebiegła pomyślnie, powinieneś otrzymać taki wynik:
Konfigurowanie środowiska
Aby skonfigurować środowisko:
1. Otwórz IntelliJ IDEA. Na lewym pasku menu kliknij Projekty, a następnie wybierz Nowy projekt.
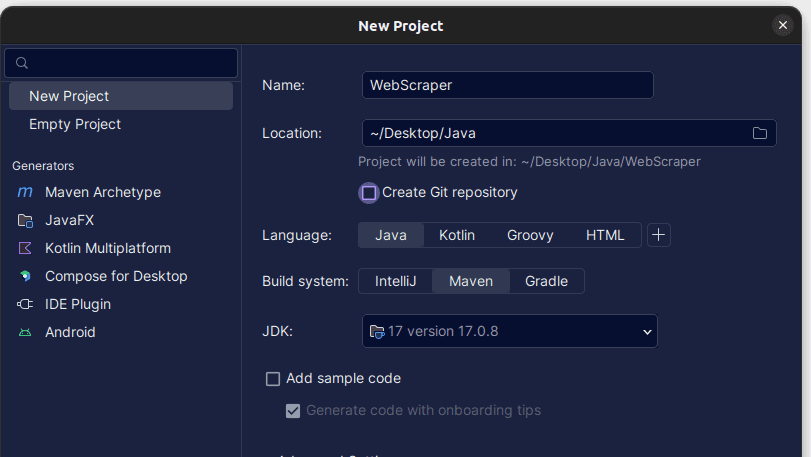
2. W otwartym oknie Nowy projekt wypełnij je w sposób pokazany poniżej. Upewnij się, że język jest ustawiony na Java, a system kompilacji na Maven. Możesz nadać projektowi dowolną nazwę, a następnie użyć opcji Lokalizacja, aby określić folder, w którym chcesz utworzyć projekt. Po zakończeniu kliknij Utwórz.
3. Po utworzeniu projektu powinieneś mieć w swoim projekcie plik pom.xml, jak pokazano poniżej.
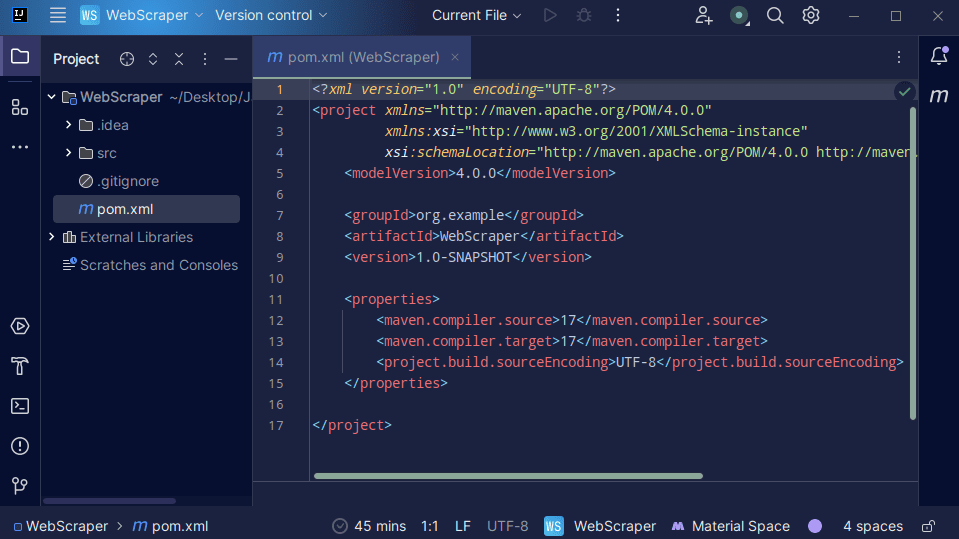
Plik pom.xml jest tworzony przez Mavena i zawiera informacje o projekcie oraz szczegóły konfiguracji użyte przez Mavena do zbudowania projektu. To właśnie tego pliku używamy również do wskazania, że będziemy korzystać z bibliotek zewnętrznych.
Budując skrobak sieciowy, będziemy korzystać z biblioteki jsoup. Musimy zatem dodać go jako zależność w pliku pom.xml, aby Maven mógł go udostępnić w naszym projekcie.
4. Dodaj zależność jsoup w pliku pom.xml, kopiując poniższy kod i dodając go do swojego pliku pom.xml
<dependencies>
<!-- https://mvnrepository.com/artifact/org.jsoup/jsoup -->
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.16.1</version>
</dependency>
</dependencies>
Wynik powinien wyglądać jak pokazano poniżej:
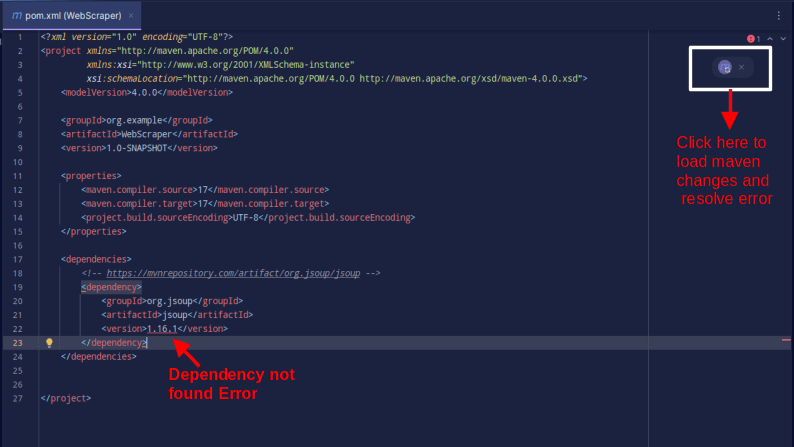
W przypadku napotkania błędu informującego, że nie można znaleźć zależności, kliknij wskazaną ikonę, aby Maven wczytał wprowadzone zmiany, załadował zależność i usunie błąd.
Dzięki temu Twoje środowisko jest w pełni skonfigurowane.
Skrobanie sieci przy użyciu języka Java
W przypadku skrobania sieciowego będziemy pobierać dane z ScrapeThisSitektóry zapewnia piaskownicę, w której programiści mogą ćwiczyć skrobanie sieci bez narażania się na problemy prawne.
Aby zeskrobać witrynę internetową za pomocą języka Java
1. Na lewym pasku menu IntelliJ otwórz katalog src, a następnie katalog główny, który znajduje się w katalogu src. Główny katalog zawiera katalog o nazwie Java; kliknij go prawym przyciskiem myszy i wybierz Nowy, a następnie Klasa Java
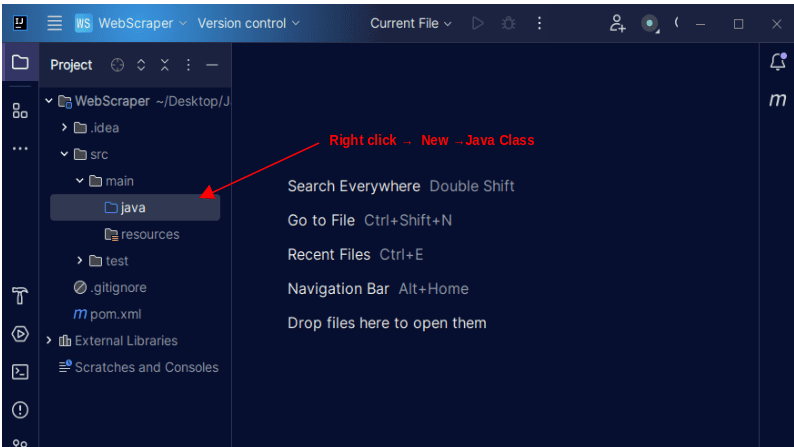
Nadaj klasie dowolną nazwę, na przykład WebScraper, a następnie naciśnij klawisz Enter, aby utworzyć nową klasę Java.
Otwórz nowo utworzony plik zawierający właśnie utworzone klasy Java.
2. Web scraping polega na pobieraniu danych ze stron internetowych. Dlatego musimy określić adres URL, z którego chcemy pobrać dane. Po określeniu adresu URL musimy połączyć się z adresem URL i wykonać żądanie GET w celu pobrania zawartości HTML strony.
Kod, który to robi, pokazano poniżej:
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import java.io.IOException;
public class WebScraper {
public static void main(String[] args) {
String url = "https://www.scrapethissite.com/pages/simple/";
try {
Document doc = Jsoup.connect(url).get();
System.out.println(doc);
} catch (IOException e) {
System.out.println("An IOException occurred. Please try again.");
}
}
}
Wyjście:
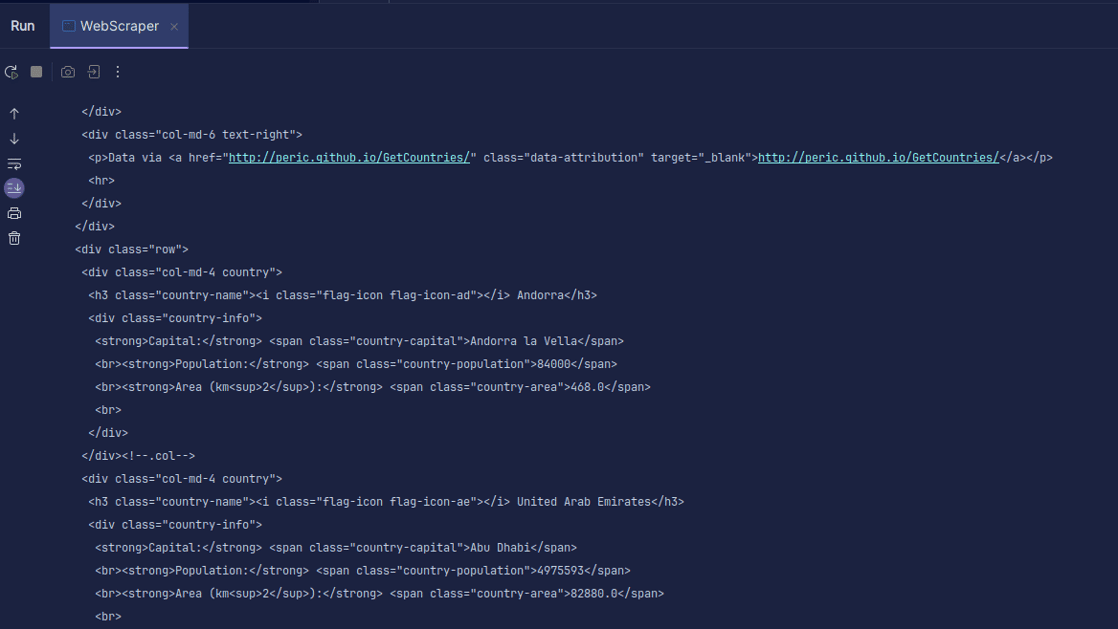
Jak widać, zwracany jest kod HTML strony i to właśnie go drukujemy. Podczas skrobania podany adres URL może zawierać błąd, a zasób, który próbujesz zeskrobać, może w ogóle nie istnieć. Dlatego ważne jest, aby zawinąć nasz kod w instrukcję try-catch.
Linia:
Document doc = Jsoup.connect(url).get();
Służy do łączenia się z adresem URL, który chcesz zeskrobać. Metoda get() służy do wysyłania żądania GET i pobierania kodu HTML ze strony. Zwrócony wynik jest następnie przechowywany w obiekcie dokumentu JSOUP o nazwie doc. Przechowywanie wyniku w dokumencie JSOUP umożliwia użycie interfejsu API JSOUP do manipulowania zwróconym kodem HTML.
3. Przejdź do ScrapeThisSite i sprawdź stronę. W kodzie HTML powinieneś zobaczyć strukturę pokazaną poniżej:
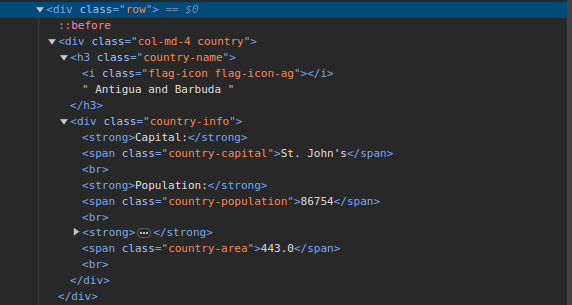
Zwróć uwagę, że wszystkie kraje na stronie są przechowywane w podobnej strukturze. Istnieje element div z klasą o nazwie country z elementem h3 z klasą country-name zawierającą nazwę każdego kraju na stronie.
Wewnątrz głównego elementu div znajduje się kolejny element div z klasą informacji o kraju, zawierający informacje takie jak stolica, populacja i powierzchnia kraju. Możemy używać tych nazw klas do wybierania elementów HTML i wydobywania z nich informacji.
4. Wyodrębnij określoną treść z kodu HTML na stronie, używając następujących wierszy:
Elements countries = doc.select(".country");
for (Element country : countries) {
String countryName = country.select(".country-name").text();
String capitalCity = country.select(".country-capital").text();
String population = country.select(".country-population").text();
System.out.println(countryName + " - " + capitalCity + " Population - " + population);
}
Używamy metodyselect() do wybierania elementów z kodu HTML strony, które pasują do konkretnego selektora CSS, który przekazujemy. W naszym przypadku przekazujemy nazwy klas. Sprawdzając stronę, zauważyliśmy, że wszystkie informacje o kraju na stronie są przechowywane w elemencie div z klasą kraju.
Każdy kraj ma swój własny div z klasą kraju, który zawiera takie informacje, jak nazwa kraju, stolica i populacja.
Dlatego najpierw wybieramy wszystkie kraje na stronie za pomocą klasy .country. Następnie przechowujemy to w zmiennej o nazwie kraje typu Elementy, która działa podobnie jak lista. Następnie używamy pętli for, aby przejść przez kraje, wyodrębnić nazwę kraju, stolicę i populację, a następnie wydrukować znalezione informacje.
Cała nasza baza kodu jest pokazana poniżej:
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.select.Elements;
import org.jsoup.nodes.Element;
import java.io.IOException;
public class WebScraper {
public static void main(String[] args) {
String url = "https://www.scrapethissite.com/pages/simple/";
try {
Document doc = Jsoup.connect(url).get();
Elements countries = doc.select(".country");
for (Element country : countries) {
String countryName = country.select(".country-name").text();
String capitalCity = country.select(".country-capital").text();
String population = country.select(".country-population").text();
System.out.println(countryName + " - " + capitalCity + " - Population - " + population);
}
} catch (IOException e) {
System.out.println("An IOException occurred. Please try again.");
}
}
}
Wyjście:
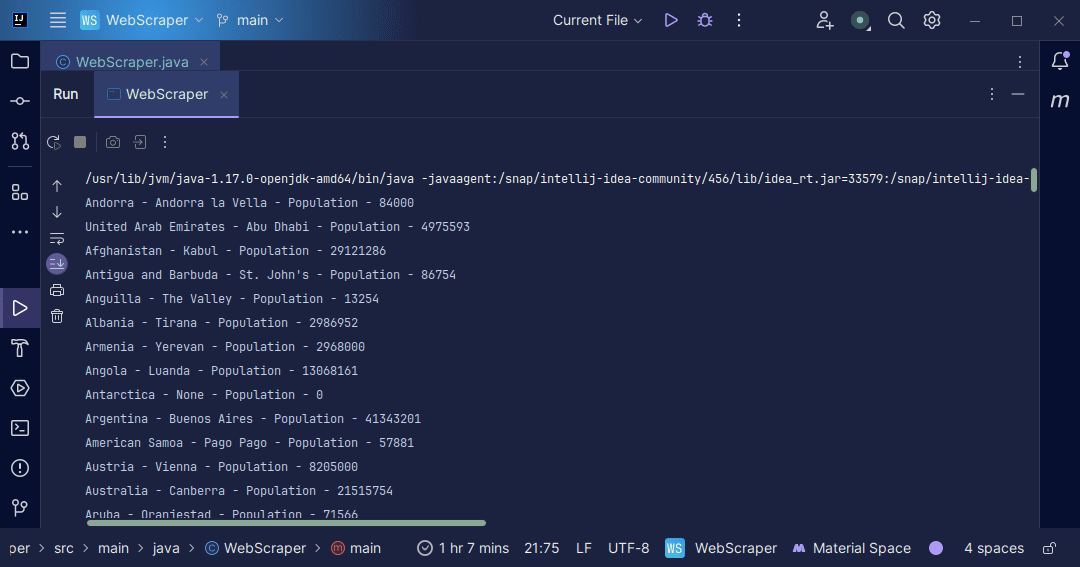
Dzięki informacjom, które otrzymamy ze strony, możemy zrobić różne rzeczy, na przykład wydrukować je tak, jak to zrobiliśmy lub zapisać w pliku na wypadek, gdybyśmy chcieli dalej przetwarzać dane.
Wniosek
Skrobanie sieci to doskonały sposób na wyodrębnianie nieustrukturyzowanych danych ze stron internetowych, przechowywanie danych w ustrukturyzowany sposób i przetwarzanie danych w celu wydobycia znaczących informacji. Jednakże ważne jest, aby zachować ostrożność podczas skrobania sieci, ponieważ niektóre witryny internetowe nie pozwalają na skrobanie sieci.
Aby zachować bezpieczeństwo, korzystaj ze stron internetowych udostępniających piaskownice do ćwiczeń złomowania. W przeciwnym razie zawsze sprawdzaj plik robots.txt każdej witryny, którą chcesz zeskrobać, aby dowiedzieć się, czy witryna umożliwia złomowanie.
podczas pisania skrobaka sieciowego Java jest doskonałym językiem, ponieważ udostępnia biblioteki, dzięki którym skrobanie sieci jest łatwiejsze i wydajniejsze. Jako programista Java zbudowanie skrobaka sieciowego pomoże Ci jeszcze bardziej rozwinąć umiejętności programowania. Zatem napisz własny skrobak sieciowy lub zmodyfikuj ten użyty w artykule, aby wyodrębnić różne rodzaje informacji. Miłego kodowania!
Możesz także zapoznać się z niektórymi popularnymi rozwiązaniami do skrobania stron internetowych w chmurze.